

이번 아티클에서는 다양한 GAN의 활용 사례에 대해 소개하려 합니다. Ian Goodfellow가 제안한 GAN은 근본적으로 3가지 정도의 한계를 가진 것으로 알려져 있는데, 소개에 앞서 이를 먼저 이해할 필요가 있습니다. 첫째는 기존 GAN만으로는 훈련 성능이 그다지 좋지 않으며, 둘째는 사용된 생성자의 결과물 형태가 어떠한 연유와 과정을 통해 나왔는지 알 수 없고, 셋째는 새롭게 만들어진 데이터가 얼마나 정확한지 객관적으로 판단하기 어렵다는 것입니다. 예를 들어, 생성된 데이터가 이미지인 경우 그 이미지의 퀄리티는 자동적으로 측정되는 것이 아니라 사람이 일일이 보고 판단해야 하는 문제가 있습니다.
위에서 언급된 GAN의 첫 번째 한계를 구체적으로 살펴보면, GAN은 생성자와 분류자가 대결하며 학습하는 구도인 만큼 학습이 불안정하다는 단점이 있습니다. 생성자와 분류자가 서로 균형 있게 훈련을 주고받아야 하는데, 두 모델 간 실력차가 발생하는 경우 훈련이 한쪽에 치우쳐 궁극적으로 성능이 제약되죠. 때문에 GAN의 훈련 성능을 높이기 위한 다양한 연구가 진행되고 있는데, 대표적인 것이 DCGAN(Deep Convolutional GAN)입니다.
DCGAN은 GAN에 지도학습에서 이미 폭넓게 적용되던 CNN을 사용하는 것으로, 비지도학습 적용을 위해 기존의 fully connected DNN 대신 CNN(Convolutional Neural Networks) 기법으로 신경망을 구성했습니다. CNN은 전체 데이터의 특정 부분에 대한 주요 특징 값을 추출하는 Convolutional layer(필터 역할)와 추출한 특징 중 제일 중요한 값만 추려내는 Pooling layer가 교차하면서 이루어집니다. 이때 이미지와 같은 부분의 특징을 읽어내는 성능이 탁월하여 학습이 잘 된다는 장점을 GAN의 이미지 생성에 적용한 것입니다. 또한, 각 층 해당 뉴런의 입력 대비 출력을 얼마나 반영할지 결정하는 함수인 활성화함수(Activation function)의 적절한 선택이 중요한데, GAN을 위해서 leaky_ReLU 함수를 사용하여 분류자의 학습 효율을 높였습니다.
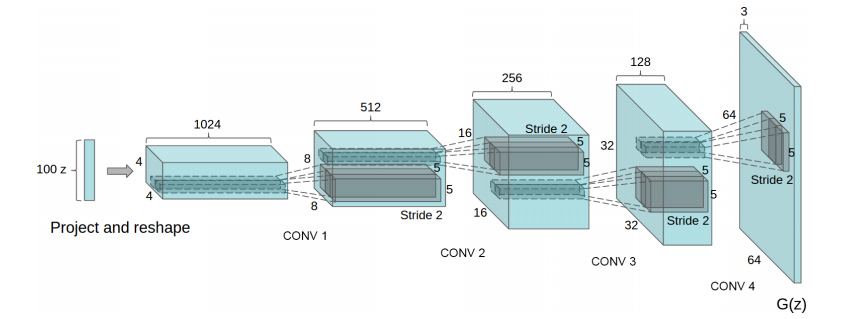 [그림1] DCGAN의 생성자 구조도(100차원 latent vector z가 64*64 픽셀의 이미지를 생성)
[그림1] DCGAN의 생성자 구조도(100차원 latent vector z가 64*64 픽셀의 이미지를 생성)
이러한 구조를 통해 DCGAN은 GAN의 학습에 대한 문제점을 상당 부분 극복해내면서 주목을 받았으며, 지난 아티클에서 소개한 ‘latent vector를 이용한 이미지의 산술적 연산’을 가능하게 한 주인공이기도 합니다.
DCGAN의 등장으로 성능이 향상된 GAN을 통해 더 완벽한 가짜 데이터를 만들어내는 모델이 속속 연구됨에 따라 GAN의 활용 범위 역시 더욱 넓어지고 있습니다. 특히, 2017년 워싱턴대학교 연구팀은 영상 합성에 GAN을 적용하여 만든 ‘오바마 전 미국 대통령의 가짜 영상’을 공개해 화제가 되기도 했죠. 그들은 오바마 대통령의 실제 연설에서 음성을 추출한 후, 음성에 맞게 입 모양을 생성하도록 GAN을 학습하여 가짜 영상을 만들어냈습니다. 진짜처럼 보이는 아래 사진들은 모두 GAN을 이용해 만들어낸 가짜 영상의 일부분입니다. 즉, 지금까지 설명한 latent vector의 산술적 연산을 통해 ‘안경을 새로 씌울 수 있는’ GAN의 근본적인 개념과 마찬가지로, 오바마의 얼굴을 만들어낸 latent vector에서 입술에 해당하는 부분만 벡터 연산을 통해 산술적으로 대체해주면 얼마든지 창조적으로 얼굴을 조작할 수 있는 것입니다.
 [그림2] GAN을 통해 합성한 오바마 전 미국 대통령의 연설 영상
[그림2] GAN을 통해 합성한 오바마 전 미국 대통령의 연설 영상
이러한 GAN의 뛰어난 능력을 이용한 대표적인 사례로는 최근 페이스북에서 개발한 Real-eye-opener가 있습니다. Real-eye-opener는 찍는 순간 실수로 눈을 감아 사진을 망친 경험이 있는 사람이라면 누구나 공감할 만한 기술입니다. 눈을 감은 사진에 가짜 눈을 생성하여 눈을 뜨고 있는 사진으로 만들어주는 기술로, GAN을 통해 얼굴에 눈을 합성해주죠. 입모양을 생성해 오바마 전 대통령의 연설 영상에 합성한 것과 마찬가지로, 이번에는 원하는 눈 모양을 latent vector에 반영하여 눈 모양이 대체된 새로운 얼굴 전체를 생성하는 것입니다. 아래 [그림3]에서 (a)/(b)는 각각 사람이 눈을 뜨고/감고 있는 실제 사진이며, 목표는 (b)의 사진에 (a)의 눈 모양을 합성하는 것입니다. (c)는 단순히 포토샵을 이용해 (b)에 (a)의 눈을 합성한 결과이며, (d)는 GAN을 이용해 합성한 결과입니다. 보시다시피 (c)는 합성한 눈과 얼굴 사이의 경계가 부자연스러운 데 비해 (d)는 훨씬 자연스럽고 실제 사람의 사진과 유사합니다.
 [그림3] 페이스북의 real-eye-opener
[그림3] 페이스북의 real-eye-opener
이러한 놀라운 기술은 이제 GAN이 Image translation에도 적용될 수 있음을 의미합니다. Image translation은 흑백사진을 컬러사진으로, 간단한 일러스트를 구체적인 사진으로 만들어내는 등 우리가 원하는 대로 이미지를 바꾸어 재생성하는 것입니다. 아래 [그림4]는 2017년 UC버클리에서 GAN을 Image translation에 적용하기 위해 GAN 구조에 원래 이미지의 형태를 잘 유지할 수 있는 조건을 추가한 cycleGAN 모델의 결과입니다. 어떤 사진을 주었을 때 모네 화풍의 그림으로 만들어내기도 하고, 반대로 모네의 그림을 사진으로도 변환해내는 것을 볼 수 있죠. 마찬가지로 얼룩말의 사진에서 얼룩무늬를 지워 말로 바꾸고, 여름 분위기의 사진을 겨울 분위기로 변환하는 것도 가능합니다.
 [그림4] cycleGAN을 통한 Image Translation
[그림4] cycleGAN을 통한 Image Translation
최근 GAN은 음성신호 및 자연어 처리 등으로 영역이 확대되어 다양한 분야에 적용되며 빠르게 발전하고 있어 가장 유망한 인공신경망 알고리즘으로 각광받는 중입니다. 하지만 가장 기본적인 해결과제인 학습 안정화가 아직 남아있죠. DCGAN을 통해 어느 정도 안정된 학습을 진행할 수 있게 됐지만, 더 다양한 분야에 활용하고 보다 정밀한 성능을 얻기 위해서는 향상된 신경망 구조 개발 등의 후속 연구가 필요해 보입니다. 그 외에도 GAN은 지도학습 모델을 추가 적용하여 성능을 높이고, 강화 학습 및 또 다른 비지도학습 알고리즘과 결합하는 방향으로 계속해서 발전해 나갈 것입니다.
**출처
그림1: (논문) Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. Alec Radford, Luke Metz, Soumith Chintala.
그림2: (논문) Synthesizing Obama: Learning Lip Sync from Audio. Supasorn Suwajanakorn, Steven M. Seitz, Ira Kemelmacher-Shlizerman.
그림3: (논문) Eye In-Painting with Exemplar Generative Adversarial Networks. Brain Dolhansky, Cristial Canton Ferrer.
그림4: (논문) Unpaired Image-to-Image Translation using Cycle-consistent Adversarial Networks. Jun-Yan Zhu, Teasung Park, Phillip Isola, Alexei A. Efros.
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
![]()

한양대학교 융합전자공학부
한양대학교 융합전자공학부 교수로 재직 중입니다. 인공지능 딥러닝 및 음성인식 분야의 권위자로 Elsvevier Digital Signal Processing 편집위원, 한국통신학회 신호처리연구회 위원장 등 폭넓은 활동을 전개하고 있으며, AI스피커 연구, 딥러닝 음성인식, 바이오진단 등의 분야에 연구를 진행하고 있습니다.