삼성 클라우드 플랫폼, 빅 데이터(Big Data)와 인공지능/머신러닝(AI/ML)의 이해
- 2023-06-01
- 작성자 임준영, 이수정



기업의 성공적인 디지털 전략 수행을 위해 인공지능과 빅데이터의 혁신적인 발전과 이 두 요소를 결합한 포괄적인 로드맵의 필요가 더욱 강조되고 있습니다. 최근 인공지능은 계산과 정보 수집의 단계를 넘어 학습 능력, 지각 능력, 추론 능력 및 자연 언어의 이해 능력 등과 같이 인간의 지능 수준에 도달하는 성과를 보이고 있습니다. 기업의 디지털 전환에 대한 빅데이터와 인공지능 관련 비즈니스에 대응하기 위하여 삼성 클라우드 플랫폼 (Samsung Cloud Platform, SCP)에서 제공하는 데이터 애널리틱스/인공지능/머신러닝(Data Analytics/AI/ML) 상품들에 대해 살펴보겠습니다.
빅데이터와 AI의 시대가 도래하다.
코로나19 이후 데이터의 활용은 그 영향력과 사용범위가 지속적으로 확장되면서 모든 사회영역 즉, 금융, 교육, 공공, 생산, 교통, 생활, 소비 등 산업 전반에 영향을 끼치고 있습니다.
또한, 점차적으로 비대면 환경의 필요성이 확대되고 디지털 전환(DX)의 움직임이 활발해지면서, 기업의 성공적인 디지털 전략 수행을 위한 인공지능과 빅데이터의 혁신적인 발전과 이 두 요소를 결합한 포괄적인 로드맵의 필요가 강조되고 있습니다.
빅데이터와 인공지능은 상호 보완적인 관계를 유지하고 있습니다. 최근 인공지능은 계산과 정보 수집의 단계를 넘어 학습 능력, 지각 능력, 추론 능력, 자연언어의 이해 능력 등과 같이 인간의 지능 수준에 도달하는 성과를 보이고 있습니다. 이에 삼성SDS는 기업의 디지털 전환에 대한 빅데이터와 인공지능 관련 비즈니스에 대응하기 위하여 데이터 애널리틱스/인공지능/머신러닝(Data Analytics/AI/ML) 상품군을 준비하였습니다.
빅데이터 및 AI/ML 활용은 어떤 단계로 진행될까?
1) 데이터 수집(추출, 변환 및 적재) 단계
전통적인 데이터 분석을 위한 데이터 수집은 크게 세 단계로 진행됩니다. 첫 번째는 현업 사용자의 요청에 따라 여러 가지 데이터 소스에서 데이터를 추출(Extract)합니다. 두 번째는 대상 데이터 시스템 및 해당 시스템의 다른 데이터와 통합할 수 있도록 정보의 구조를 변경하는 변환(Transform) 과정을 거칩니다.
마지막으로 세 번째 단계는 데이터 스토리지 시스템에 적재(Load)하는 방식으로 진행됩니다. 데이터 수집은 가장 많은 시간이 소요되며 방법에 따라 최종 결과물이 크게 달라지기도 합니다.
점점 어려워지는 현대의 데이터 수집 과정
최근에는 데이터 소스가 훨씬 다양해졌고, 데이터의 사이즈가 더욱 커졌으며, 데이터 분석 범위도 넓어져 더 많은 데이터 처리를 요구 받는 상황이 되었습니다. 게다가 ETL(추출, 변환, 적재)과정은 데이터의 양이 많아지면 변환하는 시간 역시 오래 걸리기 때문에, 데이터가 증가하는 상황에서는 한계가 발생하기 시작합니다. 변환하는 시간으로 실시간 대규모 데이터 감당이 어려워진 까닭입니다. 따라서, 현재는 우선 데이터를 저장하고, 이 데이터를 어떻게 쓸 지에 대한 것은 데이터를 사용하는 시점에서 고민하는 데이터 레이크(Data Lake) 개념으로 데이터 분석 활용의 흐름이 변했습니다. 마치, 호수처럼 데이터 웨어하우스 앞단에 모든 데이터를 다 저장해 두고 그 중 일부만 용도에 따라 변환하여 사용하는 방식입니다.
[여기서 잠깐!] 데이터 레이크(DataLake)와 데이터 웨어하우스(Data warehouse)
데이터 레이크: 데이터 레이크는 조직에서 수집한 정형, 반정형, 비정형 데이터를 특정 목적을 위해 처리하지 않은, 원시 형태(raw data)로 저장하는 단일한 데이터 저장소를 의미합니다.
데이터 웨어하우스: 회사의 각 사업부문에서 수집된 모든 자료 또는 중요한 자료에 관한 중앙 창고로, 데이터 웨어 하우스에 데이터를 저장하기 전에는 데이터에 어떤 형태와 구조(스키마)가 필요합니다.
2) 데이터 준비(탐색/변환/처리) 단계
현대적 데이터 아키텍처는 데이터 탐색/변환/처리를 위해서 하나의 대규모 솔루션을 제공하는 경우 매우 비효율적입니다. 이러한 하나의 대규모 솔루션에서 발생하는 과도한 커뮤니케이션은 잠재적인 성능 문제를 넘어 강한 결합을 초래할 수 있습니다. 특정 서비스를 변경할 때는 한 곳에서 변경하고 가능한 한 신속하게 릴리즈 할 수 있어야 합니다. 이러한 데이터 서비스는 서로 연관된 서비스가 한 곳에 모이고 다른 경계와는 가능한 느슨하게 결합(loose coupling)되면서도 강한 응집력(high cohesion)을 가져야 합니다. 최근에는 데이터 레이크와 데이터 웨어하우스를 제공하면서 데이터 레이크를 데이터 웨어하우스에 통합하는 것이 아니라, 데이터 레이크, 데이터 웨어하우스 및 목적 별 스토어를 통합할 수 있도록 간편한 데이터 이동이 필요합니다.
삼성 클라우드 플랫폼에서 제공되는 상품을 통해 고객은 확장 가능한 데이터 레이크를 신속하게 구축하고, 광범위한 데이터 서비스를 사용하며, 데이터 보안 및 거버넌스를 제공받을 수 있습니다. 또한, 저렴한 비용으로 성능 저하 없이 시스템을 확장하고 조직의 경계를 넘어 손쉽게 데이터를 공유함으로써 대규모 데이터 환경에서 신속하고 민첩하게 의사 결정을 내릴 수 있습니다.
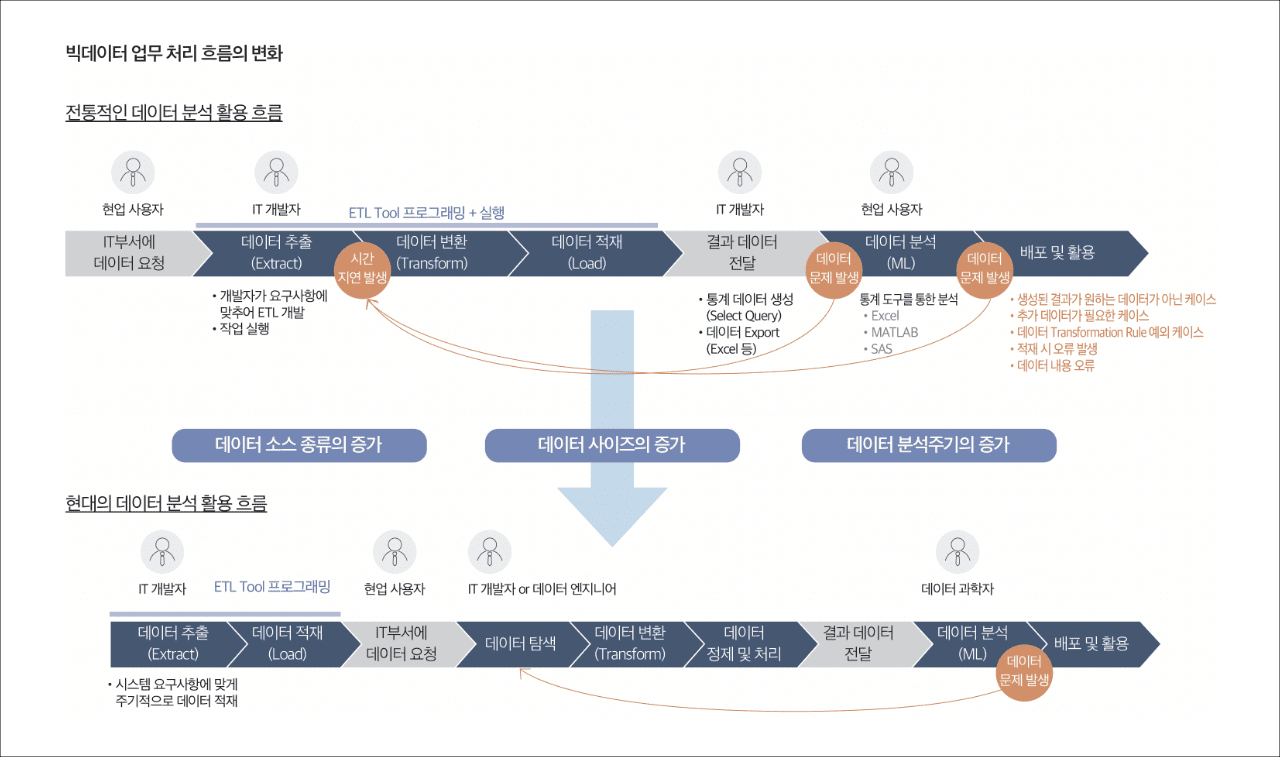
- 현업 사용자: IT 부서에 데이터 요청
- IT 개발자 ETL Tool 프로그래밍 + 실행
- 데이터 추출(Extract) *시간 지연 발생
- 개발자가 요구사항에 맞추어 ETL 개발
- 작업 실행
- 데이터 변환 (Transform)
- 테이터 적재 (Load)
- IT 개발자
- 결과 데이터 전달 * 데이터 문제 발생
- 통계 데이터 생성(Select Query)
- 데이터 Export (Excel)
- 현업 사용자
- 데이터 분석(ML) * 데이터 문제 발생
- 통계 도구를 통한 분석
- Excel
- MATLAB
- SAS
- 배포 및 활용
- 생성된 결과가 원하는 데이터가 아닌 케이스
- 추가 데이터가 필요한 케이스
- 데이터 Transformation Rule 예외 케이스
- 적재시 오류 발생
- 데이터 내용 오류
- 데이터 분석(ML) * 데이터 문제 발생
- IT 개발자 (ETL Tool 프로그램)
- 데이터 추풀(Extract): 시스템 요구사항에 맞게 주기적으로 데이터 적재
- 데이터 적재(Load)
- 현업 사용자: IT 부서에 데이터 요청
- IT 개발자 or 데이터 엔지니어
- 데이터 탐색
- 데이터 변환(Transform)
- 데이터 정제 및 처리
- 현업 사용자: 결과 데이터 전달
- 데이터 과학자
- 데이터 분석(ML) * 데이터 문제 발생
- 배포 및 활용
- 데이터 소스 종류의 증가
- 데이터 사이즈 증가
- 데이터 분석주기의 증가
3) 데이터 분석(ML) 및 모델 배포 단계
통합된 데이터의 준비가 끝나면 머신 러닝(Machine Learning)을 통한 기업 내의 통합 분석 환경이 필요합니다. 하지만 기업에서 AI, 혹은 빅데이터를 효과적으로 활용하기 위한 'MLOps' 환경 구현을 위한 자체적 노력은 아래와 같이 큰 어려움을 동반합니다.
첫째, 대규모, 고성능 인프라의 부재입니다. 모델 구축·배포 또는 대규모 데이터셋 처리를 위한 고성능/GPU 컴퓨팅이 필요한데, 자체적으로 온디맨드(On-demand) 환경에서 모든 자원을 갖춰 진행하는 것은 비효율적일 뿐만 아니라 ROI 관점에서 자본 지출 리스크가 큽니다.
둘째, MLOps 관련 다양한 기술 스택, 소프트웨어, 전문가의 부재입니다. MLOps는 컨테이너, 데이터 수집/전처리, 모델링, 모델 트레이닝, 모델 배포 등 상용화를 위한 광범위한 기술 Layer를 포함합니다. 이런 다양한 레이어를 커버하기 위해서는 소프트웨어와 전문가들의 기술이 필요합니다. 일반 기업/기관이 AI/ML 전 영역에 대해 자체적으로 기술/인력 확보하여 구축하는 것은 상당히 비현실적인 대안입니다.
셋째, MLOps는 기존과는 다른 개발 방식입니다. 기본적으로 머신러닝은 실패와 반복 작업을 가정하고 개발해야 합니다. 이는 일반적인 개발 환경이 아닌, 머신러닝을 위한 개발 환경, 즉 실험적 시도가 가능한 개발 환경 및 방법론의 적용이 필요하다는 의미입니다.
[여기서 잠깐!] MLOps란?
MLOps는 파일럿 단계를 지나 AI 서비스를 상품화하는 단계에 필요한 프로덕션 엔지니어링 기술입니다. AI의 본격적인 적용 확산으로 최근 주목을 받고 있으며, 이 기술은 ML에 DevOps 원칙을 적용한 것으로, ML 시스템 개발(Dev)과 ML 시스템 운영(Ops)을 통합하는 것을 목표로 합니다.
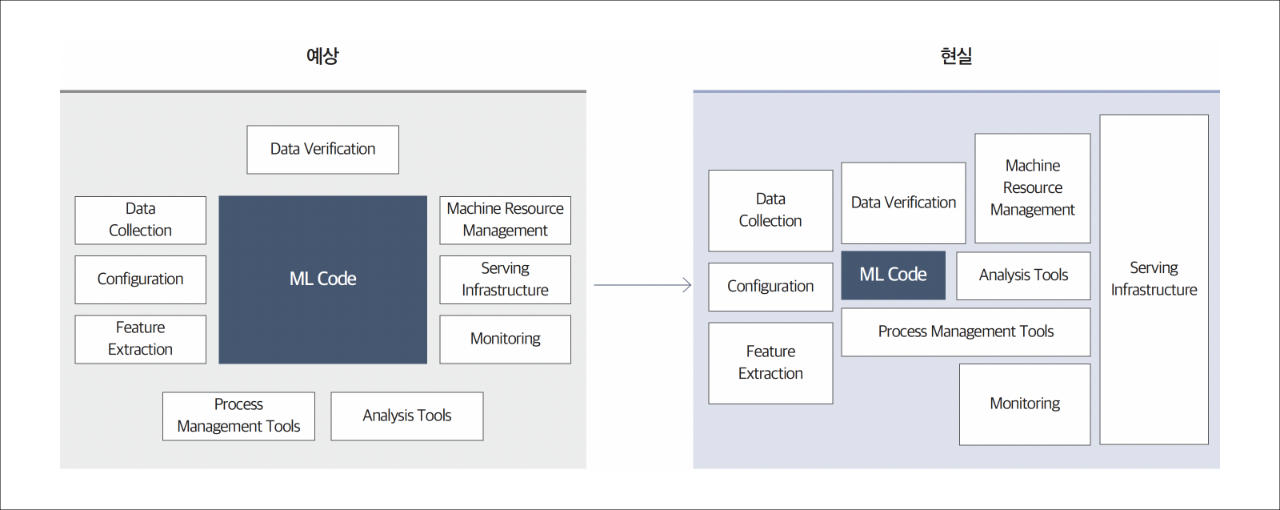
출처 : Hidden Technical Debt in Machine Learning Systems / Google , Inc.,2015
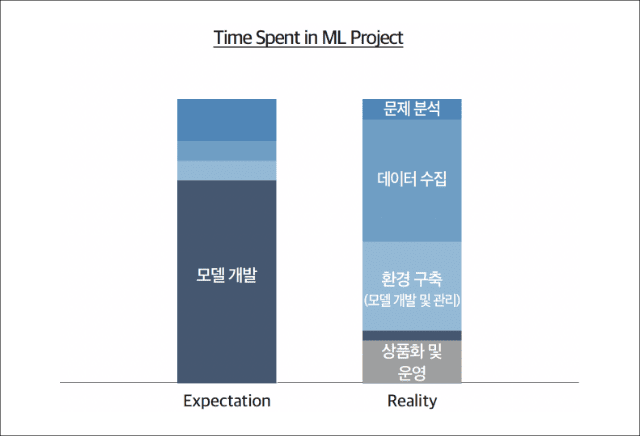
출처: Internal Google Survey
따라서 우리는 운영 비용(OPEX) 전환과 고객 본연의 업무 집중을 위해 클라우드 서비스를 통한 MLOps 환경 구현이 필요하다는 결론에 도달하게 되는데, AI&MLOps 플랫폼(AI&MLOps Platform)은 고객의 MLOps환경 구현을 위한 좋은 해결책이 될 수 있습니다.
이에 삼성 클라우드 플랫폼에서는 쿠브플로우(Kubeflow)를 삼성 클라우드 플랫폼 환경에 맞도록 구성하여 제공하고 있습니다. 쿠브플로우는 Google이 자사 AI 개발의 노하우를 오픈 소스로 공개한 쿠버네티스(Kubernetes) 기반의 MLOps 플랫폼입니다. 모델 개발, 훈련, 배포 및 운영 등의 복잡한 ML 워크플로우 실행을 쿠버네티스에서 Simple, Portable, Scalable 하게 지원합니다. 주요 이점으로는 개발에 집중할 수 있는 올인원(All-in-One) 서비스로 개발/배포하여 환경의 반복적인 구성 작업을 자동화 해주고 데이터 사이언티스트(Data Scientist)가 선호하는 텐서플로(Tensorflow), 파이토치(Pytorch) 등의 ML Framework 개발환경을 제공합니다. 거기에 다양한 ML Framework의 분산학습을 편리하게 수행하고, ML모델 개발/학습/배포 과정의 pipeline 구성이 가능하여 모델 학습에 편의성을 제공합니다. 쿠버네티스 기반으로 컨테이너 자동복구, 오토 스케일링(Auto-scaling), GPU 기반 스케줄링, GPU Fraction 등 운영 안정성과 유연성 또한 제공합니다.
[여기서 잠깐!] 쿠브플로우(Kubeflow)와 AI&MLOps 플랫폼(AI&MLOps Platform)
쿠브플로우(Kubeflow)는 Google이 자사 AI 노하우를 오픈 소스로 공개한 쿠버네티스 기반의 MLOps 플랫폼이며, 삼성 클라우드 플랫폼에서는 쿠브플로우를 삼성 클라우드 플랫폼 환경에 맞추어 쿠버네티스 기반의 머신 러닝 플랫폼 AI&MLOps 플랫폼을 제공하고 있습니다.
4) AI를 활용한 응용 API 서비스 단계
클라우드 기반의 AI 서비스를 활용하는 방식은 두 가지로 볼 수 있습니다. 전문 지식과 경험으로 훈련된 인력과 보유 데이터를 기반으로 한 ML 모델을 자체적으로 개발하여 활용하는 방식과 Pre-Trained 모델 기반의 API를 호출하여 활용하는 방식입니다. AI API 서비스는 후자의 경우로 ML을 개발하고 최적화할 필요 없이 API를 호출하여 서비스를 자유롭게 구성, 연계하여 비즈니스에 빠르게 적용할 수 있습니다. 기존에는 언어, 시각, 음성, 사고 등의 AI 각 영역의 핵심 기술을 모듈화해 범용적인 API 형태로 제공했다면 최근 CSP 사업자들은 의료, 금융 등 자사의 데이터 및 ML모델을 확보하여 고객에게 더 정확하고 특화된 AI API를 제공하고 있습니다.
빅데이터 및 AI/ML 활용을 위한 삼성 클라우드 플랫폼 상품은 어떤 것이 있나?
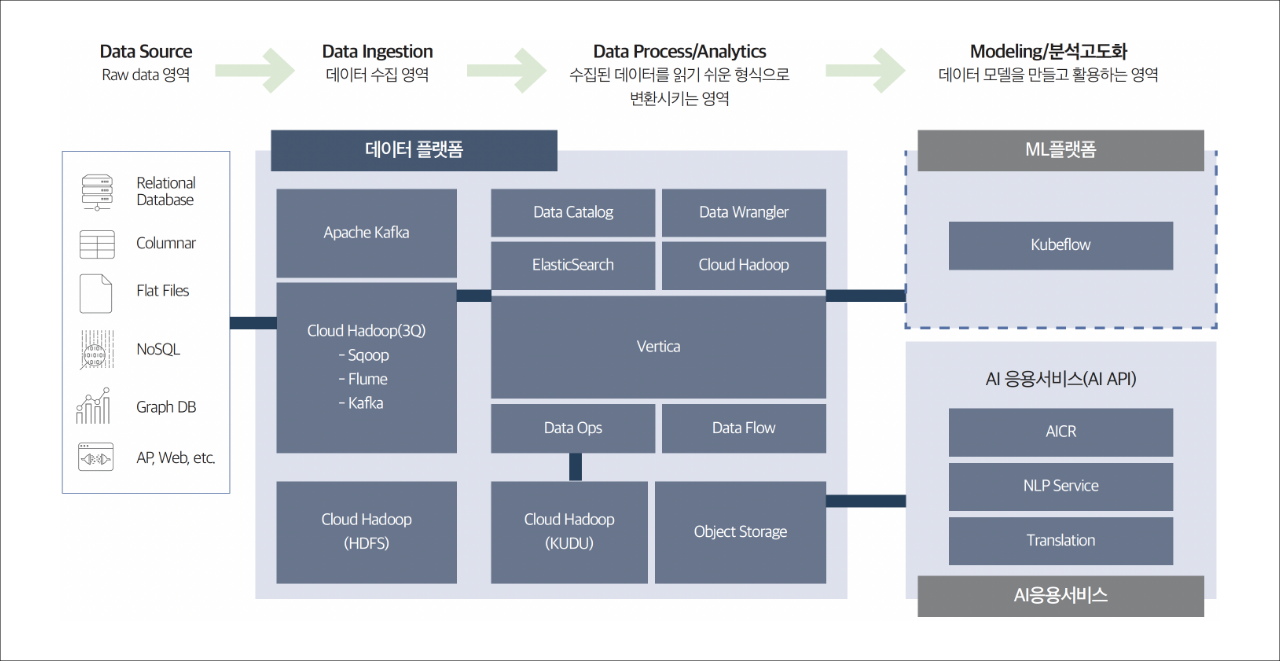
삼성 클라우드 플랫폼에서는 애널리틱스 상품군과 AI상품군을 제공하며 애널리틱스 상품군에서는 카프카(Kafka), 엘라스틱서치(Elasticsearch), 클라우드 하둡(Cloud Hadoop), 데이터 플로우(Data Flow), 데이터 옵스(Data Ops)상품등을 제공하고 AI 영역으로는 AI&MLOps 플랫폼(AI&MLOps Platform), AICR상품등을 제공합니다. 아래, 각 상품군별 주요 상품을 상세히 소개하겠습니다.
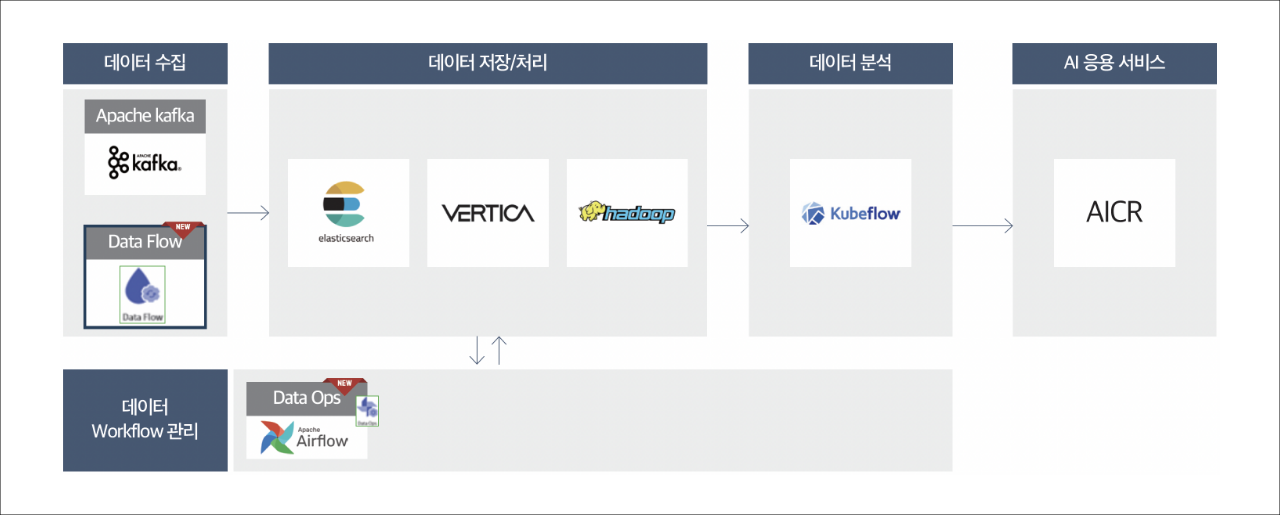
[삼성 클라우드 플랫폼의 애널리틱스 상품군과 AI 상품군을 활용한 데이터처리 흐름 예시]
1) 분산 환경에서의 데이터 처리를 위한 클라우드 하둡
삼성 클라우드 플랫폼은 빅데이터 저장, 처리 및 분석할 수 있도록 하둡(Hadoop) 기반의 데이터플랫폼을 제공합니다. 클라우드 하둡을 통해 소규모 컴퓨팅 자원을 활용하여 대용량 데이터의 클러스터링 및 병렬 처리가 가능합니다. 또한 아파치(Apache) 오픈소스를 기반으로 상호 호환성이 검증된 하둡 에코시스템(Hadoop Ecosystem)과 관리 환경을 제공하여 편리하게 사용할 수 있습니다. 방대한 양의 데이터들은 HDFS(Hadoop Distributed File System) 또는 오브젝트 스토리지(Object Storage)에 적재되며 데이터를 처리하고 분석하기 위한 다양한 오픈 소스들 역시 제공합니다.
클라우드 하둡의 특징
첫째, 손쉬운 빅데이터 분석 환경 구성이 가능합니다. 하둡 클러스터 생성을 위한 기존의 복잡한 인프라 작업 없이도 삼성 클라우드 플랫폼에서 자동화된 클러스터 설치를 통해 어디서든 서비스 사용이 가능합니다. 둘째, 다양한 오픈소스 프레임워크 설치를 지원하여 손쉬운 빅데이터 분석 시스템 구성이 가능합니다. 셋째, 안정적인 노드 관리가 가능합니다. 빅데이터 분석 시 클라우드 자원을 필요에 따라 노드 단위로 늘이거나 확장하여 사용할 수 있으며, 클러스터 생성 시 마스터 노드를 이중화로 구성하여 엔터프라이즈 서비스에 적합한 고가용성을 보장합니다. 넷째, 손쉬운 클러스터 관리가 가능합니다. 클러스터의 정보와 상태를 관리할 수 있는 통합 모니터링 대시보드를 제공하여, 다양한 시스템 리소스 차트 제공뿐 아니라 서비스 별 설정 버전 관리 및 최적 값을 추천하고 서비스 이상 동작을 감지, 진단하여 실시간 Alert으로 보다 안정적인 관리가 가능합니다.
다양한 패키지 제공
삼성 클라우드 플랫폼 클라우드 하둡은 필요한 에코시스템만 선택해서 구성할 수 있기 때문에 불필요한 자원 낭비를 방지하고 비용을 최적화할 수 있습니다. 또한, 서비스 운영 중에 에코시스템을 쉽고 빠르게 추가할 수도 있습니다. 거기에 데이터 레이크를 구성하는 다양한 서비스들을 세분화하여 구성할 수 있어 비즈니스 목적과 가치의 성공적 달성에 최적화된 클러스터로 구성할 수 있습니다.
클라우드 하둡에서 제공하는 에코시스템
| 구분 | 패키지명 | 서비스 |
|---|---|---|
| Default | Basic |
HDFS(3.2.0), YARN(3.2.0), Hbase(2.0.2), Hive(2.3.6/3.1.2), Tez(0.9.1), Hue(4.6.0), Solr(7.7.2), Spark(2.3.0), Livy(0.5.0), Kerberos(5-1.17.1), HAProxy(2.3.4), ZooKeeper(3.5.9), PostgreSQL(13.4), Ldap external |
| Option | Data Warehouse | Kudu(1.13.0) , Impala(3.4.0) |
| Data Ingestion | Sqoop(1.4.7), Kafka(2.7.1), Flume(1.9.0), Oozie(5.2.1) + Cmak(3.0.0.5) | |
| Data Governance | Atlas(2.0.0/2.1.0), Ranger(1.2.0/2.1.0) |
2) 삼성 클라우드 플랫폼에서의 데이터 웨어하우스
데이터 웨어하우스란 사용자의 의사 결정에 도움을 주기 위하여, 기간 시스템의 데이터베이스에 축적된 데이터를 공통의 형식으로 변환해서 관리하는 데이터베이스를 말합니다. 현재 데이터 웨어하우스는 더 많은 데이터, 작업량, 사용자 추가에 대한 도전을 맞이하고 있습니다.
이에 대한 해결책으로 보다 많은 데이터를 유입시키고, 더 큰 규모의 사용자에 적합한 클라우드 기반 데이터 웨어하우스가 등장하게 되었습니다. 삼성 클라우드 플랫폼에서의 데이터 웨어하우스는 버티카(Vertica)와 클라우드 하둡으로 구현할 수 있는데, 먼저 클라우드 하둡 상품을 활용하는 데이터 웨어하우스를 살펴보겠습니다.
클라우드 하둡으로 구현되는 데이터 웨어하우스
클라우드 하둡에서는 데이터 웨어하우스를 위해 메모리 기반 병렬 처리 SQL 엔진인 임팔라(Impala)를 제공합니다. 임팔라는 현존하는 SQL on Hadoop 엔진 중 가장 빠른 성능을 구현하여 데이터 엔지니어 및 분석가들이 실시간으로 데이터를 분석할 수 있도록 합니다. 기존 대비 10배 이상 향상된 성능을 확보하여 하둡 기반 데이터 웨어하우스를 구성할 수 있습니다. 고객은 이를 활용해 데이터 분석을 빠르게 수행할 수 있으며 고객 유치 및 유지, 생산성 향상 정보에 입각한 의사 결정을 통해 비즈니스 성장 기회를 더 빨리 식별, 대응할 수 있습니다.
클라우드 하둡은 임팔라와 함께 빠르게 변화하는 데이터에 대한 분석을 신속하고 쉽게 해주는 분산 데이터 스토리지 엔진인 쿠두(Kudu)를 제공합니다. 쿠두는 하둡 플랫폼 환경에서 사용되는 Columnar 스토리지 엔진으로 데이터 웨어하우징 워크로드(Data Warehousing Workload)에 매우 유리합니다.
고객은 이를 활용하여 변경이 잦은 데이터에 대한 ACID와 더 빠른 쿼리 성능을 보장 받을 수 있습니다.
※ ACID : Atomicity, Consistency, Isolation, Durability의 속성을 합친 말로 하나의 트랜잭션이 문제없이 실행될 수 있도록 하는 성질이다.
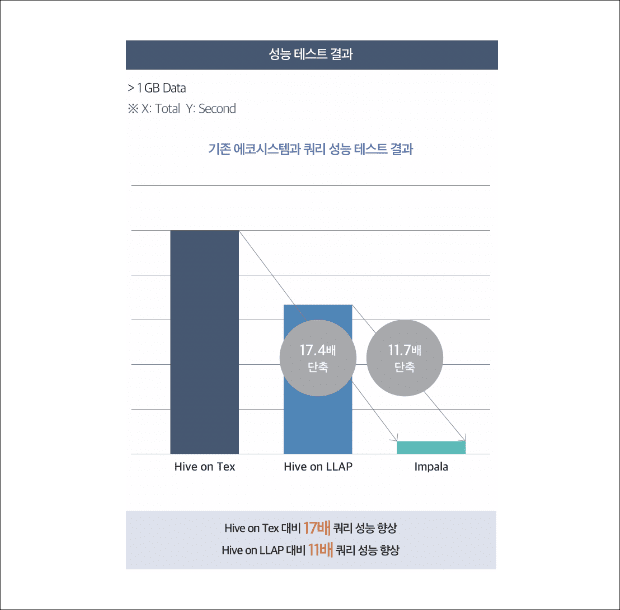
[임팔라와 기존 하이브 성능 비교]
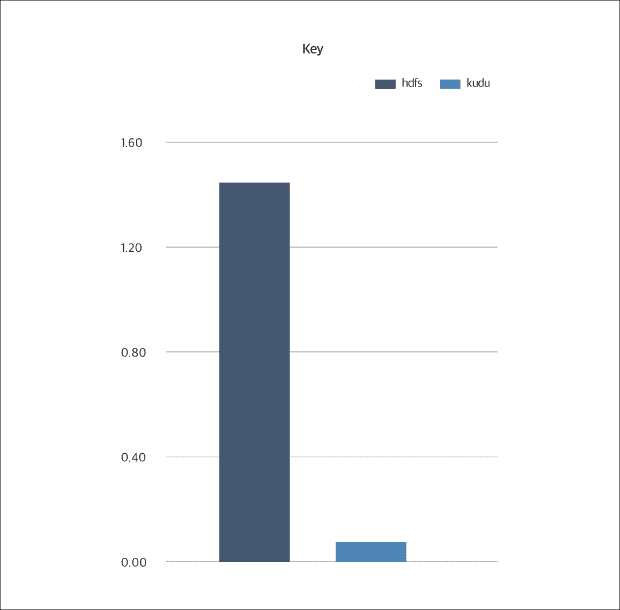
[임팔라 on Kudu 와 임팔라 on HDFS 의 성능 비교]
버티카로 구현되는 데이터 웨어하우스
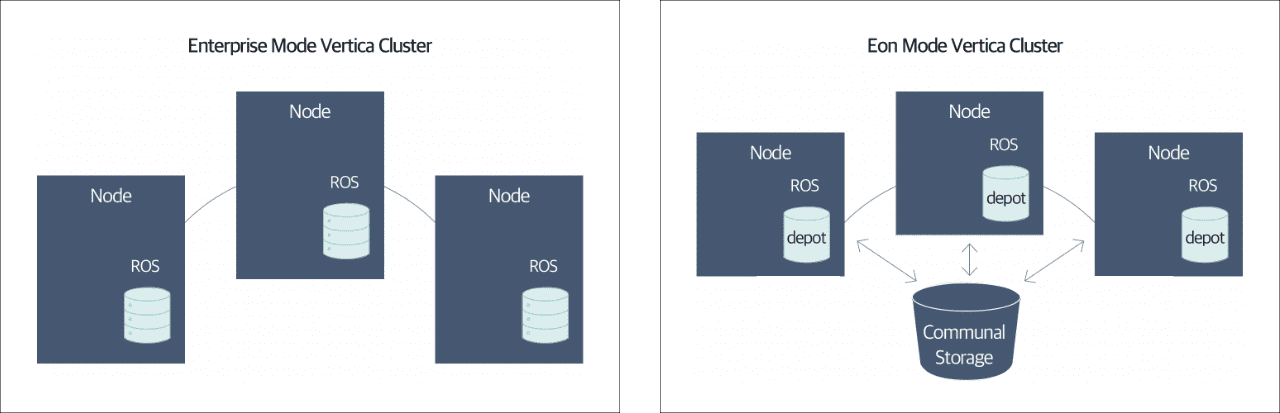
삼성 클라우드 플랫폼에서는 클라우드 하둡과 더불어 버티카를 상품으로 제공합니다. 버티카는 Native Column기반으로 인덱스 없이 분석 적용으로 사용할 수 있는 DBMS입니다. 구성 형태는 노드 단위로 Scale-out이 가능하며 마스터리스(Masterless) 구조로 높은 가용성을 자랑합니다. 또한 버티카는 기존 엔터프라이즈 형태 외에 더 많은 데이터와 작업량, 사용자 지원을 위해 스토리지와 컴퓨팅 영역을 분리할 수 있는 Eon모드를 지원하고 있습니다.
대용량 처리를 위해 Scale-up에 필수적인 아키텍처를 기반으로 한 서비스를 제공하고 있으며, 마이크로 서비스로의 전환을 대비하여 컨테이너 구성 환경으로도 제공되고 있습니다.

3) 데이터 플로우(Data Flow), 데이터 옵스(Data Ops) 소개
데이터 레이크 및 목적 별 데이터 스토어의 데이터가 계속 증가하면서 데이터 스토어 간에 데이터의 이동을 쉽게 하는 기능이 필요한 경우가 많습니다. 삼성 클라우드 플랫폼에서는 데이터 플로우 상품과 데이터 옵스 상품을 제공하고 있습니다. 각각의 상품에 대해 소개해 드리겠습니다.
데이터 플로우 상품의 개요
데이터 플로우는 다양한 데이터 소스 및 대용량 데이터의 전달을 목적으로 Apache NiFi를 활용, 데이터 처리의 흐름을 시각적으로 제공하는 데이터 처리 흐름 자동화 도구입니다. 삼성 클라우드 플랫폼에서 제공하는 데이터 플로우는 데이터 플로우 만의 관리 기능과 Apache NiFi 호환성 제공으로, NiFi 클러스터 구성 및 리소스 프로비저닝 기능보다 데이터 플로우 본연의 기능인, 데이터 추출/변환/전송 및 데이터 처리 흐름을 작성하는 기능에 더 집중할 수 있도록 해줍니다.
데이터 플로우의 주요 특징은 다음과 같습니다.
첫째, 다양한 데이터 소스 간의 데이터 전송이 가능합니다. File, NoSQL, RDB, HDFS, JMS, FTP, SFTP, Kafka, HTTP(s) REST 등의 다양한 데이터 소스로부터 원하는 데이터 타겟이 되는 곳으로 대용량 데이터를 처리/전송할 수 있습니다. 둘째, GUI 기반 데이터 처리 Flow 작성이 가능합니다. 이미 정의된 데이터 처리 프로세서를 사용하여 GUI 기반 Drag and Drop을 통해 데이터 추출/변환/전송 작업을 코딩 없이 작성할 수 있습니다. 셋째, 실시간 데이터 흐름 제어가 가능합니다.
데이터 처리 과정에 대하여 Flow 파일로 실시간 데이터 처리 단계를 확인할 수 있으며, 오류 처리 케이스도 설계하여 데이터 전송 흐름을 제어할 수 있습니다.
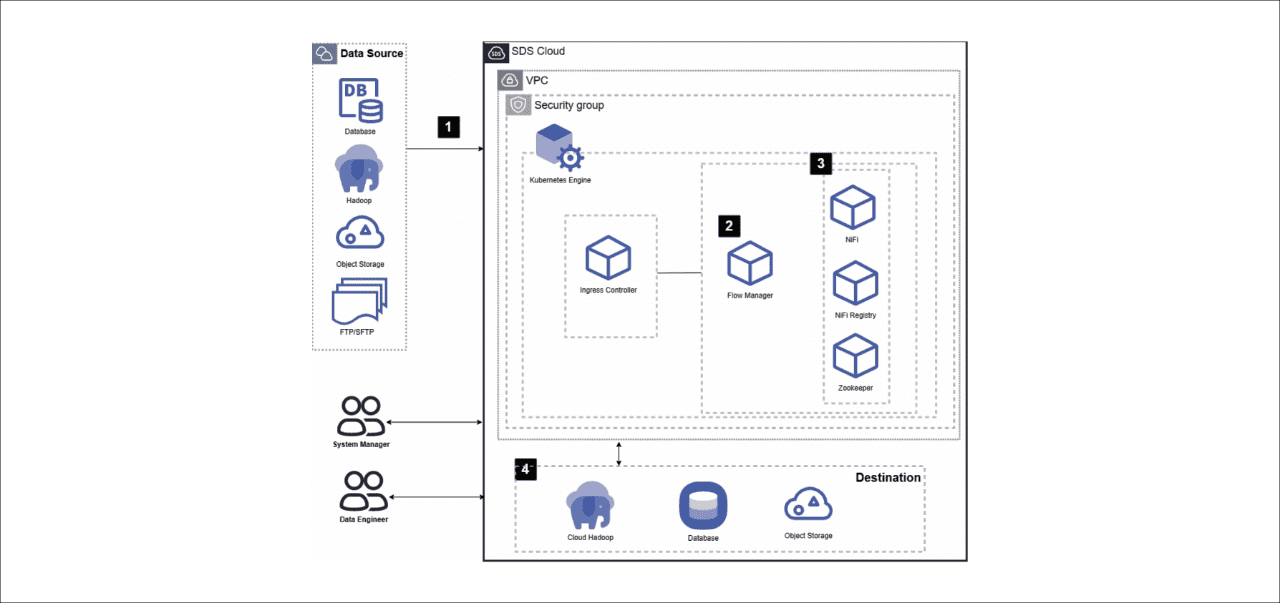
[Figure 1. 데이터 플로우 기반 대용량 데이터 전송 자동화]
데이터 플로우 아키텍처는 다음과 같습니다.
1. System Manger는 시스템 간 데이터의 수집, 변환, 전송 처리 자동화 수행을 위해 데이터 플로우 상품을 신청합니다.
2. 데이터 엔지니어는 플로우 매니저를 통해 데이터 플로우 서비스의 설정 정보를 수정하고 추가적인 Custom 프로세서 배포 및 Flow Template 파일을 관리할 수 있습니다.
3. 데이터 플로우 서비스는 Apache NiFi를 기반으로 GUI를 통해 다양한 프로세서들의 Flow 작성 및 스케줄링이 가능하고 데이터 처리 흐름을 시각적으로 확인할 수 있습니다. 또한 NiFi Registry를 사용하여 NiFi에서 작성한 Flow의 버전 관리와 복원 기능을 사용할 수 있습니다.
4. 수집, 변환된 데이터는 클라우드 하둡(HDFS), 데이터베이스, 오브젝트 스토리지 등에 전송되어 저장할 수 있습니다.
데이터 옵스 상품의 개요
데이터 옵스는 주기적, 반복적으로 발생하는 데이터 처리 작업에 대해 워크플로우를 작성하고 작업 스케줄링을 자동화하는 아파치 에어플로우(Apache Airflow) 기반의 관리형 워크플로우 오케스트레이션 서비스입니다. 삼성 클라우드 플랫폼의 쿠버네티스 엔진 클러스터 환경에서 단독으로 사용하거나, 다른 애플리케이션 SW와 함께 사용할 수 있습니다.
이 서비스의 주요 특징은 첫째, 데이터 기반 (data driven) 워크플로우 오케스트레이션을 제공합니다. 데이터 옵스는 데이터 기반의 워크플로우, 특히 ETL / ELT를 오케스트레이션 할 수 있습니다. 워크플로우를 자동으로 Organizing, Monitoring, Execution 합니다. 또한 Spark을 통해 실행 후 결과를 클라우드 하둡에 저장하는 시나리오로도 사용할 수 있습니다. 둘째, 배치 워크로드 작업이 가능합니다. ETL 파이프라인 또는 ELT 작업 시, 여러 소스에서 데이터를 가져오고 변환하는 작업을 수행하는 파이프라인으로 사용할 수 있습니다. 배치 프로세스의 가시성을 높이고 배치 작업을 분리해 개발 주기를 단축할 수 있어 작업 실행 사이의 지연 시간을 처리할 수 있는 배치 처리 작업에 적합합니다. 셋째, 엔터프라이즈 스케줄링을 제공합니다. Command shell, API, 엔터프라이즈 실행 컨테이너와 연계함으로써, 기존 애플리케이션 도구와 함께 스케줄링을 할 수 있습니다.
또한, 기존 서비스와 통신하여 데이터 파이프라인 서비스를 오케스트레이션 할 수도 있습니다.
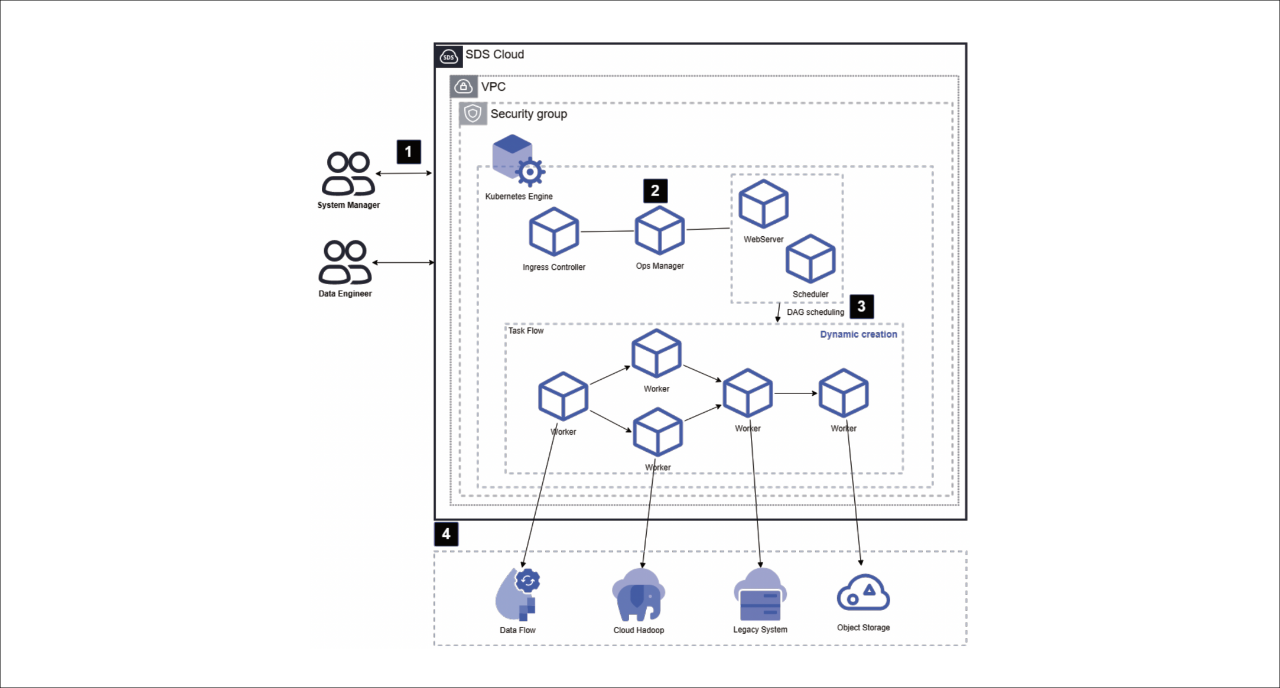
[Figure 1. 데이터 옵스 기반 워크플로우 관리]
데이터 옵스 아키텍처는 다음과 같습니다.
1. 시스템 매니저는 주기적, 반복적인 데이터 처리 작업(추출/적재/변환/정제)의 워크플로우 관리를 위해 데이터 옵스 상품을 신청합니다.
2. 데이터 엔지니어는 옵스 매니저를 통해 데이터 옵스 서비스의 설정 정보를 수정하고 추가적인 플러그인/라이브러리 파일을 관리할 수 있습니다.
3. 데이터 옵스 서비스는 아파치 에어플로우를 기반으로 하고 있습니다. DAG(Directed Acyclic Graph) 형식으로 워크플로우를 작성, 스케줄링 및 모니터링이 가능하며, 실제 작업이 실행되는 Worker는 다이나믹하게 실행됩니다.
4. 데이터 플로우, 클라우드 하둡, 레거시 시스템, 오브젝트 스토리지 등의 다양한 시스템과 연계하여 워크플로우 기반 작업을 수행할 수 있습니다.
4) AI&MLOps 플랫폼 소개
삼성 클라우드 플랫폼은 사용자가 직접 MLOps환경을 쉽고 간단하게 구현할 수 있는 쿠브플로우 상품을 제공합니다. 네이티브 쿠부플로우(Native Kubeflow)를 제공하는 Kubeflow.mini와 여러 엔터프라이즈 특징들이 통합되어 있는 AI&MLOps 플랫폼이 있습니다. 아래처럼 간단하게 십수 분 만에 나의 AI/ML환경을 MLOps로 셀프 프로비저닝 할 수 있습니다.
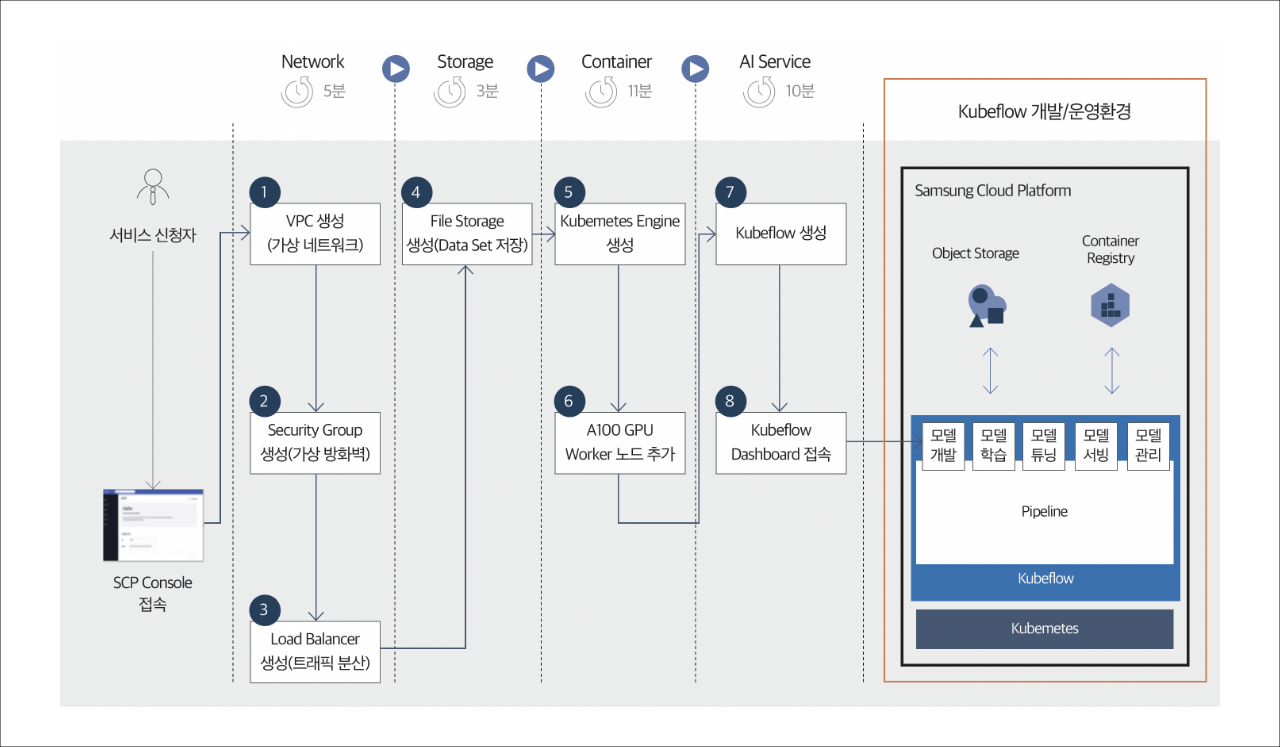
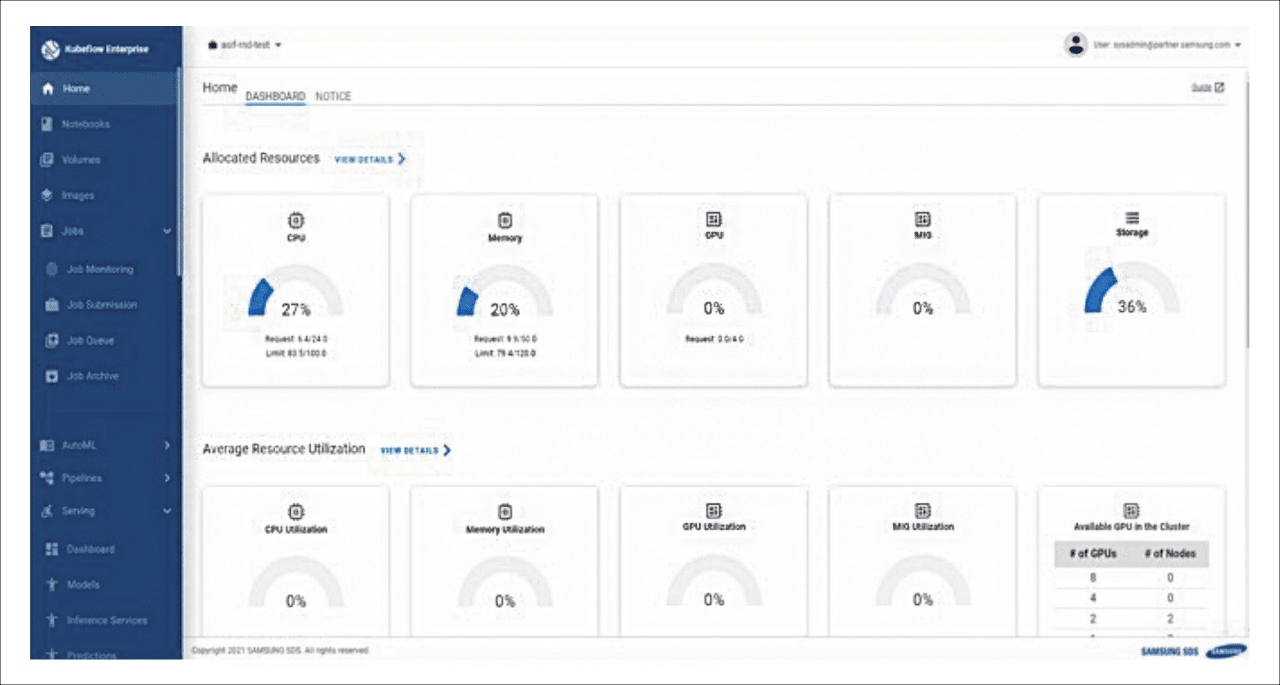
AI&MLOps 플랫폼을 이용하면, Native 기능 외 삼성 클라우드 플랫폼 에서만 제공하는 여러 확장 기능들을 이용하실 수 있습니다.
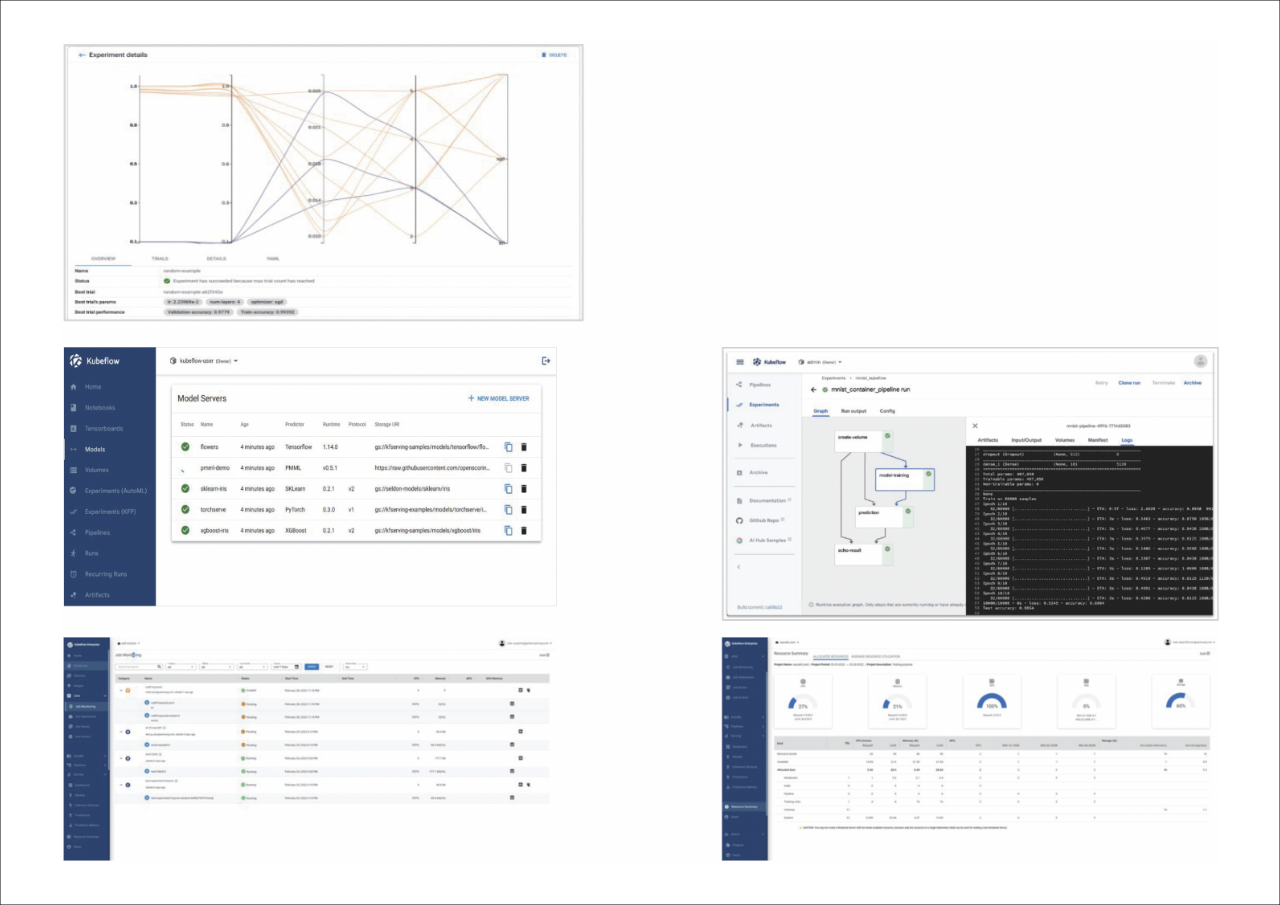
AI/ML 개발 및 학습 환경
다양한 AI/ML 개발 및 학습 환경 또 이용할 수 있습니다. R스튜디오(Rstudio), 비주얼 스튜디오코드(Visual Studio Code) 등 여러 IDE 환경을 이용할 수 있고, TFJob, PyTorchJob, MPIJob 등 분산 학습을 쉽게 쿠버네티스 환경에서 컨테이너로 실행할 수 있는 오퍼레이터를 지원하고 있습니다.
모델 튜닝 기능
모델 튜닝을 위한 하이퍼파라미터 최적화 기능을 지원합니다. 목표(accuracy 등), 탐색 범위(Learning rate, Layer 수 등), 탐색 알고리즘(random, grid 탐색 등), 최대 시도 등 설정 ML 코드 내 파라미터를 yaml 변수와 연동하여 구동할 수 있습니다.
모델 서빙 기능
최적화된 모델을 서빙(배포 및 추론)할 수 있습니다. 이를 위해 유연하고 확장 가능한 옵션들을 지원하는데, ML 프레임워크(ML Framework) 모델 서버를 활용한 서빙을 지원하고, 개발된 모델의 서비스화를 위한 엔드포인트 API(Endpoint API) 생성하거나, 추론(Inference) 시, A/B Test와 오토 스케일링(Auto-Scaling) 역시 가능합니다.
ML 워크플로우(ML Workflow) 생성과 실행 관리를 위한 파이프라인 기능
각 스텝을 그래프로 표현하여 실행 모니터링과 공유가 가능하며, 파이프라인 UI 혹은 파이썬 SDK를 활용하여 워크플로우를 구성할 수 있습니다. 워크플로우 변경 시, 각 스텝을 재사용하거나 교체 가능한 기능을 제공하고 있습니다.
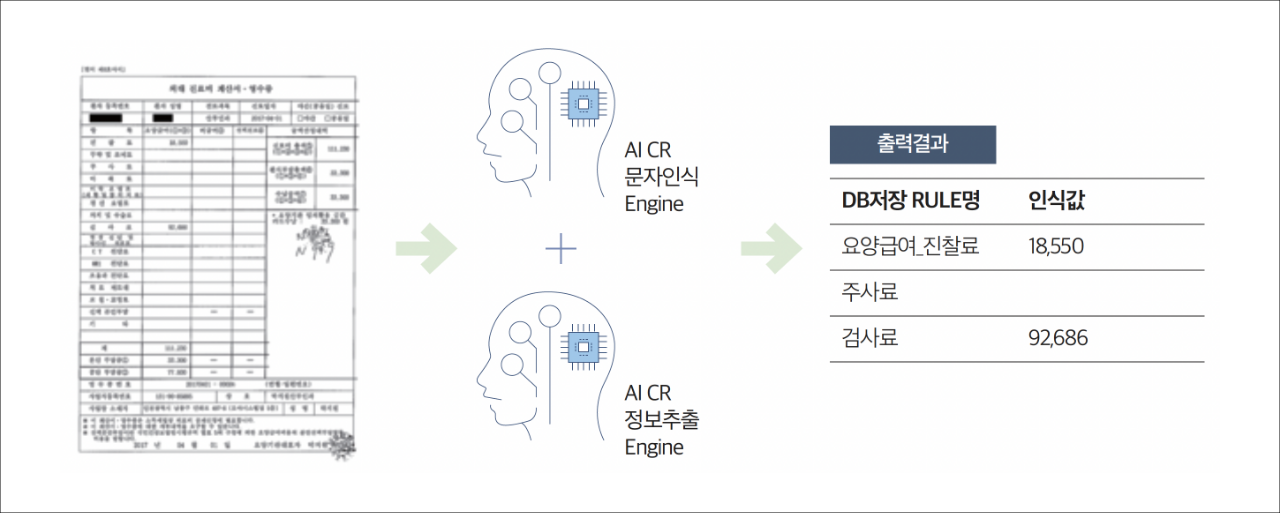
| DB저당 RULE명 | 인식값 |
|---|---|
| 요양급여_진찰료 | 18,550 |
| 주사료 | |
| 검사료 | 92,686 |
분산 Job 실행/관리
딥러닝 분산 학습 시, Job UI를 통한 편리성을 제공합니다. 텐서플로, 파이토치 등 분산학습 Job을 UI로 실행/조회할 수 있고, 분산학습 Job Submission 시, 큐(Queue)를 활용한 사용자 Job 대기 시간을 최소화하거나, 완료된 Job을 재실행, 파라미터를 변경하여 재실행할 수 있습니다.
GPU Job Scheduling
GPU 잡 스케줄러(GPU Job Scheduler) 기능을 내장하여 GPU 자원 효율을 극대화할 수 있습니다. 분산 병렬 작업 수행 시 GPU 자원을 점유하는 방식에 따라 발생할 수 있는 교착 상태를 방지하거나, FIFO, 빈패킹(Binpacking), 갱 스케줄링(Gang Scheduling) 정책을 적용할 수 있습니다.
5) AI 응용 서비스(AICR) 소개
AICR 상품을 시작으로 AI API 서비스 영역을 지속적으로 확보하려고 합니다. AICR은 AI Character Recognition으로 딥러닝 기반의 이미지 인식 기술을 바탕으로 문서 형태의 이미지로부터 데이터를 추출하는 서비스입니다. 일반적으로 OCR은 광학 문자 인식으로 종이 문서 내의 글자를 정확하게 인식해서 텍스트 데이터로 변환해 주는 서비스로 기업에서는 업무 자동화 및 기존 문서들의 디지털화를 위해 활용되고 있습니다. 삼성 클라우드 플랫폼 AICR은 기존 OCR에서 단어화, 문서 분류 및 데이터 추출과 관련된 특허 기반의 AI 딥러닝 기술을 접목하여 높은 정확도를 제공하고 있으며, 삼성 클라우드 플랫폼의 오브젝트 스토리지와 연계하여 분석할 이미지 적재 및 결과 분석 값 저장 기능까지 제공합니다.
첫 번째 주요 특징은 문자 인식입니다. 자체 개발한 이미지 전처리 기술과 문자 인식 알고리즘을 통해 이미지의 회전, 노이즈, 워터마크 등의 부정적인 요소들을 감소시켜 문자 인식 영역에서는 업계 최고 수준의 성능을 보유하고 있습니다. 이러한 성능을 기반으로 문서 종류나 품질에 상관없이 7개 권역 97개 국어에 대해 정확한 문자 인식을 제공합니다. ※ 언어 분류: 7개 권역 97개 국어 (한글, 라틴 56개 국어, 키릴 11개 국어, 중국 2개 국어, 일본, 태국, 아랍 25개 국어)
두 번째 특징은 문서 구조 분석입니다. 딥러닝 기반의 이미지 분석 모델이 문서의 구조인 문단, 테이블, 그림, 등의 비 문자 영역을 인식하여 고도화된 영상 처리 알고리즘으로 테이블 구조를 식별합니다. 문서의 테이블과 key-value를 정확하게 구분한 결과값을 제공합니다.
세 번째는 데이터 추출 자동화입니다. AICR은 단어 인식 알고리즘과 딥러닝 기반의 Key-value 추천으로 엔진이 자동으로 높은 정확도의 데이터를 추출하고 있습니다.
4. 데이터 애널리틱스, AI/ML 관련 서비스를 점차 확대해 가고 있는 삼성 클라우드 플랫폼
대부분의 회사는 여러 사일로에서 데이터를 가져와 한 곳에서 모든 데이터를 집계하고, 이를 위해서 확장 가능한 데이터 레이크를 구축하며, 저지연 분석, 대화형 대시보드, 로그 분석, 빅 데이터 처리 및 데이터 웨어하우징과 같은 사용 사례에 필요한 성능을 제공하는 광범위한 데이터 서비스가 필요합니다.
또한 데이터 레이크와 전용 데이터 서비스 간에 데이터를 쉽게 이동할 수 있어야 하며, 데이터에 대한 액세스를 보호, 모니터링 및 관리하기 위해 통합된 방식의 거버넌스 및 규정 준수 설정도 가능해야 합니다.
이를 위해 삼성 클라우드 플랫폼에서는 데이터 애널리틱스 상품군과 AI/ML 상품군의 서비스 확대와 전문적인 기능 강화로 강한 응집력을 가지고 빠르게 증가하는 데이터에 대한 확장과 대응이 가능하도록 준비할 예정입니다.
삼성 클라우드 플랫폼의 데이터 애널리틱스와 AI/ML 상품을 만나보세요.
-
Data Analytics
빅 데이터를 쉽고 빠르게 처리할 수 있는 분석 서비스
Data Analytics빅 데이터를 쉽고 빠르게 처리할 수 있는 분석 서비스
-
Apache Kafka (Managed) 아파치 카프카 클러스터를 생성/관리하는 서비스
-
Elasticsearch (Managed) 웹 환경에서 엘라스틱서치를 간편하게 생성하고 관리하는 서비스
-
Cloud Hadoop 쉽고 빠른 빅데이터 처리/분석을 위한 하둡 클러스터를 제공하는 서비스
-
Data Ops 데이터 처리 작업을 위한 워크플로우를 작성하고 작업 수행을 자동화하는 서비스
-
Data Flow 다양한 소스로부터 데이터를 추출/변환/전송하고 데이터 처리 흐름을 자동화하는 서비스
-
Data Wrangler 쉽고 빠르게 데이터를 탐색하고 원하는 형태로 재구성해주는 서비스
-
SQream 빅데이터 분석에 특화된 GPU 기반의 데이터베이스
-
Vertica(DBaaS) 대용량 데이터 분석/처리를 위한 Data Warehouse 기반의 고가용성 엔터프라이즈 데이터베이스
-
Data Catalog 쉽고 빠른 빅데이터 처리/분석을 위한 하둡 클러스터를 제공하는 서비스
-
Quick Query 쉽고 빠른 빅데이터 처리/분석을 위한 하둡 클러스터를 제공하는 서비스
-
-
AI/ML
쉽고 편리하게 ML/DL 모델 개발 및 학습 환경을 구축할 수 있는 AI 서비스
AI/ML쉽고 편리하게 ML/DL 모델 개발 및 학습 환경을 구축할 수 있는 AI 서비스
-
AI&MLOps Platform 쿠버네티스 기반의 머신 러닝 플랫폼
-
AICR 문서에서 텍스트와 데이터를 자동으로 추출하는 서비스
-
Text API 문장 및 텍스트의 의미를 이해하고 분석해주는 API 서비스
-
Vision API 이미지내의 정보를 인식하고 분석해주는 API 서비스
-
CloudML Experiments 이미지내의 정보를 인식하고 분석해주는 API 서비스
-
CloudML Notebook 이미지내의 정보를 인식하고 분석해주는 API 서비스
-
CloudML Pipeline 이미지내의 정보를 인식하고 분석해주는 API 서비스
-
CloudML Studio 이미지내의 정보를 인식하고 분석해주는 API 서비스
-
- 임준영 프로 / 삼성SDS
- 솔루션개발과 컨설팅 그리고 SI프로젝트를 수행하며 축적된 Software Architecture 역량을 바탕으로 현재는 삼성관계사와 일반 기업 고객 대상으로 Samsung Cloud Platform의 Analytics 상품군의 상품기획을 담당하고 있으며 Cloud Hadoop, Data Flow, Data Ops 상품의 Product Manager로 활동하고 있습니다.
- 이수정 프로 / 삼성SDS
- 웹 애플리케이션 운영, 데이터센터 사업성 검토 업무를 거쳐 현재는 Samsung Cloud Platform Product Manager로 Application Service, Management, AI/ML 영역의 상품 기획 업무를 담당하고 있습니다.