

Technology Toolkit 2021은 삼성SDS 연구소에서 연구개발 중인 주요 기술들을 설명하는 기술 소개서입니다.
AI, Blockchain, Cloud, Security 기술 분야의 총 7개 기술에 대해서 각각 기술 정의, 주요 기능, 차별화 포인트 및 Use Cases를 소개하여 독자 여러분께 인사이트를 제공하고자
합니다.
한글 사전학습 모델 기반 텍스트 분석
1. 기술 소개
기술 동향 및 배경
① 통계적 언어 모델의 의미 표현 한계
언어의 본질은 의미를 전달하는 것입니다. 문장은 어떤 의미를 담고 있고, 사람은 문장 속의 각 단어의 의미를 알고 해석함으로써 그 의미를 이해할 수 있습니다. 언어를 딥러닝 모델에 적용하려면 어떻게 해야 할까요?
딥러닝 모델은 실숫값 사이의 연산으로 표현됩니다. 그렇기 때문에 언어를 딥러닝 모델에 적용하기 위해서는 의미를 실숫값으로 변환하는 작업이 필요합니다. 과거의 모델들은 이러한 실숫값 변환을 각 단어에 미리 정해
놓은 값을 대입하는 방식으로 처리하였습니다. 그러나 이러한 방식은 동음이의어를 처리할 수 없다는 단점이 있습니다. 예를 들어, 아래 [그림 1]처럼 “Bank Account”와
“River Bank”의 “Bank”가 같은 실숫값을 사용하게 되어 다른 의미를 표현할 수 없게 되는 것입니다. 그렇기 때문에 문장의 문맥을 반영한 의미 표현이 필요하게
됩니다.

② 딥러닝 언어 모델을 위한 학습 데이터 한계
딥러닝 언어 모델을 학습하기 위해서는 모델의 크기에 따라 다르지만 많은 양의 학습 데이터가 필요합니다. 특히 지도학습(Supervised Learning)을 위한 데이터에는 정답(Label)이 필요한데 이런
데이터를 구축하기 위해서는 많은 시간과 비용이 듭니다. 큰 모델을 학습시키기 위해서 정답이 달린 수천만 개의 문장 데이터를 만드는 것 자체가 쉽지 않은 일이 됩니다.
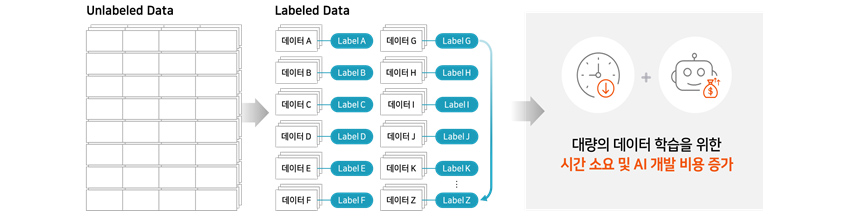 [그림 2] 딥러닝 언어 모델을 위한 학습 데이트 한계
[그림 2] 딥러닝 언어 모델을 위한 학습 데이트 한계
③ 사전학습 모델의 특징
2018년 구글에서 제안한 BERT(Bidirectional Encoder Representation from Transformers)는 위의 한계점을 해결하기 위해 대량의 영어 데이터로 학습된 사전학습 언어
모델로 종합 언어 이해 태스크(GLUE) 및 기계독해 태스크(SQuAD v1.1, SQuAD v2.0) 등에서 당시 통계적 언어 모델 대비 큰 차이로 SOTA(State-Of-The-Art)를 달성하였습니다.
이후 BERT와 비슷한 방식으로 학습한 다양한 언어 모델이 제안되었습니다. 본질적인 학습 방법은 BERT와 비슷하기 때문에, 이 장에서는 BERT를 기준으로 어떻게 위의 한계점을 해결하였는지
알아보겠습니다.
④ 문맥을 반영한 의미 표현
BERT는 문맥을 반영한 의미 표현이 되도록 아래 두 가지 방법으로 학습합니다. 주변 단어, 혹은 주변 문장과의 관계를 학습함으로써 언어의 의미를 더 정확하게 표현할 수 있게 됩니다.
• Masked Language Model(MLM)
MLM은 어떤 문장이 있을 때 문장의 특정 부분을 Masking 처리하여 모델이 Masking 처리된 부분을 예측하도록 학습시키는 방식입니다. 이때 모델은 Masking 된 부분의 앞뒤 문맥을 파악하여 답을
찾도록 훈련됩니다. 따라서 자연스럽게 주변 단어들과의 관계에 따라 단어의 의미를 다르게 인식하게 됩니다.
 [그림 3]
MLM 학습 예시
[그림 3]
MLM 학습 예시
• Next Sentence Prediction(NSP)
NSP는 두 문장이 이어지는 문장인지 아닌지를 맞히도록 학습시킵니다. 이러한 학습 방식을 통해 모델은 앞뒤 문장의 문맥을 파악할 수 있게 됩니다.
 [그림 4] NSP
학습 예시
[그림 4] NSP
학습 예시
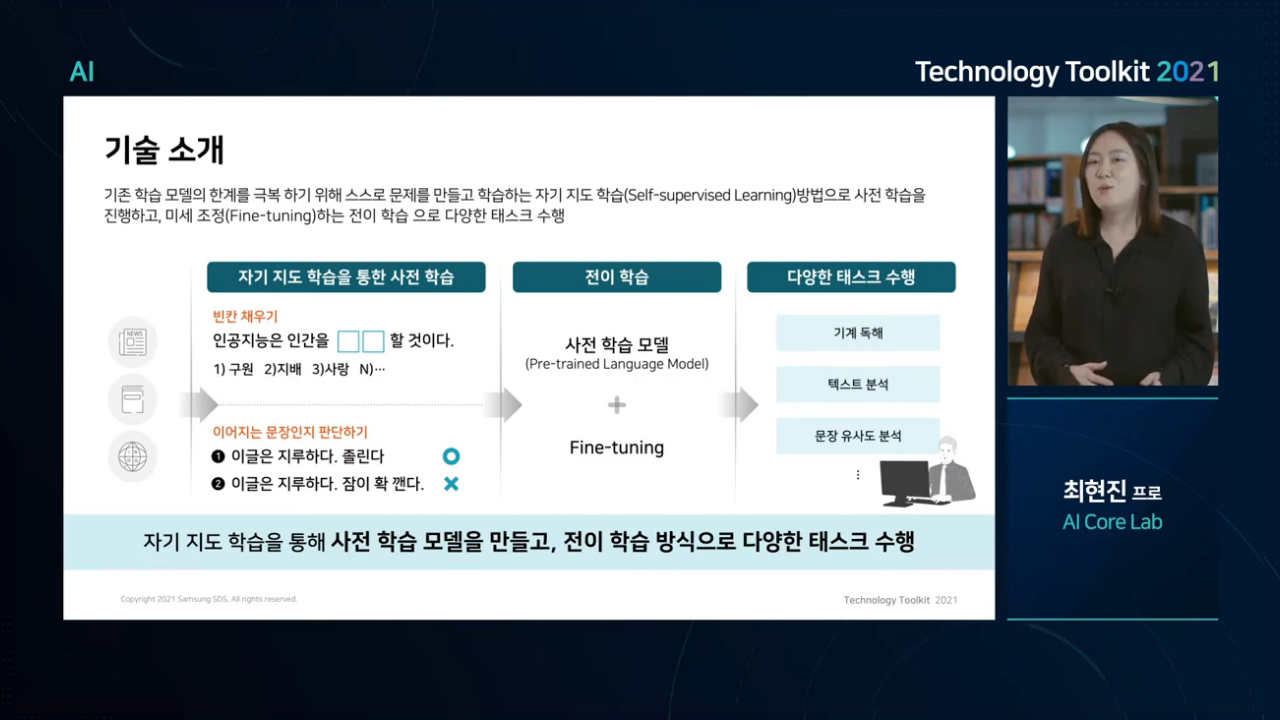
⑤ 자기지도학습을 통한 학습 데이터 한계 극복
딥러닝 언어 모델을 활용한 다양한 텍스트 분석 태스크(또는 기능)들이 있습니다. 주어진 문장이 긍정적인지, 부정적인지를 예측한다거나, 주어진 질문에 대답하거나, 어떤 문장과 유사한 다른 문장을 찾을 수도
있습니다. 이때 다른 태스크를 진행할 때마다 해당 태스크와 관련 데이터를 구해서 학습을 시키려면 태스크별로 엄청나게 많은 양의 데이터가 필요하게 됩니다. 그런데 잘 살펴보면 태스크는 다르지만 같은 언어를
사용한다는 점에서 각 태스크 모델은 공통적인 언어 소양이 필요합니다. BERT는 MLM, NSP와 같은 학습 방법을 통해 언어의 기본기를 익히는 사전학습을 진행합니다. MLM 방식으로 위키백과에 있는 문장에
Masking 처리하여 학습 데이터를 만들고, NSP 방식으로 원래 연결된 문장 2개와 서로 다른 문서에서 가져온 문장 2개를 합쳐 학습 데이터를 만듭니다. 학습 Label을 사람이 직접 만들지 않고도 스스로
만든 데이터를 학습함으로써 언어의 기본 소양을 쌓을 수 있게 되는 것입니다. 이처럼 스스로 정답이 있는 학습 데이터를 만들어 학습하는 방식을 자기지도 학습(Self-supervised Learning)이라고
하고, 이러한 방식으로 만들어진 언어 모델을 사전학습 모델(Pre-trained Language Model)이라고 합니다.
⑥ 전이학습을 통한 파인튜닝
위와 같이 만들어진 사전학습 모델을 기반으로 특정 태스크를 위해 한 번 더 학습하는 방식을 전이학습(Transfer Learning)이라 하고, 이 학습 단계를 파인튜닝 단계라고 합니다. 파인튜닝이란 사전학습
모델을 기반으로 특정 태스크를 위해 딥러닝 모델을 미세하게 조정하는 학습 과정을 말합니다. 사전학습된 BERT 자체는 특정 태스크를 수행하도록 학습된 모델이 아니기 때문에 원하는 태스크에 맞춰 재학습하는 과정이
필요합니다. 파인튜닝을 통해 수행 가능한 태스크는 아래 Use Cases를 통해 살펴보겠습니다.
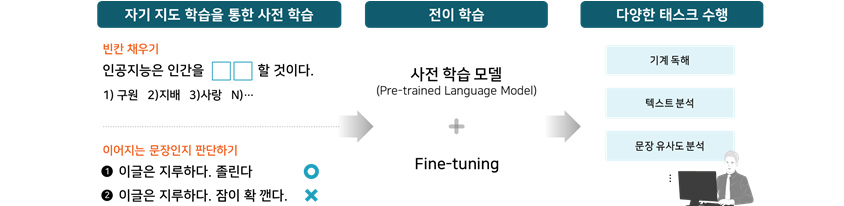
- 빈칸 채우기
- 인공지능은 인간을 OO할 것이다.
- 1) 구원 2)지배 3)사랑 4)N...
- 이어지는 문장인지 판단하기
- 1) 이글은 지루하다. 졸린다 (o)
- 2) 이글은 지루하다. 잠이 확 깬다. (x)
- 사전 학습 모델(Pre-trained Language Model) + Fine-tuning
- 기계 독해
- 텍스트 분석
- 문장 유사도 분석
2. 주요 기능
한국어 사전학습 모델
영어 기반의 다양한 모델들이 공개되었지만, 한국어의 경우 영어와는 다른 언어적 특성이 있기 때문에 영어 모델을 그대로 활용하기는 어렵습니다. 삼성SDS 연구소는 많은 양의 한글 데이터를 직접 수집하여 사전학습
모델을 만들었습니다.
① KoreALBERT
첫 번째로 소개할 모델은 KoreALBERT(Korea + ALBERT)입니다[그림 6]. BERT의 경량화 모델인 ALBERT(A Lite BERT) 아키텍처를 기반으로 한글을 학습시켰습니다. 학습 데이터는
다양한 분야의 비즈니스에 공통으로 적용이 가능하도록 한글 위키피디아, 신문 기사, 책 줄거리 등 일반적인 분야의 문어체 위주 한글 텍스트로 구성되었습니다. 또한 기존에 존재하는 다른 한글 언어 모델과 차별화하기
위해 모델 경량화에 강점을 갖는 새로운 아키텍처와 특허를 받은 학습 방법을 사용하였습니다(3. 차별화 포인트).
② KoELECTRA
ELECTRA는 BERT 이후에 등장한 언어모델로서, BERT가 가진 학습 데이터 사용의 비효율성을 극복하기 위해 탄생한 모델입니다. 기존 모델인 BERT는 학습 과정에서 전체 입력 토큰 중 [MASK]로 가려진
15%의 토큰들만 학습에 사용하기 때문에 데이터 효율성이 떨어지게 됩니다. ELECTRA는 이를 극복하기 위해 [MASK]로 가려지지 않은 나머지 85% 토큰에 대해서도 학습을 진행하므로 BERT 대비 초기 학습
속도와 성능 면에서 우수하다고 증명되었습니다. 이러한 ELECTRA 모델 아키텍처를 한글로 학습한 모델이 KoELECTRA입니다. KoreALBERT보다 무겁지만, 더 좋은 성능을 자랑합니다.

- koreAlert
- 한글 데이터 사전학습 모델
- Korea + ALBERT
- BERT의 경량화 모델인 ALBERT(A Lite BERT) 아키텍쳐 기반으로 학습
- 모델 경량화(BERT 대비 1/10 크기
- 한국어에 특화된 학습 방법 사용 (특허)
- KoElectra
- 한글 데이터 모델
- Korea + ELECTRA
- BERT의 비효율성을 극복하기 위한 ELECTRA 아키텍쳐 기반으로 학습
- KoreaALBERT에 배해 무겁지만 더 좋은 성능
다양한 태스크에 활용
사전학습 모델은 모델 자체로 특정 기능을 수행할 수 없습니다. 하지만 파인튜닝을 통해 여러 다양한 태스크에 활용할 수 있습니다. NLP(Natural Language Processing)는 크게
NLU(Natural Language Understanding)와 NLG(Natural Language Generation)로 나누어집니다. NLU는 문맥 파악을 통해 문장을 이해하고, NLG는 파악한 문맥을
기반으로 문장을 생성합니다. 예를 들어, 챗봇을 만들기 위해서는 화자의 말을 이해하는 NLU, 그리고 응답을 하도록 말을 생성하는 NLG가 모두 필요합니다.
① NLU
거의 모든 NLU 태스크에 사전학습 모델이 사용됩니다. 사전학습 모델을 기반으로 한 파인튜닝을 통해 기계독해, 텍스트 분류, 유사도 분석 등의 태스크를 수행할 수 있습니다.
② NLG
NLG 모델은 NLU 모델보다 문장을 생성하는 디코더 모듈(Decoder Module)이 추가로 구성되어 있어서 기존 NLU 모델 대비 사전학습 비용이 거의 2배 이상 소요됩니다. 그러나 최근에 NLU 모델을 활용하여 기존 NLG 모델 사전학습에서 소요되었던 비용을 절감할 수 있는 방법에 관한 논문들이 발표되었습니다.

- NLU
- 언어를 이해하는 능력
- 듣기 읽기에 해당
- 텍스트 분류, 유사도 분석, 기계독해등 언어 이해가 필요한 태스크에 활용
- NLU
- 문장을 생성하는 태스크
- 말하기, 쓰기에 해당
- 요약, 패러프레이징, 챗봇 등에 활용
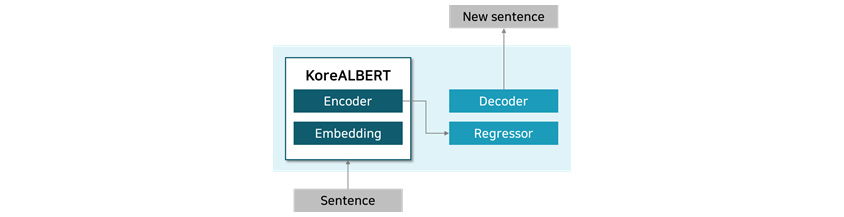 [그림 8] KoreALBERT를 이용한 NLG 모델 구성도
[그림 8] KoreALBERT를 이용한 NLG 모델 구성도 3. 차별화 포인트
개선된 사전학습 방법
삼성SDS는 텍스트 분석에 사용하는 핵심엔진인 사전학습 모델의 경량화와 정확도 향상을 위해 새로운 학습 방법을 도입하였습니다. 사전학습 단계에 무작위로 섞인 단어들의 순서를 예측하는 학습 단계[그림 9]를
추가하여 학습 효율을 향상함으로써 모델의 파라미터 크기를 대폭 줄이면서(기존 모델인 BERT의 파라미터 크기와 대비하여 1/10 수준) 동시에 예측 정확도를 향상했습니다. 이 연구 결과는 특허 등록과 함께 해외
Top-tier 학회인 ICPR 2020에 발표하였고, 이를 이용해 학습한 KoreALBERT 모델은 ERP VoC 분석 시스템에 적용하여 CPU 기반 서버에서 운영하고 있습니다(4. Use Cases).
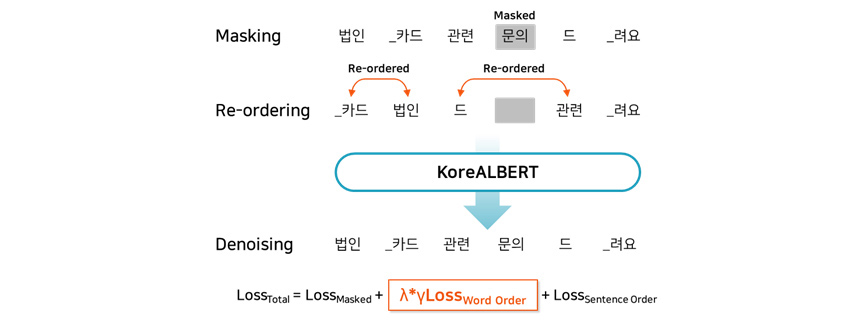 [그림 9] KoreALBERT 학습
방법(출처: http://arxiv.org/abs/2101.11363)
[그림 9] KoreALBERT 학습
방법(출처: http://arxiv.org/abs/2101.11363) 이 외에도 대량의 다국어 데이터를 활용한 전이학습 방식과 CNN(Convolutional Neural Network) 아키텍처를 활용한 추가 레이어 학습 방식을 제안하여 한글뿐만 아니라 영어를 비롯한 다국어에
적용 가능한 모델을 확보하였습니다. 해당 모델은 대표적인 한글 MRC Dataset 인 KorQuAD v1.0(Korean Question Answering Dataset)의 공식 Leaderboard에서
1위(2020.08)를 기록함으로써 우수한 성능을 입증하였습니다.
주요 사전학습 모델의 성능 비교
하단의 [그림 10]에서는 한국어 이해 태스크에 적용 가능한 여러 사전학습 모델 간의 크기와 성능을 보여주고 있습니다. 개선된 사전학습 방식을 통해 학습된 KoreALBERT는 모델의 파라미터 크기 면에서는 다른 모델 대비 7~20% 수준이지만, 여러 한국어 이해 태스크*들의 평균점수는 오히려 향상된 결과를 볼 수 있습니다. (*성능 측정 태스크 목록: 기계독해, 유사도 분석, 개체명 인식, 의도 분류, 동일 질문 분류, 감정 분석)
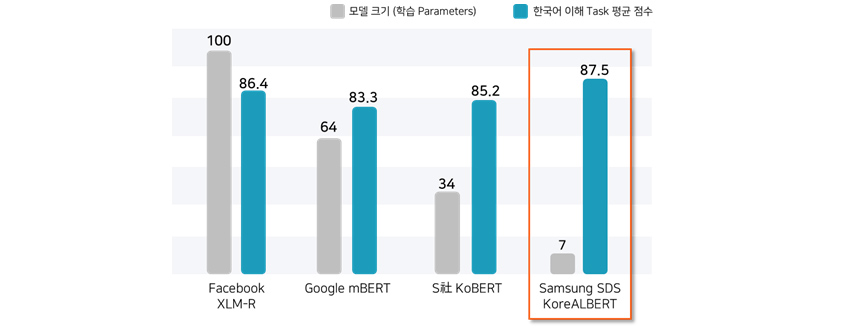
| Facebook XLM-R | Google mBERT | S사 KoBERT | Samsung KoreALBERT | |
|---|---|---|---|---|
| 모델 크기 (학습 Parameters) | 100 | 64 | 34 | 7 |
| 한국어 이해 Task 평균 점수 | 86.4 | 83.3 | 85.2 | 87.5 |
4. Use Cases
Case 1 : 기계독해(MRC, Machine Reading Comprehension)
지문을 이해하고 함께 입력된 질문에 대한 답을 찾는 기능을 수행할 수 있습니다. 기계독해 태스크를 수행하기 위해서 [그림 11]과 같이 사전학습 모델을 베이스라인 모델로 사용하였고, Enhanced CNN을 추가하여 기계독해 모델의 성능을 향상했습니다. 이러한 모델을 사용하여 KorQuAD 1.0 에서 좋은 성적을 거두었습니다.
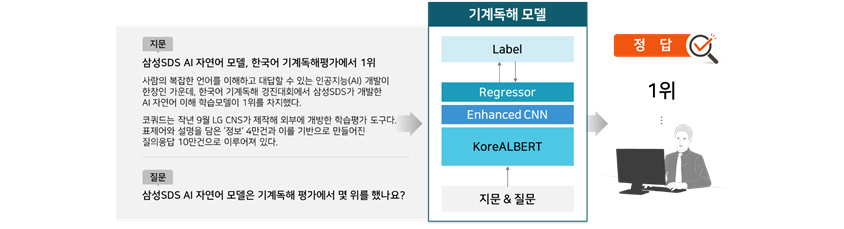
- 지문
- 삼성 SDS AI 자연어 모델, 한국어 기계독해평가에서 1위
- 사람의 복잡한 언어를 이해하고 대답할 수 있는 인공지능(AI) 개발이 한창인 가운데, 한국어 기계독해 경진대회에서 삼성SDS가 개발한 AI 자연어 이해 학습모델이 1위를 차지했다. 코쿼드는 작년 9월 LG CNS가 제작해 외부에 개방한 학습평가 도구다. 표제어와 설명을 담은 '정보' 4만건과 이를 기반으로 만들어진 질의응답 10만건으로 이루어져있다.
- 질문
- 삼성SDS AI 자연어 모델은 기계독해 평가에서 몇 위를 했나요?
- 지문 & 질문을 KoreALBERT 에입력, Enhanced CNN, Regressor 를 통하여 Label 도출
Case 2 : 텍스트 분류(Text Classification)
텍스트 분류는 입력된 텍스트가 어떤 카테고리에 해당하는지 분류하는 태스크입니다. 예를 들어, 입력 텍스트가 긍정적인지 부정적인지를 판별하는 감정 분류(Sentiment Classification)를 할 수
있습니다. 감정 분류는 사용자 댓글이나 제품 피드백을 분류하는 데 많이 사용합니다. 또한 [그림 12]와 같이 텍스트에 어떤 의도가 있는지 판별(Intent Classification)하는 데도 사용할 수
있습니다. 그뿐만 아니라, 어떤 텍스트든 정해놓은 특정 카테고리로 분류할 수 있어서 실제로 가장 많이 활용하는 태스크입니다. 텍스트 분류 모델 또한 사전학습 모델(KoreALBERT)에 따라 전체 성능이
달라집니다.
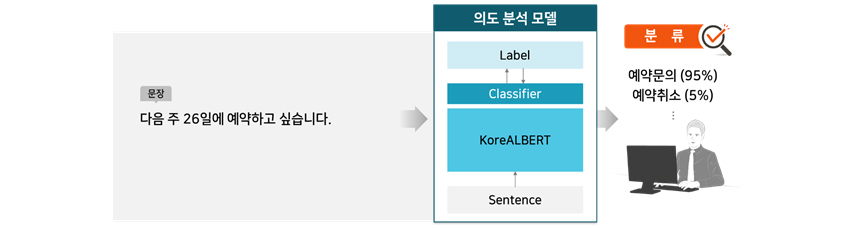
- Sentence 를 KoreALBERT 에 입력, Classifier 를 통하여 Label 도출
Case 3 : 문장 유사도 분석(STS, Semantic Textual Similarity)
문장 유사도 분석은 두 문장이 의미적 혹은 문맥적으로 얼마나 유사한지를 분석하는 태스크입니다. 이 태스크는 질의 문장과 저장된 문장 중 가장 비슷한 문장을 찾아내는 문장 검색 기능으로 활용할 수 있습니다.
문맥적인 부분까지 고려하기 때문에 기존 키워드 검색보다 감성 품질이 더 우수하다는 강점이 있습니다[그림 13 상].
검색해야 하는 문장의 개수가 늘어날수록 처리 시간이 급격히 길어집니다. 삼성SDS 연구소는 이러한 문제를 해결하기 위해 샴 네트워크(Siamese Neural Network)와 CNN 네트워크를 활용하는 새로운
아키텍처를 제안했습니다[그림 13 하]. 해당 연구 결과는 특허 등록과 해외 인공지능학회인 ICPR 2020에 발표하였습니다.
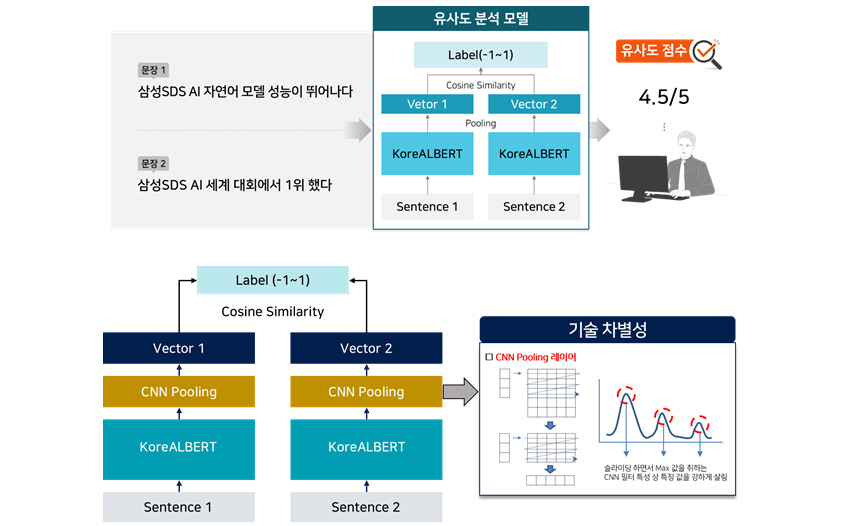
- 문장 1 : 삼성 SDS AI 자연어 모델 성능이 뛰어나다.
- 문장 2 : 삼성 SDS AI 세계 대회에서 1위 했다.
- Sentence 1 를 KoreALBERT 에 입력, pooling 하여 Vector 1 도출
- Sentence 2 를 KoreALBERT 에 입력, pooling 하여 Vector 2 도출
- Vector 1과 Vector 2의 Cosine Similarity 통하여 Label(-1~1) 도출
- 유사도 점수: 4.5/5
- Sentence 1 를 KoreALBERT 에 입력, CNN Pooling 통하여 Vector 1 도출
- Sentence 2 를 KoreALBERT 에 입력, CNN Pooling 통하여 Vector 2 도출
- Vector 1과 Vector 2의 Cosine Similarity 통하여 Label(-1~1) 도출
- CNN Pooling layer
- 슬라이딩 하면서 Max 값을 취하는 CNN 필터 특성 상 특징 값을 강하게 살림
Case 4 : 문서 요약 모델(Text Summarization)
문서 요약 모델은 [그림 14]와 같이 문서의 주요 문장을 추출하여 요약 문장을 만드는 추출 요약 모델(Extractive Summarization)과 문서의 내용을 이해하고 문맥에 맞는 문장을 생성하는 생성
요약 모델(Abstractive Summarization)이 있습니다. 각각 추출 요약은 NLU, 생성 요약은 NLG를 기반으로 모델을 만들 수 있습니다. 문서 요약 기능은 많은 문서를 통해 인사이트를 얻어야
하는 분석가들에게 요약된 내용을 전달함으로써 시간과 비용을 줄여 줄 수 있습니다.
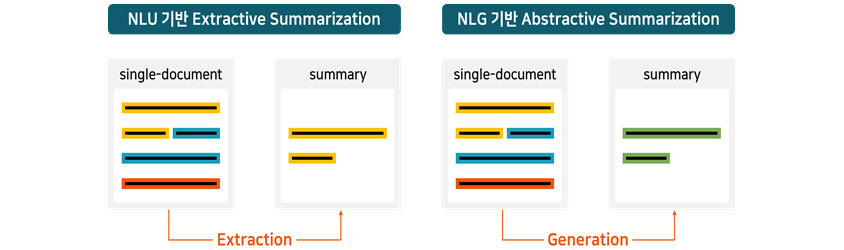
- single-document, Extraction, summary
- single-document, Generation, summary
5. 비즈니스 사례
VoC(Voice of Customer) 서비스에 언어 모델을 활용한 사례입니다.
A 고객의 ERP 시스템 VoC 처리 프로세스
(1) 시스템 사용자가 시스템 문의(VoC)를 접수
(2) 서비스 데스크에서 VoC를 확인하여 시스템 담당자에게 배정
(3) 배정된 담당자가 유형을 검증하여 잘못 배정된 경우 재배정 프로세스 진행
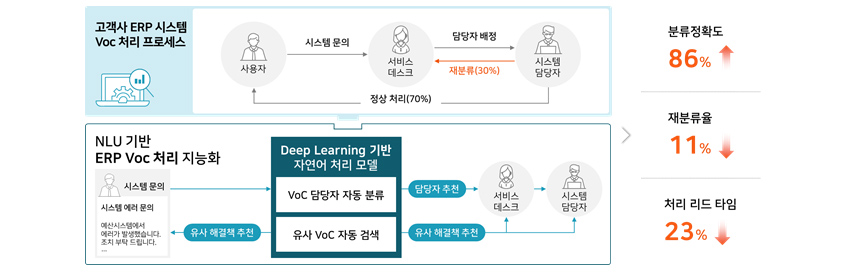
- 사용자: 시스템 문의
- 서비스데스크: 시스템 담당자 배정
- 시스템 담당자:재분류(30%), 정상처리(70%)
- 시스템문의(시스템 에러 문의): 에러시스템에서 에러가 발생했습니다. 조치 부탁드립니다.
- 유사 해결책 추천
- Deep Learning 기반 자연어 처리 모델
- voc 담당자 자동분류
- 담당자 추천 -> 서비스데스크
- 유사 VoC 자동검색
- 유사 해결책 추천 ->시스템 담당자
- 분류 정확도 86%
- 재분류율 11%
- 처리 리드 타임 23%
기존 시스템은 잘못된 배정으로 인한 재분류율이 30%에 달하였고, 전체 서비스 리드타임을 늦추는 요인이 되었습니다. 삼성SDS 연구소는 이러한 부분을 개선하고자 딥러닝 기반의 ‘VoC 담당자 자동 분류
모델’과 ‘유사 VoC 자동 검색 모델’을 적용하여 분류 정확도를 86%까지 달성하였고, 재분류율은 11%로 감소하였으며, 처리 리드타임은 23%로 낮출 수 있었습니다.
6. 맺음말
사전학습 기반의 언어 모델이 점점 확대 적용되면서 비즈니스 사례가 늘고 있습니다. 삼성SDS 연구소는 성능이 더 뛰어난 사전학습 모델을 확보하고, 이를 기반으로 현업의 다양한 태스크(4. Use Cases)에
적용하고자 합니다. 또한 다양한 형태의 텍스트 정보를 분석하고, 새로운 형태의 인사이트를 지속해서 제공함으로써 고객에게 새로운 가치를 창출하고자 합니다.
 [Technology Toolkit 2021] 한글 PLM(Pre-trainedLanguage Model)기반 텍스트 분석 - 한글 언어모델과 활용 기술
[Technology Toolkit 2021] 한글 PLM(Pre-trainedLanguage Model)기반 텍스트 분석 - 한글 언어모델과 활용 기술 동영상 보기
References
[1] KoreALBERT: Pretraining a Lite
BERT for Korean Language Understanding
[2] https://korquad.github.io/category/1.0_KOR.html
[3] Evaluation of BERT and ALBERT
Sentence Embedding Performance on Downstream NLP Tasks
[4] Analyzing Zero-shot
Cross-lingual Transfer in Supervised NLP Tasks
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에게 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의 없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
![]()

김주동 | 삼성SDS 연구소 AI Core Lab
삼성 SDS AI연구팀 연구원, 딥러닝 언어 모델 및 모델 성능 개선 연구를 진행하고 있습니다.
이현제 | 삼성SDS 연구소 AI Core Lab
삼성SDS 연구소 AI 연구팀에서 자연어 처리 관련 기술을 연구하고 있으며 특히 한국어를 위한 언어모델 연구에 참여하고 있습니다.
최현진 | 삼성SDS 연구소 AI Core Lab
학부 때 경영학을 전공했지만 삼성SDS에 Software Engineer로 입사하였습니다. 웹/모바일, 윈도우 프로그래밍을 거쳐 현재는 AI 연구센터에서 Computational Linguistics 연구를 하고 있습니다.
Technology Toolkit 2021에 소개한 기술에 대해 문의사항이 있으시거나, 아이디어, 개선사항 등 의견이 있으시면, techtoolkit@samsung.com으로 연락해 주세요.