[Technology Toolkit]
Smart QA Model That Understands Even Complex Tables


Technology Toolkit 2021 is a technical white paper describing core technologies that
are being researched and developed by Samsung SDS R&D Center. We would like to introduce in this paper a total of
seven technologies concerning AI, Blockchain, Cloud, and Security with details on their technical definition, key
features, differentiating points, and use cases to give our readers some insights into our work.
Machine Reading Comprehension-based QA
1. Introduction to Technology
Technology Trends and Background
With COVID 19 pandemic driving the need for digital workplace, it is becoming more important to integrate into one
system information of various quantity and quality scattered across company and to search for right information for
timely insights. In response to these demands, there is a growing interest in Question Answering (QA) system that is
adept at smartly answering users’ questions with respect to a large volume of documents. This is a reason why
the need has emerged for natural language processing and natural language understanding technology such as machine
reading comprehension and semantic search that are associated with finding the right information quickly and
accurately.
Among them, research on MRC-based question answering system has been actively carried out to date since the release of
SQuAD (Stanford Question Answering Dataset) in 2016. Over the course of time, starting with BERT, multiple number of
language models and various benchmark data were made released, with some of them delivering performance that exceed
human performance. One of the major achievements accomplished with the advancement in MRC technology lies in the
ability to “comprehend” questions and target documents and thus provide correct answers. This is a step
forward from simply providing “search” result based on keyword matching. Moreover, research has been
expanded to bring forth a technology adept at providing desired answer more accurately through “reasoning”
process, going beyond of just “understanding” target documents.
Various sectors including Chatbot and search engine call for advanced QA technology and these market needs are further
accelerating research on MRC-based QA system. We intend to provide high-quality QA service by continuing to secure and
incorporate cutting-edge technologies into our service.
Definition
MRC-based QA is a technology that enables machines to understand and automatically answer questions presented in
natural language as well as contents of target documents. SQuAD, a representative Question Answering Dataset, has
already surpassed the level of human capacity in January 2018.
Recently, research and development have been underway with the aim (open domain QA) of improving the system to find
answers from a whole array of documents without specifying target documents. With traditional QA systems, it is
difficult to provide realistic service as they provide answers only if target documents are specified along with
questions. In order to overcome the limitations of existing QA systems, we have developed and are using a technology
that can automatically find target documents. We will take a brief look at our multi-hop QA technology, a technology
that enables machines to go beyond reading comprehension but provide reasoning as well. We will also explain what MRC
technology is in general.
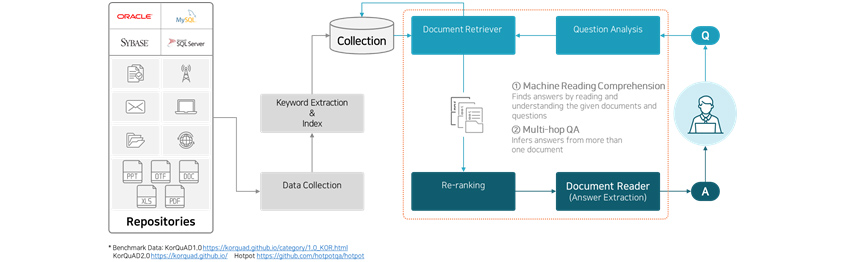 With traditional QA systems, it is difficult to provide realistic service as they provide answers only
if target documents are specified along with questions[Figure 1] MRC-based QA System
Architecture
With traditional QA systems, it is difficult to provide realistic service as they provide answers only
if target documents are specified along with questions[Figure 1] MRC-based QA System
Architecture① Machine Reading Comprehension
Machine Reading Comprehension (MRC) is a technology that allows machines to understand and automatically answer
questions that humans ask in natural language as well as the contents of given target documents. Aforementioned SQuAD
and KorQuAD are two representative benchmark dataset that are related to machine reading comprehension. SQuAD is a
dataset that was designed to collect target questions by crowd sourcing English Wikipedia articles and have the right
answers be made available in the specific parts of corresponding pages. KorQuAD is similar to SQuAD. It is a dataset
created by crowd sourcing Korean Wikipedia articles. Notably, KorQuAD 2.0 model is quite significant in that it allows
machines to find answers from HTML documents containing tables or lists.
In order for machines to read and understand documents well, they must be adept at using semantic information, which
is understanding the meaning of words or the context of documents. This is called Semantic Search where machines use
semantic information of sentences or documents by encoding them into dense matrix using elements such as a language
model. This semantic search is beneficial in that it allows machines to conduct search even when there is insufficient
keyword matching, but it lacks in its ability to produce quick search result. Presently, there is a flourish of
research activities taking place to address this speed issue. Since the deployment of FAISS (Facebook AI Similarity
Search) by Facebook in 2018, there has been a continuous release of new models that are up to par to be used to solve
actual problems.
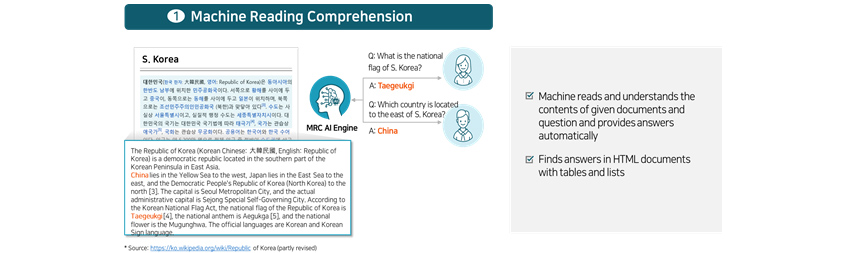
- A technology that allows machines to understand and automatically answer questions that humans ask in natural language as well as the contents of given target documents
- Machine reads and understands the contents of given documents and question and provides answers automatically
- Finds answers in HTML documents with tables and lists.
② Multi-Hop Question Answering Technology
Multi-Hop question answering is a technology that enables machines to answer questions by referring to more than one
document. One of the key features of technology lies in its ability to sift through innumerable documents and find the
right ones needed to answer given questions and for this, it is actively using knowledge base. Knowledge base refers
to a database that extracts knowledge from data in advance and stores it in a format that is easy to use. The most
representative knowledge base is the knowledge graph used by Google. Many knowledge bases, including knowledge graph,
use graph database. Data with additional knowledge including their relations information can be stored and managed
efficiently with the use of this graph database.
We have developed and deployed 1) a technology that extracts knowledge from documents and builds/manages the knowledge
in knowledge base format suitable for multi-hop Q&A system and 2) a technology that actually executes multi-hop
Q&A system using this knowledge base. We are also using diverse technologies such as Named Entity Recognition,
Relation Extraction, Graph Completion, Graph Neural Network, and Document Retrieval.
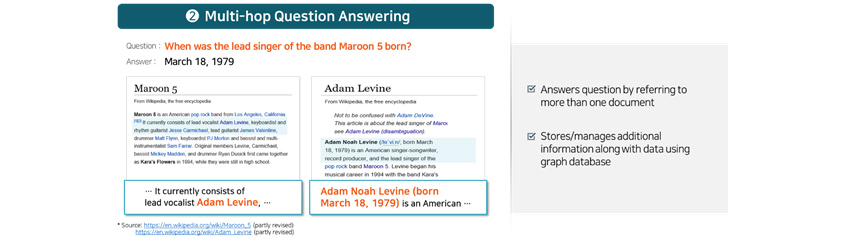
- Multi-Hop Question answering
- question : When was the lead singer of band Maroon 5 born?
- Answer : March 18, 1979 Maroon5
- … It currently consists of lead vocalist Adam Levine, … Adam Levine Adam Noah Levine (born March 18, 1979) is an American …
- A technology that enables machines to answer questions by referring to more than one document. One of the key features of technology lies in its ability to sift through innumerable documents and find the right ones needed to answer given questions and for this
- Answers question by reffering to more than one document
- Stores/manages additional information along with data using graph database
2. Key Features
Our MRC-based QA system provides answers to various kinds of inquiries using the best MRC technology available at
home and abroad.
QA that understands tables and lists
Our MRC technology is applicable even when documents contain tables or lists. It is often the case that documents
come with tables or lists in addition to pure text and therefore QA system handling documents of various types must be
adept at finding the desired information from tables and lists as well. Our MRC technology is adept at finding
necessary information available in various format by learning tables and lists as well as natural language.
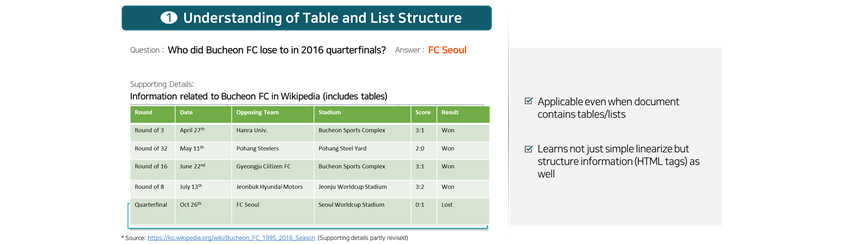
- question : who did bucheon FC lose to in 2016 quarterfinals?
- answer : FC Seoul
- Supporting details: Information related to Bucheon FC in wikipedia [includes tables]
-
- applicable even when document contains tables/lists
- learns not just simple linearize but structure information (HTML tags) as well
QA that can provide lengthy answers
Sometimes, a question and answering system may not be equipped to handle short-answer questions depending on the
types of given questions. A typical example of this would be where general description of a particular subject or
description about the process is required. Our MRC-based QA system can handle questions requiring answers of various
lengths with flexibility using technologies that understand long sentences and provide lengthy answer.

- Questoin: what are the symptoms of macular degeneration?
- Answer: If you suspect macular degeneration, it's important to cover one eye at a time and do a test. In additoin, the macula is highly efficient, so most of its functions remain intact even slightly damaged, its surroundings performs functions on its behalf. So, most of the initial symptoms people complain of are such as "I can't see the middle" or "It looks bent in the middle."
- Supportings: Most people suffering from macular degeneration can't express the symptoms clearly like "I can't see the middle." even though they are feeling uncomfortable and can't see clearly. If you suspect macular degeneration, it's important to coever one eye at a time and do a test. In addition, the macula is highly effecient, so most of its function remain intact even where slightly damaged ........
- Handles with flexibility questions requiring answer of varing lengths using technology that is adept at understanding long texts and providing lengthy answers
QA that can make an inference by referring to more than one document
Some questions must refer to more than one document in order find answers. Our QA system provides an answer
that’s based on multiple documents using multi-hop QA technology that searches and links multiple documents that
could support the answer.
Users would find it difficult to trust answers if they are provided without any supporting texts but not so with our
multi-hop QA system. Our solution provides supporting sentences or paragraphs along with the answers thereby providing
users with a reliable QA experience. This allows them to obtain background knowledge in addition to the answers and so
even when wrong answers are provided by the system, they can, with the help of supporting knowledge provided alongside
the answers, see why such wrong answers were provided. As a result, they can place more trust in the given
answers.
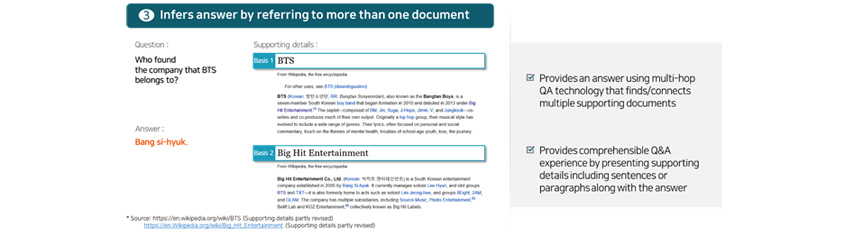
- Question: Who found the company that BTS belongs to?
- Answer : Bang si-hyuk.
- Supporting details: Basis 1: BTS ... descriptions... Basis 2: Big Hit Entertainment ...descriptions...
3. Differentiating Points
We offer the best MRC-based QA technology both at home and abroad. We go beyond the limits of existing MRC-based QA
technologies that are only capable of retrieving short answers from documents written in natural language. With our
MRC-based QA technology, we have secured technological prowess that enables machines to understand tables/lists,
provide extended answers, and respond to questions targeting multiple documents.
This has helped us establish a technological superiority over our competitors in a number of domestic and
international competitions. Our technology boasts excellence in both English and Korean language as proven in HotPotQA
(English data) and KorQuAD 1.0 and KorQuAD 2.0 (Korean data) competition. In particular, our model for KorQuAD 2.0
competition was the very first one to surpass human capacity, and it was meaningful in that the answers were
retrievable from HTML documents containing tables and lists. We won the first place with our MRC-based technology in
both KorQuAD2.0 (April 2020) and HotPotQA competition (January 6th 2021).
4. Use Cases
Case 1: Virtual Consultant
MRC-based QA technology can be used to provide appropriate answers even when the questions are different from the
ones in pre-determined conversation scenarios of virtual consultant like a chatbot.
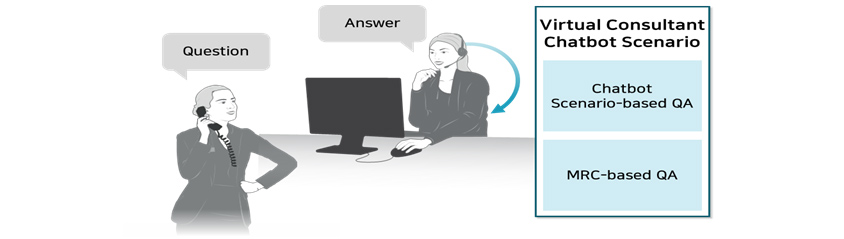 Virtual Consultant :
MRC-based QA technology can be used to provide appropriate answers even when the questions are different from the
ones in pre-determined conversation scenarios of virtual consultant like a chatbot.[Figure 7] Virtual Consultant Scenario
Virtual Consultant :
MRC-based QA technology can be used to provide appropriate answers even when the questions are different from the
ones in pre-determined conversation scenarios of virtual consultant like a chatbot.[Figure 7] Virtual Consultant Scenario
Case 2: Monitoring System
MRC-based technology can be used in systems that monitor diseases, approval ratings, and specific technology trends.
It can make information gathering and analysis process more efficient, and also increase confidence in the result.
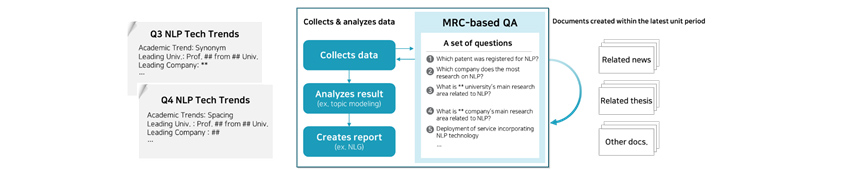 Monitoring System : MRC-based technology can be used in systems that monitor diseases, approval
ratings, and specific technology trends. It can make information gathering and analysis process more efficient, and
also increase confidence in the result. [Figure 8] Monitoring System
Scenario
Monitoring System : MRC-based technology can be used in systems that monitor diseases, approval
ratings, and specific technology trends. It can make information gathering and analysis process more efficient, and
also increase confidence in the result. [Figure 8] Monitoring System
Scenario5. Business Cases
Further improvements were made on the above use cases and right now, plans are being made to deploy them in actual
business environment. Plans are already underway to provide MRC-based QA service for our in-house Knowledge Management
System. We expect this will help us save both time and money spent on searching the right information by correctly
understanding inquires, which in turn, will increase use of our internal information portal system and boost our work
efficiency. In particular, we will actively use the technology to handle complex documents containing tables/lists. We
are also devising a plan to build an intelligent search system that can search information in manners that are both
smart and fast and also retrieve answers from multiple complex documents through integration of in-house online
bulletin boards, news portal sites, developer portal sites of various sorts.
 [Figure 9] Applying MRC_basd QA service to knowledge management
[Figure 9] Applying MRC_basd QA service to knowledge managementWe are in the process of upgrading our customers’ integrated search service – it involves improving
indexing of new data and system and enhancing document analysis-based search function. We expect these new changes
will lead to greater customer satisfaction with search results.
6. Closing
The advancement in machine reading comprehension technology has led to QA service that allows machines to answer
questions smartly without having users specify target documents or enter questions using exact keywords included in
the documents. In other words, this is a technology that makes truly interactive artificial intelligence service
possible, a service that goes beyond simple search. Recently, with non-face-to-face work becoming a commonplace,
financial industry including insurance and banks is deploying chatbot or QA system with eagerness, and service sector
such as hotels is introducing non-face-to-face help desks into their environment. In this respect, the need for
MRC-based QA technology will become greater going forward.
There are still some issues that must to be addressed moving forward. For example, one of the drawbacks of currently
available QA service is that when faced with no information being available in the given documents, it is incapable of
stating that very fact (with “no answer available”) and gives wrong answers instead. The resolving of this
issue will no doubt lead to significant improvement in users’ search experiences and also minimize time spent on
manually improving service performance by developers. We expect to provide users with new search experience where they
can move freely amongst information or services by having multiple interrelated services share a single knowledge
graph. Moreover we are currently working to develop multilingual version for our off-domain QA system and for
expansion to overseas market. We will tackle the issues one at a time and use our proven technical prowess as a ground
to build more quality services going forward. We ask you for your continuous support and interest in our work.

# References
[1] https://korquad.github.io/category/1.0_KOR.html (KorQuAD1.0)
[2] https://korquad.github.io/ (
KorQuAD2.0)
[3] https://github.com/hotpotqa/hotpot (Hotpot)
▶ The content is proected by law and the copyright belongs to the author.
▶ The content is prohibited to copy or quote without the author's permission.
- The First Step to Smart Textual Analysis, KoreALBERT
- Smart QA Model That Understands Even Complex Tables
- I Will Give You Data, Label It~ Auto Labeling!
- The Connecting Link for Everything in the World, It’s in the Knowledge Graph
- Easy and Simple Blockchain Management, Nexledger!
- No More Short of GPU!
- In the Age of When Customer Data Must Be Treated as a King, PET Will Take on the Responsibility
- It is Important to Prevent Security Risks from Development Phase! Trust CAFA+ to Do the Job

Soonhwan KWON, ML Research Team at Samsung SDS R&D Center
He is involved in research & development of deep-learning based open domain question answering system using his experience and expertise in NLP and deep learning.
Seunghyun SHIN, ML Research Team at Samsung SDS R&D Center
He is involved in AI research & development. His main interest is in NLP technology.
Minyoung LEE, ML Research Team at Samsung SDS R&D Center
As Principal Data Scientist for ML Research Team, she is leading the work on Question Answering technology development.
If you have any inquiries, comments, or ideas for improvement concerning technologies introduced in Technology Toolkit 2021, please contact us at techtoolkit@samsung.com.
- AI Ethics and AI Governance - The Social Responsibility of AI
- Multimodal AI That Thinks Like Humans
- Damages of Media Forgery and Companies that Offer Forgery Prevention Technologies
- Brightics Visual Search Claims 6th Place in NIST FRVT “Face Mask Effects” Category
- Cheapfakes on the Rise in Zero Contact Environments
- Is the Media You Are Watching "Real"?