[Technology Toolkit]
In the Age of When Customer Data Must Be Treated as a King, PET Will Take on the Responsibility


Technology Toolkit 2021 is a technical white paper describing core technologies that
are being researched and developed by Samsung SDS R&D Center. We would like to introduce in this paper a total of
seven technologies concerning AI, Blockchain, Cloud, and Security with details on their technical definition, key
features, differentiating points, and use cases to give our readers some insights into our work.
Privacy Enhancing Technology
1. Introduction to Technology
Technology Trends and Background
In a world that revolves around data, protecting one’s privacy, and by extension the data itself, is becoming
not an option but a necessity. In response to this trend, global laws/regulations such as Personal Information
Protection Act (Korea), GDPR (EU), and CCPA (USA, California) have been modified to beef up privacy protection, and a
new market is emerging that supports data utilization in privacy-protected environment.
Privacy protection technology, commonly referred to as de-identification or anonymization technology, has been
implemented using relatively intuitive methods such as identifier removal and generalization. However, the latest
law/regulation reinforcement and increased requirements concerning data utilization have led to more theoretical and
quantifiable technologies fitted with cryptographic function and a number of international standards have been
proposed pertaining to the matter.[1]
In this paper, we will give you an overview of encryption-based privacy enhancing technology, a technology that is
being actively adopted by global companies such as Google, Microsoft, IBM, Intel, and Ant Financial and numerous
startups for sectors like finance, healthcare, and marketing. We hope to use our technology to help companies as well
as individuals to protect their private information.

- Data = Money
- We can Create high-added values using data. However, there is a threat of personal information exposure.
- Privacy-related Laws/Regulation
- CAlifornia Consumer Privac act Logo, PIPEDA Logo
- GDPR(General Data Protection Regulation)
- Privacy Protection-oriented Business
- Use Privacy protection technology to seek new business to deal with new security threats and Policy
- Logos: Micorsoft, Google, SAP, Intel, inpher, Alibaba Group, Duolify
Definition
PET is an encryption-based privacy enhancing technology that defeated the limitations of existing technologies such
as re-identification risk and analytical value degradation. Traditionally, cryptographic technologies have been
applied to areas such as data encryption, digital signatures, and safe cryptographic protocols to protect corporate
security rather than individual privacy. However, following changes led by the age of 4th industrial revolution, 5G,
and data-driven technology, the encryption-based anonymization technology - theoretically researched for more than 10
years – has come under spotlight for its business potentiality.
Representative technologies include 1) homomorphic encryption technology that enables computation in encrypted state,
2) differential privacy technology that can quantify the level of privacy, and 3) synthetic data generation technology
that can create fake data with statistical and probabilistic characteristics that are similar to the original one.
Needless to say, it takes time to assimilate these technologies but for the sake of this paper, here we will take a
brief look into these three different technologies in terms of their definition and main features.

- Limitations of existing de-identification technology
- 'We need technologies that can preserve data value and privacy at the same time'
- Key De-identification Technologies
- 1. Pesudonymization - Hashing
- 2. Generalization - Rounding
- 3. Randomization - Noise Addition
- 4. Advanced tools' - Homomorphic Encryption - Synthetic Data/Differential Privacy
① HE: Homomorphic Encryption
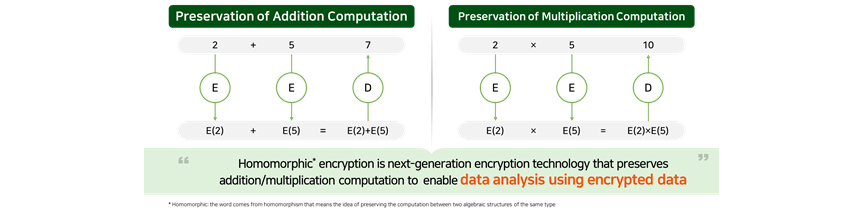
Homomorphic encryption is an encryption technology that supports data analysis in an encrypted state. For example, as
shown in [Figure 3], each ciphertext that homomorphically encrypted 2 and 5 is seen as a random number and if you
either add or multiply these numbers and decrypt the result, you will get 7(=2+5) or 10(=2x5). Now if you apply a
general encryption technology such as AES, you would get a completely different value when the computation result of
ciphertext is decrypted, whereas with homomorphic encryption, you would get a computation result that’s exactly
the same as that of original data.
- 2 + 5 = 7
- e + e = D
- E(2) + E(5) = E(2)+E(5)
- 2 * 5 = 7
- e * e = D
- E(2) * E(5) = E(2)*E(5)
Some of homomorphic encryption technology attributes can be found among the cryptographic technologies that are
currently in use. Even in the 70s, there were partially homomorphic encryption technologies available that supported
either multiplication or addition computation - such as RSA ciphers widely used in areas such as public certificates
and HTTPS, or the international standard Paillier ciphers.
Fully homomorphic encryption technology preserving both addition and multiplication computation was first proposed by
IBM researcher Gentry in 2009 and since then, active research has been carried out to date. Fully homomorphic
encryption preserves both addition and multiplication computation, allowing you to preserve computations of all
functions that are to be applied to data analysis, machine learning and AI analysis.[2]
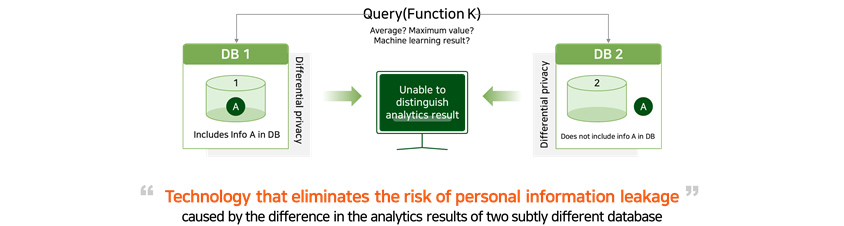
② DP: Differential Privacy
Let's say you are making a query in a database. In this particular situation, if there is a significant difference in
the responses between when the database contains person A’s private information and when it is not, there is a
risk of exposing his/her privacy. For example, if you are making a query on average annual salary in a database
containing annual salary information, and no measures are taken to protect one’s privacy, you will be able to
work out person A’s exact annual salary by accounting for value difference between when his/her personal
information is included in the database and when it is not. This is where differential privacy protection technology
can demonstrate its merit with its ability to mix in the right distribution of noises into response to prevent you
from computing person A’s annual salary.
Average? Maximum Valju? Machine learning result?
Differental privacy- DB 1
- A in 1
- Includes info A in DB
- DB 2
- A out 1
- Does not include info a in DB
caused by the difference in the analytics results of two subtly different database
This technology, first took its concrete form by Microsoft researcher Dwork in 2006. It offers a great technical
advantage in that it can measure in numeric numbers how much data processing results are damaged (error radius) and
how much privacy can be protected. Following recent announcement by Google and Apple of using differential privacy
technology for their respective Chrome Browser and iPhone/iCloud/Uber in the course of promoting their privacy
protection level, this differential privacy technology has been attracting a lot of attention.
③ SD: Synthetic Data
Synthetic data adopts a de-identification method that creates fake data (virtual data) so that data can be safely
analyzed and utilized without compromising the security of personal information contained in original data. This is
similar to Deep Fake where realistic fake videos are created using artificial intelligence to compose and manipulate
videos/photos.
Research on synthetic data first took off in 1981 when professor Rubin from Statistics Department at Harvard
University adopted synthetic data as a means to substitute missing values like in surveys. The research has since been
expanded to include fully synthetic data (all public data is fake data), partially synthetic data (only some
information in public data is fake data) and complex synthetic data (data newly created using partially synthetic
data).
Methods for creating synthetic data include traditional statistical method, machine learning model (GAN: Generative
Adversarial Networks) application method, and differential privacy protection application method for fake data privacy
assurance.

- Actual Data
- Q: What is the real data?
- Discriminatior
- Answer
- Feedback
- imitation Data
- Generator
- NIST Logo
- Differential Privacy Synthetic Data Challenge
Security can be enhanced with differential privacy techonlogy and holomorphic encryption technology
[Figure 5] Synthetic Data2. Key Features
PET provides multiple connecting functions to ensure privacy protection using the world's best homomorphic
encryption, differential privacy protection and synthetic data technology.
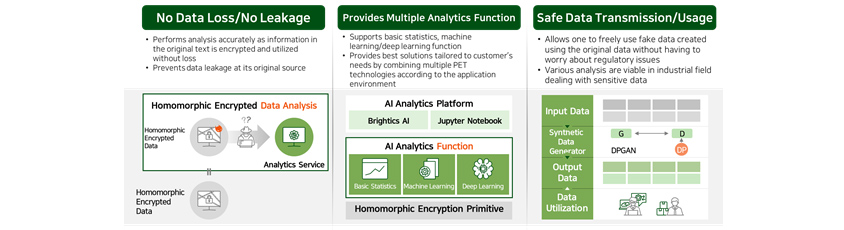
No data loss and no data leakage
Existing de-identification technologies modify original text data to avoid exposure of personal information, however
they lose meaningful data in the process. In addition, because data are morphed according to the objectives of
analysis, it makes it difficult to use the data for other analytical purposes. However, because homomorphic encryption
technology encrypts and utilizes the original data without losing them, it allows more accurate analysis and prevents
original data from being leaked at its source.
Basic statistical/machine learning/deep learning functions
Homomorphic encryption technology supports basic statistical function as well as various machine learning training
& inference function and deep learning inference function. In particular, it can provide an optimal solution
suitable to the needs of our customers by incorporating various PET technologies depending on application
environment.
Safe data transmission to other organizations and their utilization
Synthetic data is an imitation data created using the original data from data holder, and it can be used freely
without restrictions of privacy protection laws and regulations. In particular, for researchers and developers who
have had difficulty collecting data due to security measures imposed by data holder, synthetic data can provide them
with means to explore and learn data and develop analysis functions needed. The technology will provide developers
with an opportunity to implement analytics solutions in real situations for sectors like finance, healthcare and
security industry that handle sensitive data and acquire know-hows over the course of time.
- No Data Loss/No Leakage
- Performs analysis accurately as information in the original text is encrypted and utilized without lass
- Prevents data leakage at its original source
Homomorphic Encrypted Data, Analytics Service, Homomorphic Encrypted Data
- Provides Multiple Analytics Function
- Supports basic statistics, machine learning/deep learning function
- Providers best solutions tllored to customor's need by combining multiple PET techonologies according to the application environment
- AI Analytics Platform
- Brightics Ai
- Jupyter Notebook
- AI Analytics Function
- Basic Solution
- machine learning
- deep learning
- Safe Data Transmission/ Usage
- Allows on to freely use fake data created using the original data without having to worry about regulatory issues
- Various analysis are viable in industrial field dealing with sensitive data
- Input Data
- Synthetic Data Generatior
- Output Data
- Data Ultilizaiton
3. Differentiating Points
Our homomorphic encryption technology is the world-best. We secured and refined original PET technology recognized at
top-tier conferences like Eurocrypt'18 and Asicrypt'19, and we used this enhanced technology to win iDash, an
international Encrypted Analysis Support Competition in 2020.[3] And since then, our technology has been
refined further as proven at AAA’19 where our analysis result yielded 10 times faster analysis speed and same
accuracy compared to the cutting-edge machine learning training. Our PET technology offers the world's best efficiency
with its optimal approximate computation and concurrent processing of tens of thousands of data and it yields over
99.99% consistency in analysis result compared to the original data.

- Collaboration w/ Seoul National University Crypto Lab
- Verified by academic world - presented at top-tier academic conferencess including Eurocrypt '18, Asiacrypt '17
- Encrypted analytics techonlogy verified by int'l competitions - Won'17 iDash - After 2018, all iDASH qualifiers used Seoul Uni's technology
- Proprietary Technologiey enhancment and External Verification Status(2020)
- Provides same accuradcy and 10 times + analytics speed compared to cutting-edge ML trainig (AAA'19)
- Our encrypted Analytics Technology was verified and recognized by and international competition targeting Proprietary technologies - Won '20 iDASH
4. Use Cases
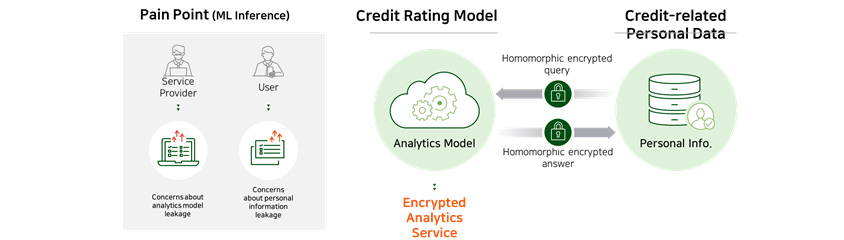
Case 1 : Homomorphic encryption-based predictive service
When an institution (data holder) wants to use high-performance analysis model owned by another institution (service
provider), the service provider in possession of the model may not be very forthcoming with sharing their model, given
that it is their important asset. In addition, the data holder is prevented from transferring their data outside their
premises due to privacy reason. This is where our homomorphic encryption technology can be useful as it can provide a
predictive service that can keep the analysis model from leaking whilst protecting customer data.
- Service Provider
- Concerns about analytics model leakage
- User
- Concerns about personal information leakage
- Analytics Model
- Encrypted Analytics Service
- Personal Info
Case 2 : creating synthetic data capable of controlling privacy protection level
When using data containing sensitive personal information such as financial transaction and medical records,
pseudonymization is required to prevent leakage. Here, deep learning-based synthetic data technology can be used to
obtain meaningful analysis result from pseudonym information created by training on specific features of the original
data. In addition, differential privacy protection technology can be used to control the level of protection when
generating synthetic data.
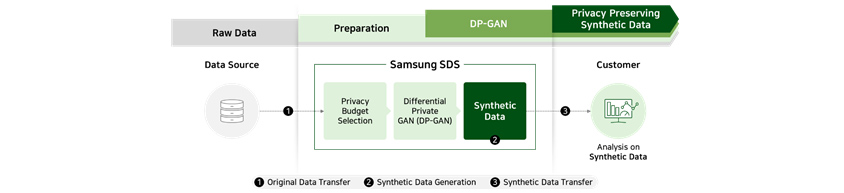
5. Business Cases
Now let’s take a look at some of the cases where we adopted PET in actual business.[4]
Credit rating analysis for financial sector
Technology verification was conducted to test our PET technology for its ability to predict credit rating using
actual customer data held by domestic financial companies. The data was provided to service provider in their
encrypted state, so the personal information of customers were not exposed at all in credit score prediction and
analysis process. In addition, the credit rating results were derived in their encrypted state and could only be
verified by users with decryption keys.
The results of our technology verification were as follows. We were able to confirm that the accuracy of our
homomorphic encryption-based analysis was exactly the same as that of original data-based analysis and that our
technology provided excellent analysis speed, processing millions of data in 12 hour-time frame, thereby proving once
again its applicability to real environment.
Chronic disease recurrence prediction for medical sector
The second case covers medical sector. In collaboration with domestic hospital, we developed a homomorphic encryption
technology suitable for deep learning-based model that is adept at predicting recurring chronic disease.
Our technology verification showed that encrypted analysis delivered almost the same accuracy to non-encrypted
analysis, and it took an average of 30 seconds to perform an analysis of each medical case. It also showed that if we
apply homomorphic encryption parallelization to the process, we could reduce processing time to less than 1 second per
case, which is good enough for on-site application.
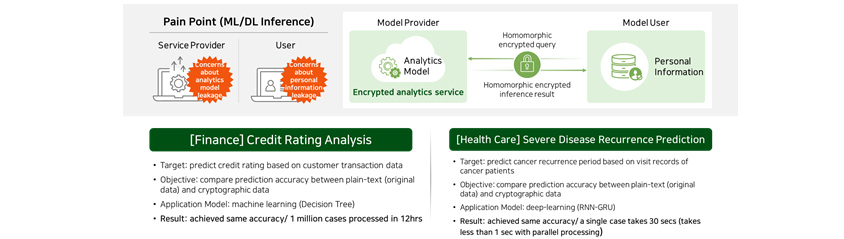
- [Finance] Credit Rating Analysis
- Target: predict credit rating based on customer transaction data
- Objective: compare prediction accuracy between plain=text (ofiginal data) and cryptographic data
- Application Model: machine learing (Decision Tree)
- Result: Achieved same accuracy/ 1 million cases processed in 12hrs
- [Health Care] Severe Disease Recurrence Prediction
- Target: predict cancer recurrence period based on visit records of cancer patients
- Objective: compare prediction accuracy between plain-text (original data) and cryptographic data
- Appliction Model: deep-learning (RNN-GRU)
- Result: achieved same accuracy/ a single case takes 30 secs (takes less than 1 sec with parallel processing)
6. Closing
These use cases helped us confirm how important it is to protect our customers’ sensitive data and their assets
(high-performance analysis models) and how worried they are about possible institutional and legal risks that may come
with new services offered using their sensitive data/assets. Moreover, we could see how important it is to these
concerning customers that we provide PET-based analysis solution that can accommodate high-quality services and also
avoid data/asset leakage at their sources.
If we could provide PET-based analysis service that is both user-friendly and is adept at responding quickly to the
needs of various industries, countless number of data that are sitting idly away at the moment could be used towards
new businesses more aggressively.

# References
[1] ISO/IEC 20889:2018,
Privacy enhancing data de-identification terminology and classification of techniques
[2] https://www.samsungsds.com/kr/insights/GDPR_data_analytics.html
[3] http://www.humangenomeprivacy.org/2020/
[4] https://www.mk.co.kr/today-paper/view/2020/4679442/
▶ The content is proected by law and the copyright belongs to the author.
▶ The content is prohibited to copy or quote without the author's permission.
- The First Step to Smart Textual Analysis, KoreALBERT
- Smart QA Model That Understands Even Complex Tables
- I Will Give You Data, Label It~ Auto Labeling!
- The Connecting Link for Everything in the World, It’s in the Knowledge Graph
- Easy and Simple Blockchain Management, Nexledger!
- No More Short of GPU!
- In the Age of When Customer Data Must Be Treated as a King, PET Will Take on the Responsibility
- It is Important to Prevent Security Risks from Development Phase! Trust CAFA+ to Do the Job

Security Algorithm Team at Samsung SDS R&D Center
With his experience and expertise in encryption technology, he is involved in research & development of new encryption technology and privacy protection technology.
If you have any inquiries, comments, or ideas for improvement concerning technologies introduced in Technology Toolkit 2021, please contact us at techtoolkit@samsung.com.
-
[Technology Toolkit]
It is Important to Prevent Security Risks from Development Phase! Trust CAFA+ to Do the Job - Effective Personal Information Protection Technology for Post COVID-19 Era
- Samsung SDS America showcases Nexsign at Finovate Spring 2018
- Bridging the gap between user experience and mobile security
- The importance of secure browsers in commercial banking