
“제33조(고영향 인공지능의 확인) 인공지능사업자는 인공지능 또는 이를 이용한 제품ㆍ서비스를 제공하는 경우 그 인공지능이 고영향 인공지능에 해당하는지에 대하여 사전에 검토하여야 하며, 필요한 경우 과학기술정보통신부장관에게 고영향 인공지능에 해당하는지 여부의 확인을 요청할 수 있다.”
“제34조(고영향 인공지능과 관련한 사업자의 책무) 인공지능사업자는 고영향 인공지능 또는 이를 이용한 제품ㆍ서비스를 제공하는 경우 고영향 인공지능의 안전성ㆍ신뢰성을 확보하기 위하여 다음 각 호의 내용을 포함하는 조치를 대통령령으로 정하는 바에 따라 이행하여야 한다.”
- 인공지능 발전과 신뢰 기반 조성 등에 관한 기본법
2024년 12월, 『인공지능 발전과 신뢰 기반 조성 등에 관한 기본법(이하 인공지능기본법)』이 국회 본회의에서 의결되었습니다. 이는 인공지능 산업의 발전에 중점을 두면서도, 이용자 보호를 위한 최소한의 장치를 마련한 것으로 해석됩니다.[1]
DeepMind 공동 설립자 무스타파 슐레이만은 AI 기술의 발전을 일종의 역사적 '물결(wave)'에 비유합니다. AI는 인류에게 새로운 힘이 됨과 동시에 전례 없던 혼란과 불안정을 야기할 수도 있다는 점을 지적합니다. 무스타파는 우리가 AI 기술에 의존하면서도 위협을 받고 있다고 말합니다. 억제가 불가능한 다가오는 물결(the coming wave)을 우리는 어떻게 마주해야 하는지 고민이 필요한 시점입니다. 다음의 사건은 이러한 위협이 우리의 생활에 드러나는 사례의 일부입니다.
AI 사업자 측면의 사건
2025년 1월에 출시해 ChatGPT에 이어 다시 한번 세상을 놀라게 했던 LLM 딥시크(Deepseek)가 출시로부터 채 한 달도 되지 않은 2월 15일 우리나라에서 서비스를 중지하였습니다. 이로써 우리나라는 이탈리아, 대만, 호주, 미국에 이어 전 세계에서 5번째로 딥시크 이용을 제한한 나라가 되었습니다. 개인정보보호위원회는 이용자의 개인정보를 과도하게 수집하는 것으로 의심되는 딥시크에 개인정보의 수집과 처리방식에 대한 공식 질의서를 보냈으며 개인정보보호법에 따른 개선 및 보완을 권고하였습니다. 이에 대해 딥시크 측에서는 역외 규제에 대한 고려가 소홀했음을 인정하기도 했습니다.[2]
AI 이용자 측면의 사건
프라이버시만이 AI로 발생될 수 있는 피해의 전부가 아닙니다. 최근 미국 최대 상해 로펌 Morgan & Morgan은 ChatGPT가 생성한 허위 판결문을 법원에 제출함으로써 문제가 되었습니다. 변호인이 인용한 9건의 판례 중 8건이 법률 데이터베이스상 존재하지 않는 허구라고 밝혀진 것입니다.[3] 생성형 AI가 응답한 정보를 검증 절차 없이 이용하여 해당 로펌과 AI에 대한 신뢰성에 의구심이 커졌음은 물론입니다. 이 사건은 지난 2023년에 아비앙카항공 여객기 승객 관련 뉴욕주 변호 사건이 이슈가 되었음에도 또다시 발생하여, 고차원의 서비스인 법률 분야에서도 AI의 활용으로 인한 위험이 쉽게 사라지지 않는다는 것을 확인한 사례라 하겠습니다.
이상과 같이 AI로 인한 피해가 반복되는 상황에서 법률과 정책을 통해 사업자가 자발적으로 AI 시스템의 안정성 및 신뢰성을 확보하도록 하는 것은 기술의 개발과 활용을 저해하지 않으면서도 이용자를 위한 최소한의 안전장치를 마련하는 것으로 이해할 수 있습니다.
이 글에서 우리는 AI 기술 개발과 활용에 몰입하던 상황에서 잠시 시선을 돌려 AI로 인한 위험은 무엇이 있는지, AI를 이용하는 사업자에게는 어떤 영향이 있고 무엇을 준비해야 하는지 살펴보려고 합니다.
우리가 주목해야 할 AI 위험은 무엇인가?
AI 위험이란 AI 기술을 활용한 시스템이 유발하는 잠재적 피해(potential harm)가 발생할 수 있는 확률과 피해 수준에 관한 함수입니다. AI 시스템은 긍정적 또는 부정적 영향을 끼칠 수 있으며, 그 결과는 개인과 사회 등에 기회가 되거나 위협이 될 수 있습니다.[4] 우리는 이 영향이 부정적이고 위협이 되는 경우 통상 위험하다고 합니다.
AI는 다른 정보기술의 위험과는 다르게 접근할 필요가 있습니다. AI 시스템의 작동이 사람의 의사결정을 모방하도록 설계되었고 때로는 그 행동이 사람과 구분하기 어려울 수도 있기 때문에, 인간에게만 요구되던 윤리적 이슈가 제기됩니다. 기술적인 측면에서는 AI 알고리즘이 전통적인 정보기술을 구성하는 코드나 부품처럼 투명하게 관찰되기 어렵기 때문에 블랙박스 문제가 있습니다. 그로 인한 피해의 유형은 우리의 일상생활에 부정적인 영향을 끼거나 환경, 에너지, 사회 등의 부문에서 심각한 해악(harm)을 일으키기도 합니다.
우리나라의 인공지능기본법보다 먼저 입안된 EU AI Act나 미국 콜로라도주 AI법[5]에서는 AI가 미치는 해악의 수준이 높은 경우 ‘고위험(High Risk)’ AI라 하고 있습니다. 그런데 우리나라의 인공지능기본법은 ‘고영향(High Impact)’ AI라는 다소 생소한 표현을 사용합니다. 고영향 AI는 고위험과 같은 부정적인 영향 외에 사회적 파급 효과가 큰 긍정적 영향까지도 AI 사업자가 신중하게 관리할 수 있도록 함으로써 당장의 위험뿐 아니라 이후의 불확실한 영향까지 고려한 포괄적이고 중립적인 용어입니다.[6] 아울러 인공지능기본법은 고영향 및 생성형 AI 사업자의 의무 사항을 명시하고 있습니다. 비록 법안에서 명시한 강제성이 약하다 할지라도 AI 사업자는 고영향에 해당하는 사업을 수행하는 경우 사전에 검토하고 안전조치를 취해야 합니다. 따라서, AI의 잠재적 위험 수준을 판단하는 AI 위험 평가는 중요한 과제가 되었습니다.
AI 위험 평가 접근 방법
그렇다면 AI의 위험에 관한 함수는 과연 도출 가능한 것일까요? 그리고 측정을 통해 위험 수준을 알게 되었다면 그 이후에 사업자는 무엇을 할 수 있는 것일까요? 이러한 질문에 답하기 위해 위험의 인식과 위험 평가 프레임워크, 그리고 관리 방법에 관한 몇 가지 접근 방법을 이어서 논의해 보고자 합니다.
AI 위험의 인식
우리는 AI를 제공하는 사업자가 ‘고영향’ 또는 ‘고위험’에 해당하는지 사전 검토를 통해 안전조치를 마련해야 하는 필요성에 대해 논의하였습니다. 그러면, 이런 위험은 어떻게 파악해야 하는 것일까요? 아래의 연구는 위험의 측정 방법에 대한 다양한 연구와 전문가 의견을 체계적으로 분석한 결과, 위험을 인식하는 데 두 가지 관점이 있다는 결론에 도달하였습니다.[7] 하나는 위험을 그 어디에서 도래했는지 원인을 중심으로 보는 방법이고, 다른 하나는 위험이 어떤 피해를 끼치게 되는지 결과를 중심으로 보는 방법입니다([그림 1] 참고).
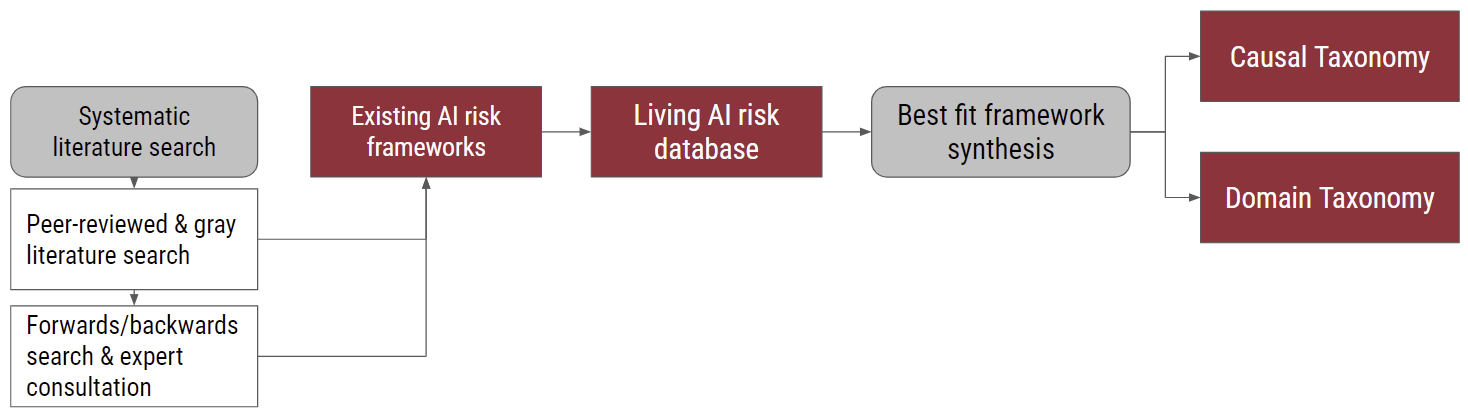 [그림 1] AI 위험의 인식 방법[7]
[그림 1] AI 위험의 인식 방법[7]
-
- Systematic literature search
- Peer-reviewed & gray literature search
- Forwards / backwards search & expert consultation
- Existing AI risk fameworks
- Living AI risk database
- Best fit framework synthesis
-
- Causal Taxonomy
- Domain Taxonomy
발생 원인을 중심으로 위험을 인식하게 되는 경우 AI 위험은 다음처럼 나누어집니다.
- 무엇이?(개체) : 사람, AI, 또는 기타 개체로 인해 발생
- 왜?(의도) : 고의적으로 또는 의도하지 않은 상황에서 발생
- 언제?(시기) : AI가 배포하여 작동하게 된 후 또는 배포 후에 발생
우리는 위험의 발생을 이렇게 구조적으로 분석함으로써 위험의 원인을 보다 정확히 진단하고 향후 개선 가능한 조치를 취할 수 있게 될 것입니다.[7] 또 다른 관점은 위험을 차별, 개인정보 보호 및 보안, 잘못된 정보, 악의적인 행위자 및 오용, 인간-컴퓨터 상호작용, 사회경제적 및 환경적 피해, AI 시스템 안전 실패 및 한계 문제 등 위험의 영역으로 분류하는 방식입니다.[7] 이러한 인식 체계로 위험을 바라보면, 위험이 구체적으로 사람, 사회 또는 기업에 어떤 실체적 피해를 주었는지 또 그 피해의 규모는 어떻게 되는지 빠르게 파악할 수 있을 것입니다. 아울러 이런 피해를 예방하기 위한 조치를 사전에 수립하는 것도 용이해 질 것입니다. AI를 사용하는 조직은 위험 노출 및 관리를 종합적으로 평가하기 위한 유용한 기반으로서 위험 인식 체계를 사용합니다. 결론적으로는 위험을 완화하기 위한 행위가 무엇인지 판단하는 데도 도움을 받을 수 있습니다.[7]
AI 위험 평가 프레임워크
AI로 인한 공통적인 위험 인식과 평가를 위해 프레임워크를 활용하자는 논의가 지속되어 왔습니다. 특히, 북미, 유럽, 아시아의 주요 국가에서는 정부, NGO, 학계를 중심으로 AI 위험 관리에 참고할 수 있는 프레임워크를 발표했습니다(<표 1> 참고). 이 프레임워크의 공통적인 부분은 AI를 사람과 유사하게 자율적이고 적응성을 가진 것으로 간주한다는 것입니다. 따라서 이러한 AI를 만드는 주체로서 사람의 책임성을 강조하며, 인간, 사회, 환경에 이로운 AI 시스템을 개발하고 사용하도록 하는 것입니다. 이것을 RAI(Responsible AI) 원칙이라고도 합니다.[8]
<표 1> AI 위험 평가 프레임워크[8]
| 프레임워크 | 지역 | 발표시점 | 발표기관명 |
|---|---|---|---|
| Algorithm Impact Assessment tool(AIA) | 캐나다 | 2019 | Government of Canada |
| Secure AI Framework(SAIF) | 미국 | 2023 | |
| MAS Veritas Framework | 싱가포르 | 2019 | Monetary Authority of Singapore |
| FLI AI Safety Index | 미국 | 2024 | Future of Life Institute |
| Fundamental rights and algorithm impact assessment(FRAIA) | 네덜란드 | 2022 | Ministry of the Interior and Kingdom Relations (BZK) |
| NSW artificial intelligence assurance framework | 호주 | 2022 | NSW Government |
| Model rules on impact assessment of algorithmic decision-making systems used by public administration | EU | 2022 | European Law Institute (ELI) |
| Model rules on impact assessment of algorithmic decision-making systems used by public administration | 국제 | 2022 | World Economic Forum (WEF) |
| Responsible AI impact assessment template | 미국 | 2022 | Microsoft |
| Algorithmic impact assessments(AIAs) in healthcare | 영국 | 2022 | Ada Lovelace Institute |
| AI Risk Management Framework(AI RMF) | 미국 | 2022 | National Institute of Standards and technology (NIST) |
AI 위험 평가 프레임워크는 AI 위험을 효과적으로 식별하고 또 그에 부합하는 완화 방안을 구상하는 데 도움이 될 수 있습니다. 그러나 이런 프레임워크의 한계점도 있습니다. 범용성을 추구하다 보니 산업별 특성이나 특정 용도의 제품에서 발생할 수 있는 사항은 포괄적으로 고려하기 어렵기 때문에 하나의 프레임워크로 다룰 수 있는 범위가 제한적이라는 것입니다.[8] 또한 C2AIRA(Concrete and Connected AI Risk Assessment)처럼 위험의 유형에 따른 경감 방안을 제시하는 경우도 있으나[8], 대부분의 프레임워크는 구체적인 경감 방안을 제공하지 않고 사용자의 몫으로 남겼습니다.
그럼에도 불구하고 이러한 프레임워크 간 장단점을 확인하면 상호보완성을 가진 유용한 도구로 발전할 수 있습니다. 또한 이를 활용하는 사용자나 기업들은 위험의 평가와 관리 방안에 대해 잘 구조화된 참고 모델을 보유할 수 있습니다. 아래에서 몇 가지 사례를 살펴보겠습니다.
싱가포르 MAS Veritas Framework
싱가포르에서는 금융당국인 MAS(Monetary Authority of Singapore)의 주관으로 금융기관, 컨설팅사, 빅테크 등이 참여하는 Veritas라는 컨소시엄이 출범하였습니다. Veritas는 3단계 프로젝트 운영을 통한 결과물로 AI와 Data Analytics에 핵심적으로 고려해야 할 ‘FEAT(Fairness, Ethics, Accountability, Transparency)’에 대한 14개 원칙과, 이를 측정하기 위한 평가 방법 및 툴킷, 적용사례를 발표하였습니다.[9] Veritas Framework에서는 위험 관리를 위한 1단계로 AI 시스템을 복잡성(complexity), 중요성(materiality), 영향도(impact)에 대해 위험 평가를 진행하며, 이 평가 결과로 산출되는 위험의 계층(tier)을 위험 수준이라고 할 수 있습니다. 다음으로는 AI 시스템의 위험 수준에 따라 FEAT 측정 및 관리 방법론을 커스터마이징하여 사용할 수 있습니다. 공개 문서들은 Fairness, Ethics, Accountability, Transparency 각각을 측정할 수 있는 체크리스트와 확인된 위험에 대한 조치 방안을 제공하고 있습니다. FEAT 평가 방법론을 인도에서의 Google Pay의 사기 결제 탐지에 적용한 사례를 보겠습니다.[10] [그림 2]에서 볼 수 있듯, Google Pay의 책임성을 평가하기 위해 Google의 3단계 AI 거버넌스 구조를 Veritas Framework의 원칙 7 ‘AIDA(Artificial Intelligence and Data Analytics) 주도 의사결정에서 AIDA를 사용하는 것은 적절한 내부 기관에서 승인한다’와 원칙 9 ‘AIDA를 사용하는 회사는 경영진과 이사회에 AIDA 사용에 대한 인식을 적극적으로 제고한다’에 매핑시켰습니다.
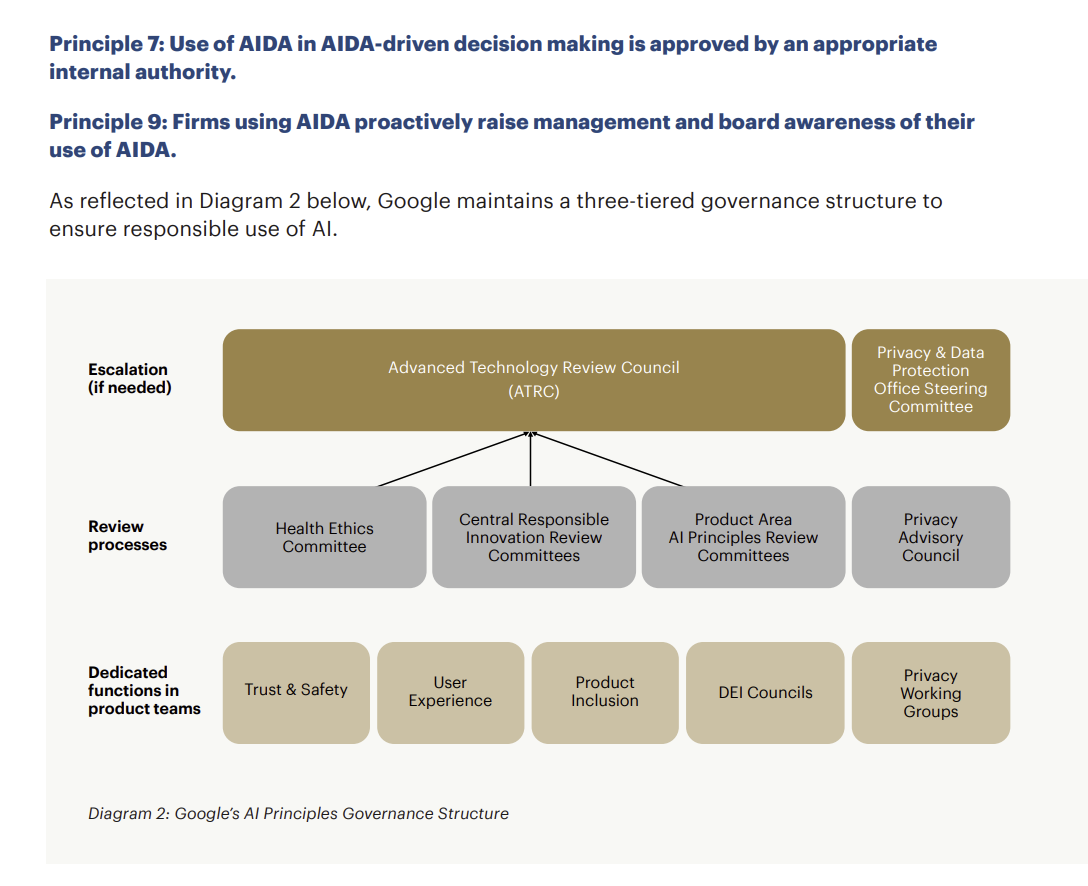 [그림 2] Google Pay 3단계 AI 거버넌스 구조와 FEAT 원칙[10]
[그림 2] Google Pay 3단계 AI 거버넌스 구조와 FEAT 원칙[10]
Principle 7 : Use of AIDA in AIDA-driven decision making is approved by an appropriate internal authority.
Principle 9 : Firms using AIDA proactively raise management and board awareness of their use of AIDA.
As reflected in Diagram 2 below, Google maintains a three-tiered governance structure to ensure responsible use of AI.
Diagram 2: Google's AI Principles Governance Structure
- Escalation(if needed)
-
-
Advanced Technology Review Council(ATRC)
- Health Ethics Committee
- Central Responsible Inovation Review Committees
- Product Area AI Principles Review Committees
- Privacy & Data Protection Office Steering Committee
-
Advanced Technology Review Council(ATRC)
- Review processes
-
- Health Ethics Committee
- Central Responsible Inovation Review Committees
- Product Area AI Principles Review Committees
- Privacy Advisory Council
- Dedicated fucntions in product teams
-
- Trust & Safety
- User Experience
- Product Inclusion
- DEI Councils
- Privacy Working Groups
[그림 2]의 가장 하단에 위치한 Google의 제품 팀에는 사용자 경험, 개인정보 보호, 신뢰 및 안전 전문가 그룹이 포함되어 있습니다. 또한 그 위에는 전담조직을 통해 점검 프로세스가 이루어짐을 확인할 수 있습니다. 원칙 7과 원칙 9에 상응하는 근거 자료를 제시한 셈입니다. Veritas Framework는 금융기관이 AI 및 데이터 분석 솔루션을 검증할 수 있는 방식을 정부와 민간의 협력으로 제공했다는 점에서 의의를 가집니다. 또한 실제 적용 사례를 공개함으로써 더 많은 수의 기업이 공정성 평가 방법론을 채택하는 데 도움을 주고 있습니다.
Google AI Safety & Governance Process
Google이 발표한 AI 안전성 프로세스(Safety & Governance Process)는 생성형 모델과 같이 ‘극도로(extreme)’ 위험한 모델의 평가가 포함되어 있는 것이 특징입니다.[11] 생성형 모델의 경우 범용 모델(general-purpose models)의 특성을 가지고 있습니다. 왜냐하면 생성형 모델은 이미지, 텍스트, 사운드 등을 만들어 내는데 이것은 어떤 특정 서비스에 국한되지 않고 광범위한 산업과 유형의 서비스에 활용될 수 있기 때문입니다. 따라서 범용모델에서 발생할 수 있는 피해는 실로 막대할 수 있으며, 오용되거나(misuse) 적절히 정렬되지 않은(misalign) 범용모델은 극도로 위험한 모델이 될 수 있습니다.[11] 따라서 범용모델의 위험을 평가하기 위해 이미 다양한 시도들이 이루어졌습니다. 실제로 전 OpenAI 연구원이 설립한 Alignment Research Center에서는 언어 모델의 자체 확산 기능을 측정하는 평가를 구축하고 있습니다.[12] 또한 GPT-4 레드팀은 사이버 보안 운영 측면에서 GPT-4의 기능을 테스트하기도 했습니다.[13] Google에서 제시한 극도로 위험한 모델 평가 방법은 [그림 3]과같이 크게 3단계로 나누어지는데, 외부의 독립적인 검증팀이 초기 단계부터 반복적으로 모델의 안정성을 점검한다는 것이 특징입니다. 모델 설계의 맥락을 가장 잘 이해할 수 있는 내부 개발자가 내부 모델 평가(Internal Model Evaluation)를 수행합니다. 하지만 개발팀은 외부의 독립된 검증팀에 모델의 학습 계획 단계부터 보고하여 개발 과정의 투명성을 확보하도록 하고 있습니다.[14]
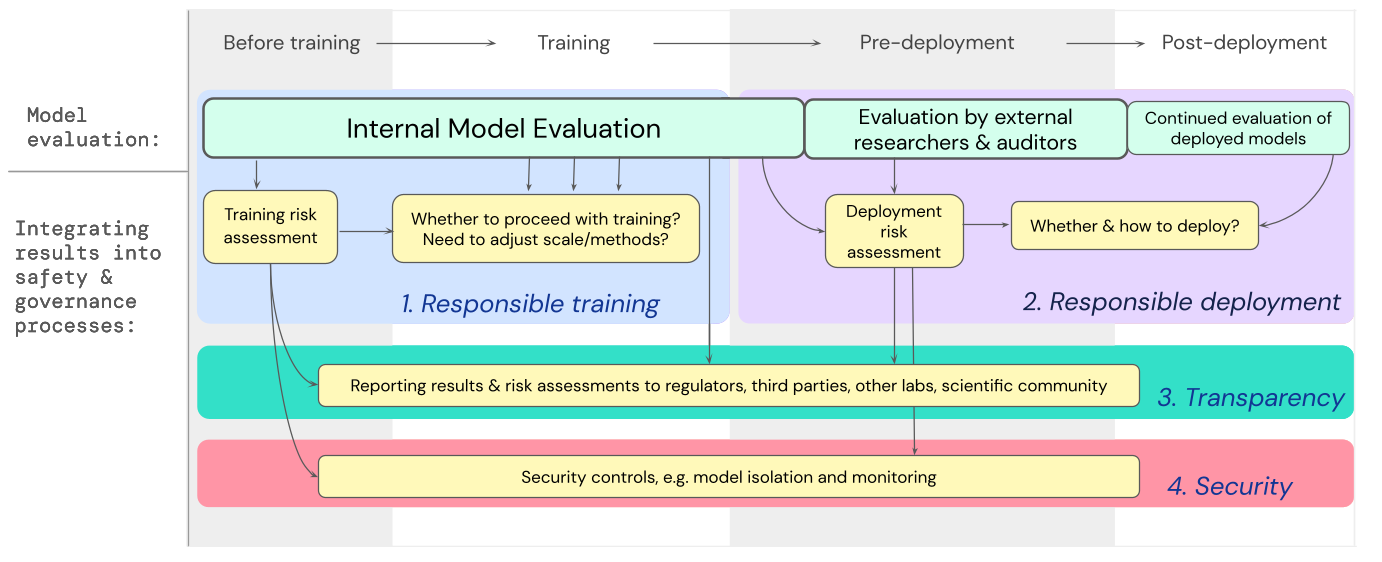 [그림 3] Google AI Safety & Governance Process[14]
[그림 3] Google AI Safety & Governance Process[14]
| Before training | Training | Pre-deployment | Post-deployment | |
|---|---|---|---|---|
| Model evaluation | Internal Model Evaluation | Evalution by external researchers & auditors | Continued evalutation of eployed models | |
| Integrating results into safety & governance processes | Training risk assessment | Whether to proceed with training? Need to adjust scale/method | Deployment risk assessment | Whether & how to deply? |
| Reporting results & risk assessment to regulators, third parties, other labs, scientific community | ||||
| Security controls, e.g. model isolation and monitoring | ||||
모델 개발 후 배포 전에 개발자가 아닌 연구자나 감사자가 평가를 하게 됩니다. 이 과정에서 제3자는 API를 통해 모델에 접근할 수 있으며[15] 이때 제3자는 레드팀이 될 수 있습니다. 끝으로, 모델 배포의 안전성에 대한 판단을 목적으로 최종 외부 감사자가 모델을 평가함으로써 객관성과 투명성을 다시 한번 제고하게 됩니다.[16] 이 방법의 특징은 모델의 개발 단계에 따라 위험 가능성을 원천적으로 차단하려는 노력이 보인다는 것입니다. 또한, 이에 따라 기획 단계부터 잠재적인 위험을 관리할 수 있다는 장점이 있습니다.
지금까지 AI의 잠재적 위험을 판단하는 것이 중요해지고 있는 이유와 AI 위험의 인식과 평가를 위한 접근 방법에 대해 알아보았습니다. 또한 프레임워크를 활용하여 사회적으로 합의되고 공통적인 방식으로 위험을 평가하기 위한 노력이 진행되고 있다는 것을 알게 되었습니다. Veritas Framework와 Google의 Safety & Governance Process처럼 실제로 AI 기획 및 개발 단계에서 프레임워크를 활용하고 있다는 것도 확인할 수 있었습니다.
하편에서는 실제 AI 위험 평가가 어떤 방식으로 이루어지는지에 관한 사례와, EU 및 우리나라에서 시행되거나 논의되고 있는 AI 위험 관리 방안에 대해 살펴보도록 하겠습니다.
References
[1] 법무법인(유)세종(2024). 인공지능기본법 제정안 국회 본회의 통과
[2] 개인정보보호위원회(2025). ‘딥시크 앱’ 국내 서비스, 잠정 중단 후 개선·보완키로
[3] https://www.lawfuel.com/chatgpt-blunder-hits-americas-largest-injury-firm/
[4] NIST(2023). AI Risk Management Framework
[5] Colorado General Assembly(2024). Consumer Protections for Artificial Intelligence: Concerning consumer protections in interactions with artificial intelligence systems
[6] https://www.asiae.co.kr/article/2024120210281102004
[7] P. Slattery et al. “The AI Risk Repository: A Comprehensive Meta-Review, Database, and Taxonomy of Risks From Artificial Intelligence.” (2024)
[8] B. Xia et al. “Towards Concrete and Connected AI Risk Assessment (C2AIRA): A Systematic Mapping Study.” (2023)
[9] Monetary Authority of Singapore(2023). MAS Veritas Framework
[10] Monetary Authority of Singapore(2023). FEAT Principles Assessment Case Studies
[11] Google DeepMind. “Model evaluation for extreme risks.” (2023)
[12] https://evals.alignment.org/blog/2023-03-18-update-on-recent-evals/
[13] OpenAI(2023). GPT-4 system card
[14] D. Raji et al. “Closing the AI accountability gap: Defining an End-to-End Framework for internal algorithmic auditing.” (2020)
[15] E. Bluemke et al. “Exploring the relevance of data Privacy-Enhancing technologies for AI governance use cases.” (2023)
[16] J. Mökander et al. “Auditing large language models: a three-layered approach.” (2023)
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에게 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의 없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
![]()

정유진 | 삼성SDS 금융컨설팅팀
AI First를 모토로 AX (AI Transformation) 컨설팅을 수행하고 있습니다. 기업의 더욱 안전하고 유익한 AI 활용을 위해 AI Agent, AI 거버넌스 플랫폼 설계에도 참여하고 있으며, 최근에는 AI 위험 수준 평가에 대한 글로벌 동향에 관심을 가지고 연구와 자유기고를 병행하고 있습니다.
조남용 | 삼성SDS 금융컨설팅팀
기업 고객을 대상으로 AI, Digital Transformation 컨설팅을 담당해 왔습니다. 최근에는 AI 사업자 및 이용자가 보다 안전하게 AI를 활용할 수 있는 환경을 제공하고자 AI 위험 평가, 생성형 AI 신뢰성 검증 및 시스템 구현 등에 관한 연구 및 컨설팅을 수행하고 있습니다.