

Technology Toolkit 2021은 삼성SDS 연구소에서 연구개발 중인 주요 기술들을 설명하는 기술 소개서입니다.
AI, Blockchain, Cloud, Security 기술 분야의 총 7개 기술에 대해서 각각 기술 정의, 주요 기능, 차별화 포인트 및 Use Cases를 소개하여 독자 여러분께 인사이트를 제공하고자 합니다.
Insight Engine
1. 기술 소개
기술 동향 및 배경
지식 그래프는 관련 있는 정보들을 간선(Edge)과 정점(Node)으로 표현한 지식 구조 표현입니다. 정보를 지식 그래프의 형태로 저장하면 연관성 높은 정보들을 쉽게 확인할 수 있기 때문에, 사용자에게 더욱 풍부한 정보를 제공할 수 있습니다.
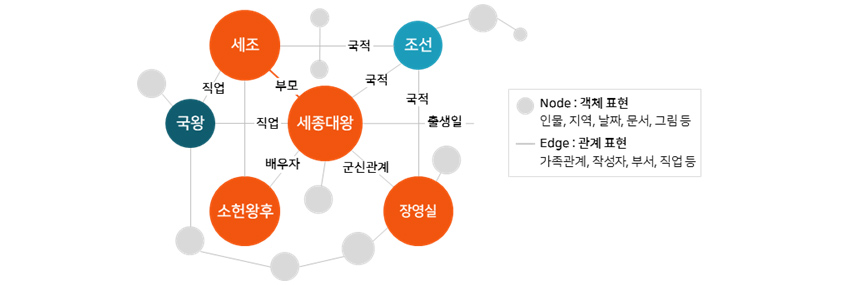 [그림 1] 지식 그래프
[그림 1] 지식 그래프
지식 그래프의 장점을 가장 잘 활용할 수 있는 분야는 정보 검색입니다. 기존에는 정보 검색을 위해 역색인(Inverted Index: 문서 집합 내에서 키워드의 내용과 위치를 연결) 방식으로 데이터를 저장했습니다. 이 방법은 질의가 포함된 문서를 잘 보여줄 수 있지만, 연관된 지식을 같이 표시하기는 어렵습니다.
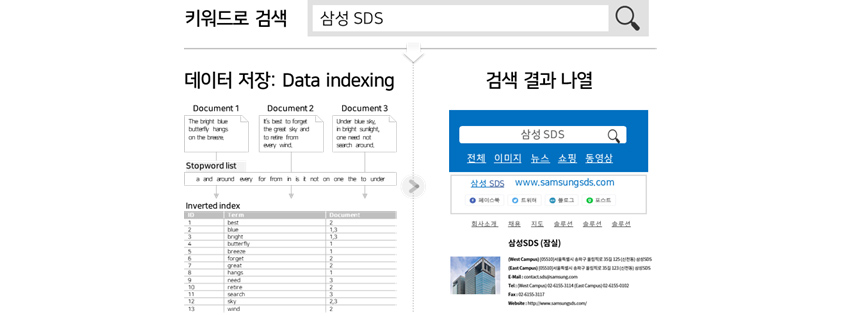 [그림 2] 역색인 방식*
[그림 2] 역색인 방식*(키워드 기반 검색 후 결과가 나오면 사용자가 링크를 선택하여 원하는 정보를 찾을 때까지 검색 반복)
검색을 고도화하고 사용자가 원하는 정보를 관련 있는 정보들과 함께 일목요연한 구조로 전달하려면 지식 그래프를 구축하는 것이 필수입니다. 지식 그래프 기술은 Gartner가 2019년에 발표한 10대 데이터 및
분석 기술 트렌드[3]에 포함할 정도로 활용 가치가 높고, 활용 범위가 확대될 것으로 예상합니다. 해당 포스트에서는 Google과 Amazon 등 글로벌 기업이 검색 고도화를 위한 지식 저장
방법으로 적극 도입하고 있는 지식 그래프와 활용 기술에 대해 소개하였습니다.
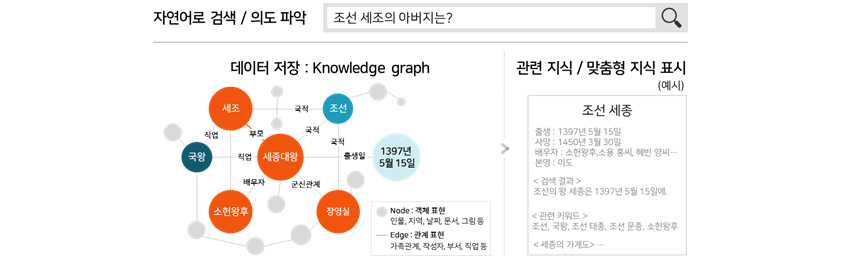 [그림 3] 지식 그래프를 활용한 검색 고도화
[그림 3] 지식 그래프를 활용한 검색 고도화
기술 정의
① 지식 그래프(Knowledge Graph)
지식 그래프는 개별 객체의 데이터를 나타내는 정점과 객체 간의 연관성을 의미하는 간선으로 표현할 수 있는 그래프 형태의 저장된 지식을 의미합니다. 지식 그래프로 데이터를 표현하는 가장 큰 목적은 그래프 구조가
연관성을 포함한 형태로 지식을 축적하고 전달하는 데 가장 유리한 자료구조이기 때문입니다.
② 지식 설계(Knowledge Design)
지식은 축적된 분야에 따라서 개념과 용도가 다르기 때문에, 지식 그래프를 구성하는 정점과 간선은 분야에 따라 다른 내용이 포함되어야 합니다. 지식 그래프를 활용하여 최종적으로 제공하는 서비스에 따라 활용할 정점과
간선의 종류를 구체적으로 결정하는 과정을 지식 설계라고 합니다.
③ 지식 엔지니어링(Knowledge Engineering)
지식 그래프는 여러 데이터 소스로부터 수집한 데이터를 분석하여 구성합니다. 문서와 같은 텍스트 데이터로부터 자연어 분석 기술을 이용하여 텍스트에 포함된 내용을 정점과 간선의 형태로 변환하여 축적합니다. 자연어
처리 기술의 한계를 극복하고 새롭게 등장하는 구성요소 등을 반영하기 위해 주기적으로 지식 전문가들이 지식 그래프를 점검하고 잘못 축적된 데이터를 수정해야 합니다. 이 과정을 지식 엔지니어링이라고 합니다.
기술 특징
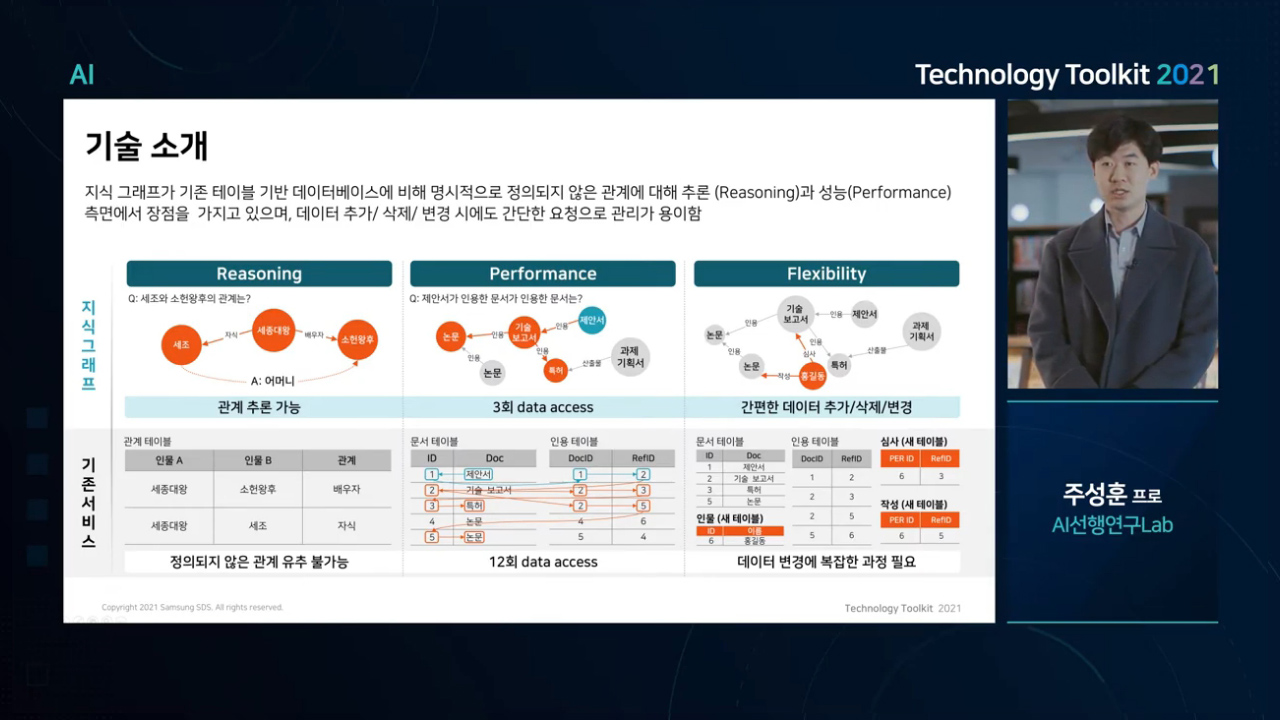
지식 그래프는 테이블 기반 데이터베이스에 비해 많은 장점을 갖고 있습니다. 첫째, 명시적으로 정의되지 않은 관계에 대해 추론(Reasoning)이 가능합니다. 기존 테이블 기반의 데이터베이스는 테이블에 개체
간의 관계가 정의되지 않은 경우 관계를 유추하는 것이 불가능하지만, 지식 그래프는 기존에 정의된 지식 그래프의 관계를 토대로 새로운 관계를 탐색, 추론하는 것이 가능합니다. 둘째, 여러 번의 참조를 통해 대답해야
하는 질문에 대해 지식 그래프는 성능 측면에서 장점을 갖고 있습니다. 예를 들면, “제안서가 인용한 문서가 인용한 문서를 보여주세요”라는 질문에 기존 데이터베이스는 문서 테이블과 인용 관계를
나타내는 테이블을 상호참조하면서 여러 번의 데이터 접근이 필요하지만, 지식 그래프는 문서들이 인용 관계로 연결되어 있기 때문에 몇 번의 접근으로 질문에 대한 답을 찾을 수 있습니다. 마지막으로, 기존 데이터와
새로운 관계를 갖는 데이터가 추가, 삭제, 변경될 경우 지식 그래프는 아주 간단하게 요청을 처리할 수 있습니다. 기존 데이터베이스에서는 새로운 타입의 데이터가 추가될 때마다 테이블을 늘리고, 기존 데이터와의 연결
관계를 모두 고려해야 합니다. 이때 계산 비용이 많이 들 뿐 아니라, 데이터 정합성의 문제가 생길 가능성이 있습니다. 지식 그래프는 이미 구축된 지식 그래프에 정점을 추가하거나 삭제하고, 기존 정점 간의 관계를
고려해 간선을 새로 연결하거나 삭제하기만 하면 되기 때문에 관리가 매우 쉽습니다.
 [그림 4] 지식 그래프 기술의 기존 데이터베이스 대비 장점
[그림 4] 지식 그래프 기술의 기존 데이터베이스 대비 장점
2. 주요 기능
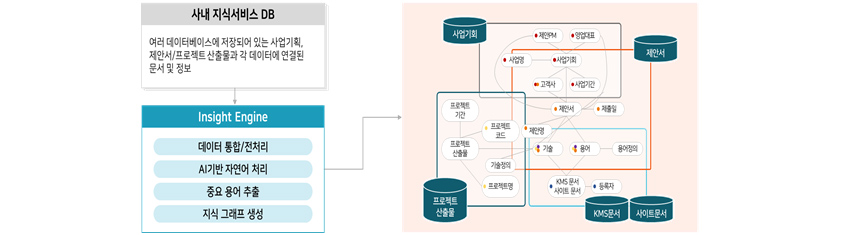
삼성SDS 연구소는 비정형 텍스트 데이터를 지식 그래프로 구성, 관리하고 활용하는데 필요한 기능을 SDS Insight Engine이라는 기술 집합 솔루션의 형태로 제공합니다. SDS Insight
Engine은 기업이 보유하고 있는 지식정보 데이터베이스로부터 AI 기반 비정형 텍스트 분석 기술을 이용해 지식 그래프를 구축할 수 있는 기능을 제공합니다. 또한, 지식 그래프를 활용해 검색 서비스와 추천
서비스를 고도화할 수 있는 API를 제공합니다.
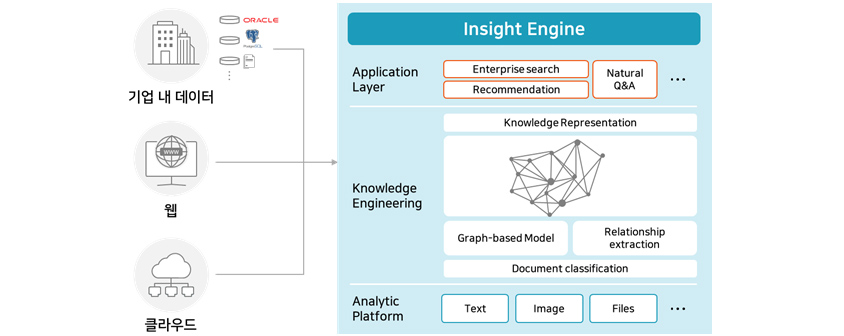 [그림 5] SDS Insight Engine
[그림 5] SDS Insight Engine
Analytic Platform: 여러 소스에 저장된 다양한 데이터 분석
기업이 보유하고 있는 지식 정보 데이터는 DB, 웹 또는 클라우드에 이르기까지 다양한 저장소에 보관되어 있습니다. 지식 정보는 텍스트와 다양한 형식의 첨부파일뿐만 아니라 이미지 형태로도 저장되어 있습니다.
Insight Engine은 기본적으로 비정형 텍스트 데이터로부터 지식을 추출하는데, 이미지 형태의 텍스트, 각종 오피스 문서(pdf, doc, ppt, pdf, html 등)에 포함된 텍스트까지 추출하여 분석할
수 있습니다.
Insight Model Layer: 자연어 처리 기술을 이용한 지식 그래프 구축
각 데이터 소스로부터 가져온 비정형 텍스트 데이터를 분석해 지식 그래프를 구축하기 때문에, 형태소 분석, 언어 판별, 개체명 인식, 토크나이저, 관계 추출 모듈 등의 기본적인 언어 분석 툴을 제공합니다. 지식
그래프에 저장된 지식을 바탕으로 개인화 추천 모델을 구현하는 API를 제공합니다.
지식 그래프를 구축하고 활용하려면 지식 정보를 저장하고 찾는 기능이 포함된 그래프 데이터베이스가 필요합니다. SDS Insight Engine은 오픈소스 그래프 데이터베이스인 JanusGraph와 Neo4j를
활용해 지식 그래프를 구현할 수 있도록 설계되었습니다. 간선과 정점을 추가 및 삭제할 수 있고, 질의가 주어지면 지식 그래프상에서 노드를 검색하고 연결된 하위노드들까지 검색할 수 있는 다양한 기능의 API를
제공합니다.
Application Layer: 검색 고도화, 개인화 추천, QA 시스템에 지식 그래프를 적용할 수 있는 API
지식 그래프에 축적된 지식은 기존의 검색, 추천, 분류, 예측을 위한 AI 모델과 연계하여 사용할 수 있습니다. 또한 지식 그래프에 저장된 자연어 지식으로부터 자연어 처리 및 이해 기술(NLP, NLU)을
활용하여 Complex Answering을 제공하는 응용서비스에 적용할 수 있습니다.
SDS Insight Engine은 아래와 같은 특징을 갖고 있습니다.
다양한 데이터 소스의 통합
∙ 텍스트(Email, HTML) 데이터뿐만 아니라 이미지, 음성 데이터의 통합 활용
의도 및 상황 인지
∙ AI 기반 자연어 처리를 통한 의도와 상황 인지
∙ 지식 그래프의 관계 기반 추출로 의미 있는 정보 제공
지식 확장성
∙ 데이터 소스 간 관계 구성으로 지식 확장
∙ 실시간 수집, 변경되는 지식에 대해 효과적인 업데이트와 운영
인공지능 기반
∙ 자연어 처리 및 이해 기술(NLP, NLU)을 활용한 Complex Answering 제공
∙ 기존의 검색, 추천, 분류, 예측 AI 모델과 연계
3. 차별화 포인트
AI 기반 자연어 처리 기술을 활용한 그래프 생성 자동화
검색 시스템을 고도화하기 위해 지식 그래프를 도입하는 것을 고민하는 고객들은 기존 검색 시스템과 별개로 새롭게 지식 그래프를 구축하고 운영해야 한다는 부담감을 느끼고 있습니다. SDS Insight
Engine은 지식 정보 데이터베이스를 통합하고 데이터에 포함된 정보를 쉽게 지식 그래프에 저장할 수 있는 자동화 기능을 제공합니다. 지식 정보 데이터베이스를 지식 그래프에 저장하는 케이스를 예로 들면,
데이터베이스 스키마를 참조해 지식 그래프의 정점에 해당하는 인물, 지명, 회사명, 문서 카테고리 등의 정보와 그 관계들을 추출합니다. 또한 연결된 첨부파일에서 텍스트 데이터를 추출해 자연어 처리 분석에
활용합니다.
최근에는 다양한 지식이 문서 스캔본과 같은 이미지 형식(jpg, png 등)으로 저장되거나, html처럼 텍스트와 테이블 구조가 복합적으로 포함된 구조로 저장되어 있어 현존하는 기술에서는 정보를 추출해 지식
그래프를 생성하기에 어려움이 있습니다. SDS Insight Engine은 정보가 다양한 형식으로 저장된 경우라도 적합한 텍스트 추출 기술을 활용해 비정형 텍스트를 추출하고 분석하여 지식 그래프를 구축할 수 있는
강점이 있습니다.
 [그림 6] 지식 그래프 생성 자동화 기능
[그림 6] 지식 그래프 생성 자동화 기능
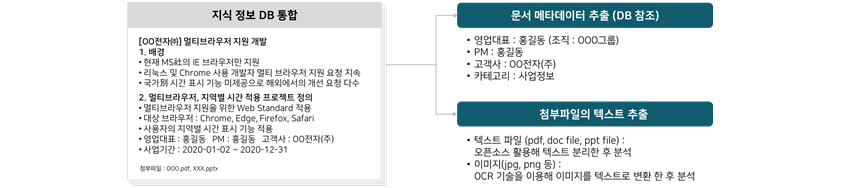
지식정보 DB통합
예시 00전자(주) 멀티브라우저 지원 개발-
- 1. 배경
- 현재 MS사의 IE 브라우저만의 지원
- 리눅스 및 Chrome 사용 개발자 멀티 브라우저 지원 요청 지속
- 국가별 시간 표시 기능 미제공으로 해외에서의 개선 요청 다수
-
- 2. 멀티브라우저, 지역별 시간 적용 프로젝트 정의
- 멀티브라우저 지원을 위한 Web Standard 적용
- 대상 브라우저:Chrome, Edge, Firefox, Safari
- 사용자의 지역별 시간 표시 기능 적용
- 영업대표: 홍길동, pm: 홍길동, 고객사: 00전자(주)
- 사업기간: 2020-01-02 ~ 2020-12-31
첨부파일: 000.pdf, xxx.pptx
- 문서 메타데이터 추출(DB참조)
- 영업대표: 홍길도 (조직: 000그룹)
- PM: 홍길동
- 고객사: 00전자(주)
- 카테고리: 사업정보
- 첨부파일의 텍스트 추출
- 텍스트 파일 (pdf, doc file, ppt file): 오픈소스 활용해 텍스트 분리한 후 분석
- 이미지(jpg, png등): OCR 기술을 이용해 이미지를 텍스트로 변환 한 후 분석
지식 정보 데이터와 연결된 첨부파일에서 비정형 텍스트 데이터를 가져온 다음, 의미 있는 개체명들과 그들 간의 관계를 AI 기반 자연어 처리 기술을 이용해 추출합니다. 개체명 인식 기술(Named Entity
Recognition)은 비정형 텍스트에 포함된 인명, 단체명, 지명 등 미리 정의된 분류에 맞는 단어들을 추출하는 기술로, 여기에서 추출된 단어들은 지식 그래프상의 정점들이 됩니다. SDS Insight
Engine의 개체명 인식 기술은 딥러닝 기술과 사전 기반 방법을 상호 보완적으로 사용한다는 특징을 갖고 있습니다. 이는 딥러닝 기반으로 모델이 문맥을 이해함에 따라 학습하지 않은 새로운 회사명이나 인물명이라도
유연하게 인식이 가능하다는 점과 때로는 인문학, 경영, 의학, 금융과 같이 전혀 새로운 도메인의 문서를 접하게 되더라도 사전을 커스터마이징 해 유연하게 대처할 수 있다는 장점을 함께 갖고 있습니다. 또한 지식
그래프에 개체명 간의 관계를 정의할 필요가 있을 때, AI 기반 관계 추출 모델이 문맥을 참조하여 개체명 사이의 가장 적합한 관계를 선택합니다.

-
- 1. 배경
- 현재 MS사의 IE 브라우저만의 지원
- 리눅스 및 Chrome 사용 개발자 멀티 브라우저 지원 요청 지속
- 국가별 시간 표시 기능 미제공으로 해외에서의 개선 요청 다수
-
- 2. 멀티브라우저, 지역별 시간 적용 프로젝트 정의
- 멀티브라우저 지원을 위한 Web Standard 적용
- 대상 브라우저:Chrome, Edge, Firefox, Safari
- 사용자의 지역별 시간 표시 기능 적용
- 영업대표: 홍길동, pm: 홍길동, 고객사: 00전자(주)
- 사업기간: 2020-01-02 ~ 2020-12-31
첨부파일: 000.pdf, xxx.pptx
딥러닝 기반 개체명 인식- 딥러닝 기반 관계 추출
- 관계 후보 중 개체명 사이의 관계로 가장 적합한 것을 문맥을 참조해 선택
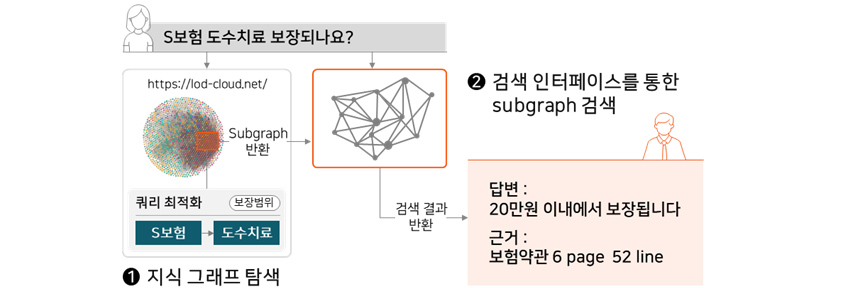
검색 고도화, 개인화 추천, QA 시스템 등의 Application API
지식 그래프를 QA 시스템이나 자연어 기반 검색 고도화 등에 적용할 수 있는 Application API를 제공합니다. 삼성SDS 연구소가 보유하고 있는 세계 1위 수준의 Multi-hop QA (복수의 문서를
검토한 후 분석 또는 추론해야 대답이 가능한 QA 태스크)와 한국어 기계독해 기술(MRC)을 바탕으로 차별화된 지식 그래프 활용 기술을 제공합니다.
삼성SDS QA 기술에 관한 자세한 설명과 차별점은 ‘복잡한 표도 이해하는 똑똑한 QA 모델’을 참조해 보실 것을 제안합니다. 개인화 추천 역시 지식 그래프를 활용할 수 있는 대상 중 하나입니다.
개인화 추천 알고리즘을 통한 추천 결과와 연관성 있는 정보를 지식 그래프에서 찾음으로써 추천 시스템의 한계점을 보완할 수 있습니다. 실제 검색 고도화와 개인화 추천에 지식 그래프를 제공한 예시는 “4.
비즈니스 사례”에서 보실 수 있습니다.
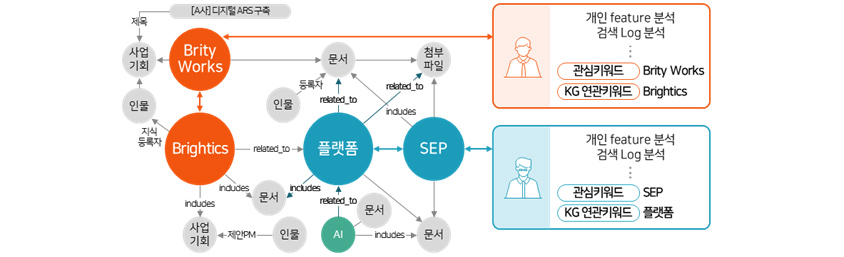 [그림 9] 지식 그래프를 이용한 개인화 추천 키워드 확장
[그림 9] 지식 그래프를 이용한 개인화 추천 키워드 확장
 [그림 10] 질의/응답 시스템(Question Answering System)
[그림 10] 질의/응답 시스템(Question Answering System)
4. 비즈니스 사례
삼성SDS 지식관리시스템 검색 고도화 및 지식 추천 서비스
지식 데이터베이스를 기반으로 다양한 경영 이슈들을 해결하고 의사결정을 진행하는 지식 경영이 글로벌 경영 트렌드가 되고 있습니다. 이에 기업이 보유하고 있는 다양한 지식 문서들을 통합 관리하고 검색하는 기술이
어느 때보다 중요해지고 있습니다.
엔터프라이즈 검색에 있어서 지식 그래프를 활용하면 기업이 보유하고 있는 기술과 사업에 관한 수많은 문서를 검색할 때, 단순히 해당 문서뿐만 아니라 연관된 다양한 정보를 같이 보여줄 수 있어서 지식 그래프를 이용한
검색은 더욱 진가를 발휘할 수 있습니다.
삼성SDS는 이와 같은 글로벌 트렌드에 맞춰 지식포털시스템(ARISAM)에 지식 그래프 기반 검색 고도화와 지식 추천 서비스를 적용했습니다. SDS Insight Engine을 통해 28개의 각종 사이트에 흩어져
있는 사업 기회, 제안서/프로젝트 산출물 등의 문서와 문서에 포함된 메타데이터, 다양한 포맷의 첨부파일을 통합 분석하여 하나의 지식 그래프 구조를 만들었습니다. 그리고 검색 창에 질의가 들어오면 지식 그래프에서
관련 키워드, 관련 사업 정보, 관련 임직원 정보, 관련 추천 지식을 지식 그래프에서 가져와 결과 화면에 추가로 정보를 표시하도록 구성하였습니다.
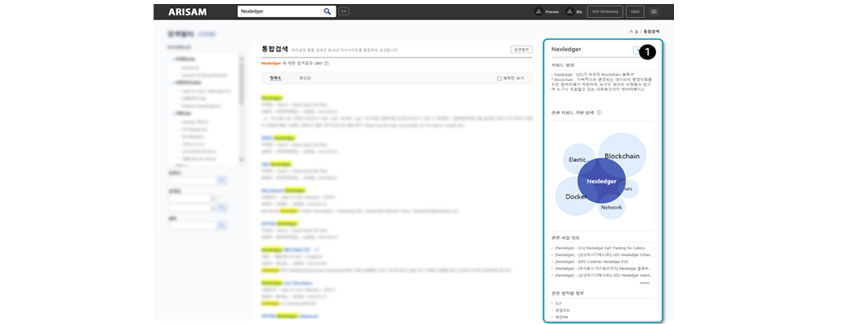 [그림 11] 지식 그래프를 활용한 지식포털 검색 고도화 사례
[그림 11] 지식 그래프를 활용한 지식포털 검색 고도화 사례(① 지식 그래프에서 추출한 관련 키워드 맵, 관련 사업 정보, 관련 임직원 정보, 관련 추천 지식을 제공)
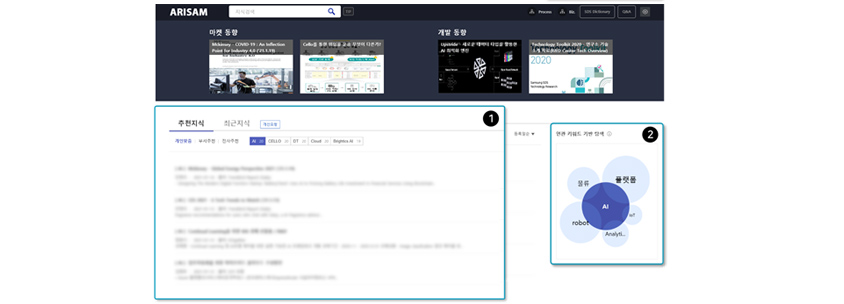 [그림 12] 개인 관심 키워드 기반 지식 추천 서비스
[그림 12] 개인 관심 키워드 기반 지식 추천 서비스(① 개인 맞춤, 부서추천, 전사추천 키워드 기반 추천지식 제공, ② 연관 키워드 맵 제공)
5. 맺음말
지식 그래프는 성장 단계 있는 기술이기 때문에, 실제 서비스에 적용하기 위해서는 많은 준비가 필요합니다. 어떤 데이터를 사용하여 어떤 서비스를 제공할 것인지 구체적인 기획이 선행되어야 하고, 지식 그래프에 어떤
내용을 축적할 것인지 설계가 필요합니다. 구축 및 운영 단계에서는 지속해서 지식의 품질을 관리하기 위한 지식 엔지니어가 필요하기도 합니다.
이런 준비 과정을 통해서 다양한 연결 관계를 유연하게 탐색할 수 있는 기능을 정보 서비스에 부여할 수 있고, 기존의 서비스가 제공할 수 없었던 인사이트를 제공할 수 있을 것으로 기대합니다.
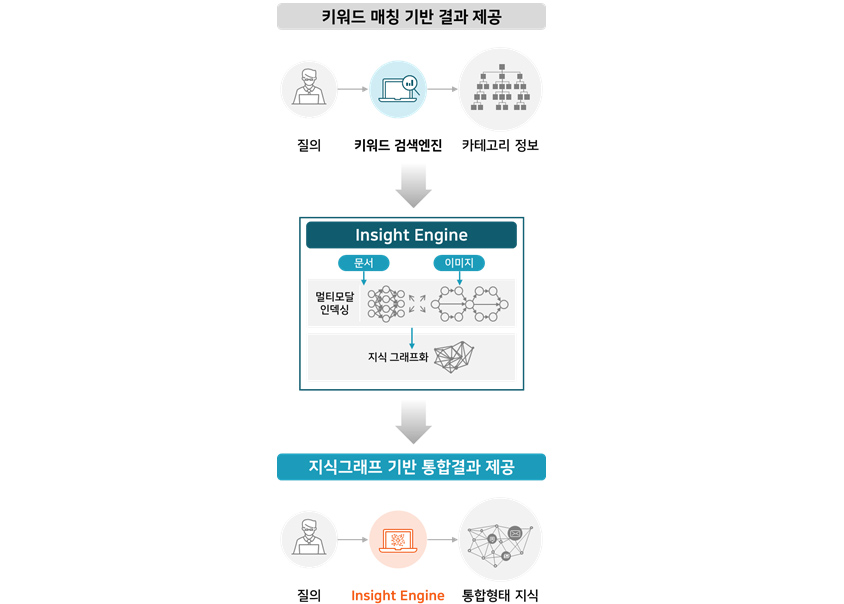 [그림 13] Insight Engine - AI 기반으로 멀티모달 데이터 간 관계를 그래프화하여 인덱싱
[그림 13] Insight Engine - AI 기반으로 멀티모달 데이터 간 관계를 그래프화하여 인덱싱(데이터의 의미와 사용자의 의도를 파악하여 개인화된 통합 지식으로 제공)
 Knowledge Graph 기반지식검색 - 지식 그래프 기반 지식검색
Knowledge Graph 기반지식검색 - 지식 그래프 기반 지식검색 동영상 보기
References
[1] https://developer.apple.com/library/archive/documentation/UserExperience/Conceptual/SearchKitConcepts/searchKit_basics/searchKit_basics.html
[2] http://snap.stanford.edu/decagon
[3] https://www.gartner.com/smarterwithgartner/gartner-top-10-data-analytics-trends/
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에게 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의 없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
![]()

삼성SDS 연구소 ML연구팀
뇌공학을 전공한 머신러닝 기반 모델 및 솔루션 연구개발자로, AI 자연어 처리 기술을 바탕으로 한 지식 그래프 구축과 검색 고도화 분야를 연구하고 있습니다.
Technology Toolkit 2021에 소개한 기술에 대해 문의사항이 있으시거나, 아이디어, 개선사항 등 의견이 있으시면, techtoolkit@samsung.com으로 연락해 주세요.