

스마트팩토리(Industry 4.0)는 공장의 환경안전/마케팅/설계/공정/출하를 자동화하고 품질과 성능을 최적화하기 위해 가상(컴퓨터)과 현실세계(공장)가 융합(사물인터넷)된 지능형 자동화 플랫폼입니다. 이 분야의 선두주자인 지멘스(SIEMENS)의 암베르크(Amberg) 공장은 가상현실 융합시스템(CPS: Cyber Physical System)을 통해 생산량의 4분의 3을 자동화하고 있습니다. 하지만 이러한 글로벌 선진업체들도 데이터 기반의 수집-분석-제어 자동화를 통한 공정이 가시적인 효과를 내기까지는 생각보다 많은 비용과 시간이 소요된다고 말합니다.
한때 빅데이터의 장밋빛 미래만을 보고 무분별하게 데이터베이스화를 추진하던 기업들은 Industry 4.0 시점에서 기존의 접근 방법을 버리고, ‘어떤’ 데이터를 ‘얼마나’, ‘어떻게’ 인공지능(AI)화할 것인가에 대한 새로운 방법론을 찾아 나섰습니다. 알파고로 증명된 최첨단 AI가 제조업에서는 즉각적인 성과를 보이지 못하고 있기 때문이죠.
데이터 수집 측면을 살펴보면, 제조 마케팅과 환경안전 데이터는 관측 불가능한 인자가 대부분이라서 부분적인 수집만 가능합니다. 또, R&D(설계) 데이터는 빠른 주기로 변경되는 제품을 개발한다는 점에서 기존 데이터들의 가치가 낮고, 비정형(도면, 설계 노하우) 형식이라 수치화가 어렵고, 물리(충돌, 풍동, 열, 전자파, 수명)실험 비용 또한 높아서 유의한 분석 결과를 내기가 어렵습니다.
금형 이후 양산공정은 통계적 품질/수율 분석에 대한 요구가 있어왔기에 일찍이 기초 수집 체계를 갖추어 놓은 업체들이 많습니다. 하지만 더 세밀한 계측이 필요하며, 실시간으로 빅데이터를 처리(매일 수백 GB 이상)하기엔 미흡하고, 로그/이미지/수치형 등 다양한 유형의 데이터가 혼재되어 있으며, 수천 인자들 간 정합성 문제 등 분석 전에 해결해야 할 난관이 많습니다. 또한 분석 결과가 나왔더라도 통계적 상관성(수치적 상관성)을 밝혀낸 것이지 물리적 인과관계(원인-결과)까지 증명된 것은 아닌 경우가 대부분입니다.
이러한 문제로 스마트팩토리는 ‘마케팅에서 출하 전까지의 프로세스에 대해 분석-예측-최적화하는 다분야 통합 AI’라는 목표와 달리, 실제로는 부분적으로만 적용하고 있습니다. 이제부터 AI 기반 환경안전기술인 Smart Inspection을 살펴보면서 현장의 어려움을 공유하겠습니다.
[Environmental Safety - Smart Inspection]
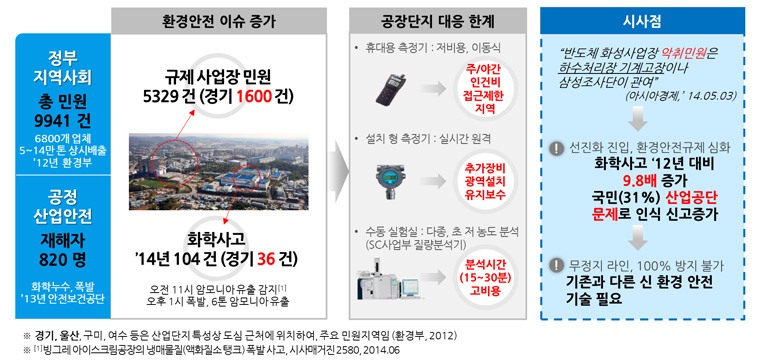 [그림1] 국내 환경안전 이슈
[그림1] 국내 환경안전 이슈
화학 및 산업단지는 업종 특성상 도심 근처에 위치하는데, 환경부에 따르면 유해가스 유출에 대한 민원은 매년 11.5% 증가하고 있습니다. 원인은 공정 문제 미감지, 접근 불가 지역의 설비 파손 등입니다.
따라서 환경 모니터링을 통한 사전 예방의 중요성이 요구되지만, 현실적으로 거의 이루어지지 못하고 있습니다. 화학단지의 경우, 민원발생 시 대부분 협동 수사로 대응하고, 경계부지와 내부에는 전자코(electronic nose) 및 초미세 계측(GC/MS) 장비가 설치되어 있으나 장비 자체가 고가(1천만~2억)인 이유로 광역 설치가 어려우며, 포집 후 장시간의 분석 시간(약 30분 이상)과 유지·보수 비용이 큰 문제입니다.
이러한 이슈로 고가 장비를 대체할 수 있는 저가 센서와 AI가 융합된 전자코 기술이 각광받고 있지만, 이 또한 다음과 같은 한계가 있습니다.
 [그림2] 전자코 (출처: http://www.coroflot.com/seanlee_yk)
[그림2] 전자코 (출처: http://www.coroflot.com/seanlee_yk)
첫째, 저가형 전자코(예: 반도체 저항 방식)는 냄새물질과 고분자 소자 간의 흡·탈착 특성을 이용한 방식으로, 주로 시계열 데이터 형태로(비 시계열 출력도 존재) 출력됩니다. Figaro, Alpha MOS 등의 센서 제조업체가 정한 임계치(주로 정상대기 기준)보다 센서 출력값이 3~5배 이상일 때 유해가스로 판단하는 방식이 일반적이며, 대부분 고농도(약 1ppm) 검출만 가능하다는 한계를 갖고 있습니다. 반면 사람은 악취(황화수소, 벤젠 등)를 ppb (0.001ppm) 수준에서 감지할 수 있습니다.
둘째, 전통적인 방식으로는 정상군과 비정상군 통계적 상대 거리(예: Mahalanobis distance), 머신러닝 기술로는 시그널 차원 축소(노이즈 제거, 주요 인자 선정) 또는 스펙트럼 분해 후 기계학습(인공신경망)을 통한 분류 등 다양한 기법들이 있습니다. 하지만 이러한 방식들은 대부분 안정된 실험실에서만 유효하거나, 고농도일 경우에만 가능하다는 한계를 보입니다.
최근(‘17.07) 앤드루 응(Andrew Ng)이 ECG(Electrocardiogram, 심전도) 데이터에 최신 AI 기술인 딥러닝(37 Layer)을 적용하여 심장부정맥을 전문가보다 더 잘 판별하는 결과를 보여준 사례도 있었습니다. 이러한 딥러닝 기술을 그대로 후각센서에 적용할 수 있을 듯하지만, 위 사례의 경우 ①낮은 환경외란, ②측정 조건의 정상상태 최대 보장(움직이지 않음, 측정 위치 고정), ③장비의 고분해능(높은 해상력)이라는 3가지 조건하에 딥러닝이 적용됐다는 점 때문에 저가 센서에 그대로 적용하긴 어렵습니다.
여기서 주목할 점은 얼굴인식, 알파고와 같은 AI 성공사례 대부분이 환경외란(environmental disturbances)이 적을수록 높은 성과를 보였다는 것입니다. 즉, 통제된(under-controlled) 환경에서의 AI 기술의 적용이었죠.
,
현재 최고 수준을 보이는 이미지 인식 영역조차도 환경외란에 의해 여전히 큰 오류를 범하고 있음이 MIT Technology Review(‘17.10)를 통해 확인되었습니다. 이 자료의 실험 결과를 보면, 이미지 내 1개의 pixel만 변경해도 74%, 5개의 pixel을 변경하면 87% 이상의 인식 결과가 틀린 이미지로 나타납니다. 이 정도면 개를 자동차로 인식하는 수준입니다. 사람이라면 픽셀 하나가 변경되었다고 개를 자동차로 오인할까요? 위 방식들의 인공지능 학습이 얼마나 ill-Condition(불량 조건)에서 이뤄졌는지 생각해 볼 필요가 있습니다.
강화 학습의 대표 사례인 딥마인드의 알파고(판, 리, 마스터, 제로)도 바둑이라는 컴퓨터 게임과 같이 통제된 조건에서 좋은 성과를 보였습니다. 즉, 수많은 환경적 외란(온도, 습도, 자기장, 열, 압력, 소음 등)과 불확실성이 존재하는 실제 환경은 인공지능 기술을 무용지물로 만들어 버리며, 이에 비추어 볼 때 인간 두뇌의 학습 방식은 엄청난 일반화(generalization) 프로세스로 동작한다는 것을 알 수 있습니다.

[AI의 한계, 변화하는 정상상태(Steady-State)]
AI의 수학모델은 대부분 정적인 정상상태로 정의되며, 보통 정규분포 내에서 시간에 따라 크게 변하지 않는 모델을 의미합니다. 정상상태를 비선형 모델로 표현하는 표준화된 결정론적, 확률적 방법이 있지만 효과대비 사용하기가 어려워 선형모델을 사용하는데, 이는 실제 물리현상의 비선형성을 인식하지 못한다는 한계를 가지고 있습니다.
간단한 예로 Y(가스센서 출력값)는 X(가스)와 Z(외란: 정상상태, Steady)의 주 영향과 교호작용이 결합된 형태입니다. X(가스)가 없더라도 Z(온도, 습도)가 변화하면 Y(가스센서 출력값)가 증가하며, 정상상태 대비 3배 이상 출력 시, 이를 유해가스라 판정하는 잘못된 알림이 발생합니다. 또, Z는 비관측인자이며, 단순 백색잡음이 아니라 시간에 따른 센서의 성능 저하 현상 및 H/W 불확실성 요소가 결합된 형태이기에 수학적 모델화가 매우 어렵습니다.
그렇다면 동적인 정상상태와 관련된 관측인자와 비관측인자들의 불확실성을 어떻게 기계학습 해야 할까요? 이는 안정적(Robust)이고 실용적(Practical)인 인공지능 기술을 위해 선결해야 할 숙제입니다.
[실제 환경의 비관측인자들]
센서업체에 따르면 가스센서의 영향인자는 가스 외에 온도, 습도, 자기장 등 수십 종으로 정리되어 있습니다. 저가(低價)의 가스/온도/습도센서(3종, 각 만 원)로 2주간 연속 측정했을 때, 가스-온도-습도는 평균적으로 90% 상관관계를 보입니다.
매우 안정적이고 정상적인 상태의 실험실에서는 기계학습 이후 예측오차가 0.1~1% 정도입니다. 하지만 시간이 지날수록 불확실성 인자들인 센서 성능 저하(Sensor Drift), 비균질 소재 함유량(동일 센서도 소재 함유량이 다름), 센서 히스테리시스(Hysteresis: 센서 출력값의 상승과 하락 시 다른 값을 보이는 비선형 특성) 인자 영향으로 예측오차가 증가하기 시작합니다.
이러한 불확실성 인자들의 정밀한 관측은 불가능하며, 자기상관/교호작용의 합산된 결과인 ‘센서 값’만 관측이 가능하기 때문에, 센서 값에서 불확실성 요소를 역추정하여 정상상태를 자동학습하는 기술이 필요합니다.
우리는 어느 센서에나 있는 비균질 소재 함유량 문제를 해결하기 위해 정상 대기 상태에서 5개의 동일 센서를 동시 측정하여 각 센서마다 센서 반응 보정법을 개발하였습니다. 그리고 히스테리시스와 센서 드리프트 교호작용에 의해 오차가 지속 증가하는 문제를 해결하기 위해 정상상태의 95% 가우시안 분포(Gaussian distribution) 신뢰구간 안쪽의 데이터로 정상상태를 학습하였습니다. 그리고 새롭게 측정되는 데이터 중 정규성을 가정하여 몬테카를로 샘플링으로 샘플을 추출한 후, 두 집단 간 다변량 기대 통계치를 통하여 조건부 베이지안(Bayesian) 업데이트를 수행하였습니다. 이렇게 함으로써 불확실성을 고려한 센서의 동적 정상상태를 학습할 수 있었습니다.
[통계적 실시간 상태추정 기술]
이와 같이 다변량 통계분석법에 의한 상태추정과 머신러닝을 조합한 기법을 통계적 기계학습법(Statistical Machine Learning)이라 합니다. 이를 기반으로 복합센서(가스, 온도, 습도) 데이터를 통해 정확하게 정상상태를 예측한 뒤, 이 예측구간을 초과한 수치가 정상대기 수치와 누적 합계(Cumulative Sum) 형태로 3 Sigma를 초과하는 순간 유해가스로 판정하도록 하였습니다.
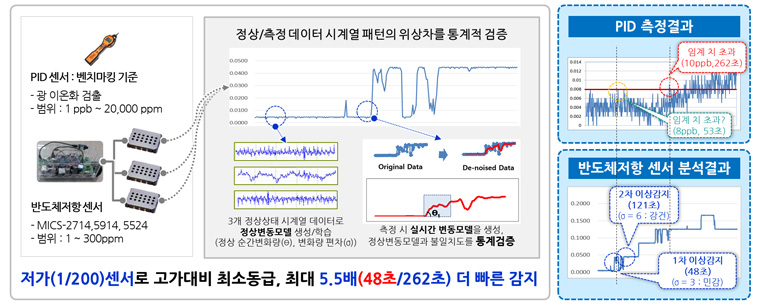 [그림3] 미세유해가스 조기 감지
[그림3] 미세유해가스 조기 감지
이 시스템으로 미세가스(ppb)를 동시 측정한 결과, 위의 그림과 같이 고가 센서 장비와 최소 동일한 검출력을 가지거나 안정된 환경의 경우 2.5배 빠른 조기 감지 검출력을 보였으며, 고가의 한계인 24시간 모니터링 문제도 해결할 수 있음을 확인했습니다.
[자율이동 측정기술]
두 번째로 화학공장이나 공장단지의 크기는 축구장 크기 이상이며, 이 넓은 공간을 실시간으로 감시할 수 있길 원했습니다. 그러나 위에서 설명한 기술로는 실시간과 정밀도 문제는 해결되지만 접촉식 센서 장비라는 점에서 광역 감지가 불가능하다는 한계를 가지고 있습니다.
우리는 광역 감지 사례로 유명한 ‘UAV(드론)로 가스 송유관의 누수를 검출했던 사례'에 착안하여, UAV에 복합센서를 장착하고, 이동측정을 하면서 유해가스 검출을 재연해 보았습니다. 물론 로터의 영향을 받아 농도 산정 정확성에는 한계가 있지만, 유해가스 발생 지점은 정확히 찾을 수 있었습니다
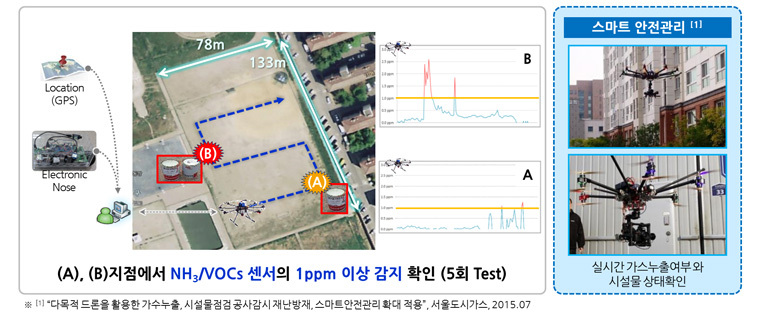 [그림4] 실시간 자율이동측정
[그림4] 실시간 자율이동측정
일반적으로 유해가스 민원은 공장 외부의 주택가와 상가에서 발생하며, 시간이 지날수록 희석 작용으로 확인이 어렵다는 점 때문에 민원에 즉각 대응한다는 것이 공장 방침입니다.
하지만 즉각 대응하더라도 허공에 떠도는 유해가스(민원) 유출지가 공장인지, 맥도날드인지(실제 사건)를 확인하는 데 2주 이상 걸린다는 문제가 현업의 가장 큰 이슈로 지정되어 있으며, 이로 인해 “실시간 유해가스 역추적 기술”을 검토하게 되었습니다.
가장 먼저 실시간 자율 판단과 자율주행 기술의 조합, 간단한 로보틱스에 많이 쓰이는 순차적 행동 의사결정 기술인 강화학습을 떠올렸습니다. 하지만 아타리 2600(게임), 바둑과 같은 충분한 학습 데이터의 부재, 무수한 시행착오 비용과 시행착오에 의한 사고 위험성(충돌회피도 이슈)의 문제가 있었죠. 무엇보다 더 큰 문제는 대기확산과 비선형 환경 변화(풍향, 온도, 풍속, 습도, 진동)라는 물리현상이 강화학습의 상태 전이확률을 항상 틀리게 만들며, 벨만 방정식과 현재-미래의 보상 평균 추정을 위한 랜덤 샘플링(무수히 많은 시행착오)에 의한 긴 학습시간은 실시간 고속 추적이라는 요구 조건을 만족시키지 못했습니다.
따라서 강화학습의 기본 모델인 MDP(Markov Decision Process)를 제거하고, 가스센서 이동평균 값을 보상함수로 정의하고, 이를 최대화하는 행동(X, Y, Z)을 실시간으로 결정하도록 수정된 강화학습을 적용하였습니다. 제거한 모델(MDP) 대신 대기 확산 거동과 센서 불확실성을 고려하기 위해 3차원 공간(GPS)에 3개 실험점(Orthogonal Array)을 생성한 뒤 UAV로 이동측정하였으며, 3개 실험점 센서 값으로 공간 농도를 계산하는 근사 모델(Approximation Model)을 생성하였습니다. 이 모델로 방향벡터(Approximated Direction Vector)를 계산 후, 이 방향벡터로 점진 이동하면서 센서 값(보상 함수)이 이전 위치보다 낮아질 때까지 이동하는 Line Search를 적용하였습니다.
이 과정은 반복법(Iterative Method)으로 구현되었으며, 이전 대비 높은 농도점(Local Optimum)으로 이동한 경우 탐색 구간을 좁히고, 낮아진 농도점을 찾은 경우(잘못 탐색) 탐색 구간을 넓히는 신뢰구간을 정의하였으며, 신뢰구간과 보상 값 변화 비율을 UAV의 탐색 종료 조건으로 설정하였습니다. 이러한 자율주행 알고리즘을 구현하여 테스트한 결과 아래 그림과 같은 결과를 얻을 수 있었습니다.
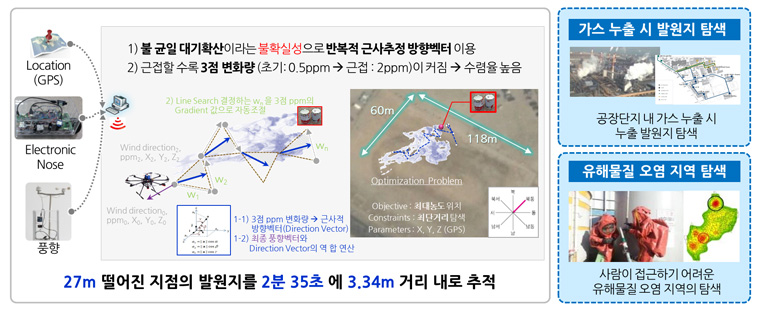 [그림5] 미지 발원지 역추적
[그림5] 미지 발원지 역추적
[맺음말]
딥러닝을 터닝포인트로 AI는 암흑기에서 부흥기로 재진입하였으며, 인공지능에 수조 원을 투자하는 시대가 도래했습니다. 사람들은 알파고의 성과만을 보고 인공지능에 대한 환상을 품기 시작하였고, 심지어 전문가들조차 딥러닝이 마스터 알고리즘으로써 모든 문제를 해결할 것처럼 말하기도 합니다.
 [그림6] 인공지능의 역사
[그림6] 인공지능의 역사
하지만 이는 이미지와 음성에 있어 실용성을 확인한 것일 뿐, 최고 수준의 이미지 인식 기술도 MIT Technology Review에서 지적한 대로 (교통 표지판에 붙은 스티커로 개와 자동차를 오판한다. 자율주행을 얼마나 신뢰할 것인가?) 노이즈를 무시할 수 있는 인간의 학습 방식과 얼마나 차이 나는지, 가야 할 길은 또 얼마나 먼지를 확인시켜 주었습니다.
따라서 도밍고스(P. Domingos) 교수의 마스터 알고리즘(어떤 데이터도 분석해 새로운 지식을 도출할 수 있는 현 인류가 상상할 수 있는 Super-Intelligent AI)이 인간을 뛰어넘는 시점은 정말 먼 훗날의 이야기일 거라고 생각합니다. 환상에만 집착하여 도메인지식과 현장 데이터가 중심이 되지 않은 AI 자체에만 집중한다면, 60년 전 마빈 민스키(Marvin Lee Minsky)에 의해서 무용지물 된 로센블래트(F. Rosenblatt)의 퍼셉트론(Perceptron) 사건과 암흑기가 또다시 재현될 것입니다.
따라서 현재의 인공지능 연구의 초점은 Super-Intelligent AI가 아닌, 현장의 자료(데이터)와 도메인 특성이 맞춰진 “인공지능 기반 자동화”여야 한다고 생각합니다. 다음 아티클에서는 인공지능 기반 자동화 집합체라고 불리는 ‘스마트 팩토리안(SMART FACTorian)’에 대해 살펴보겠습니다.
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
![]()

삼성SDS AI Analytics팀
대학원에서 기계공학 & 컴퓨터사이언스를 전공하였고 주요 연구분야는 Applied mathematics(응용수학) 기반 Manufacturing 데이터분석 및 최적화입니다. 현재 전자 및 관계사 데이터기반 무인설계기술과 공정최적제어 관련 컨설팅을 수행 중이며, 삼성SDS Brightics AI 알고리즘 중 Optimization 기술리더입니다. 관심분야는 능동학습(Active Learning)과 전이학습(Transfer Learning) 이용한 전통적인 AI기술 (강화학습을 비롯한 머신러닝)의 비효율성 해결과 자율학습 기술 연구 중입니다.