

들어가며
RHEL(Red Hat Enterprise Linux)은 국내뿐 아니라 전 세계에서 가장 인기가 높은 기업용 리눅스 OS이다. 클러스터 운영을 위해 RHEL이 제공하는 HA(High Availability, 고가용성) 기능을 사용하면 운영 중인 노드(Active)에서 장애가 발생할 경우 다른 노드(Standby)가 서비스를 수행하도록 해 중단시간을 최소화할 수 있다.
안정적인 서비스 제공을 위해 꼭 필요한 장애 처리 기능인 HA 클러스터. 기업에서 클러스터를 담당하는 시스템 운영관리자는 어떤 점을 어려워하며 전문가에게 도움을 요청하고 있을까? 필자가 담당하는 RHEL 기술서비스 중에서 RHEL 7의 HA 클러스터 기능과 관련하여 고객사 시스템 운영관리자들로부터 접수받은 약 200건의 문의를 분석해 보았다.
그 결과, △네트워크와 관련된 펜스(Fence) & 리소스 모니터 타임아웃(43%) △현재 클러스터의 리소스와 같은 구성 정보 변경(31%) △클러스터 구성된 노드의 멤버십(7%) △VMware(7%) △실패 이력 제거 방법(3%)의 순으로 문의 빈도가 높은 것으로 나타났다. 본 아티클에서는 이 5가지 항목을 짚어 보고 대응 방안을 살펴보겠다.
장애 극복(Failover) 조건
[그림 1]은 RHEL HA 클러스터 환경 구성 시 아파치(Apache) 서버를 서비스하는 2-노드 클러스터의 예시이다.
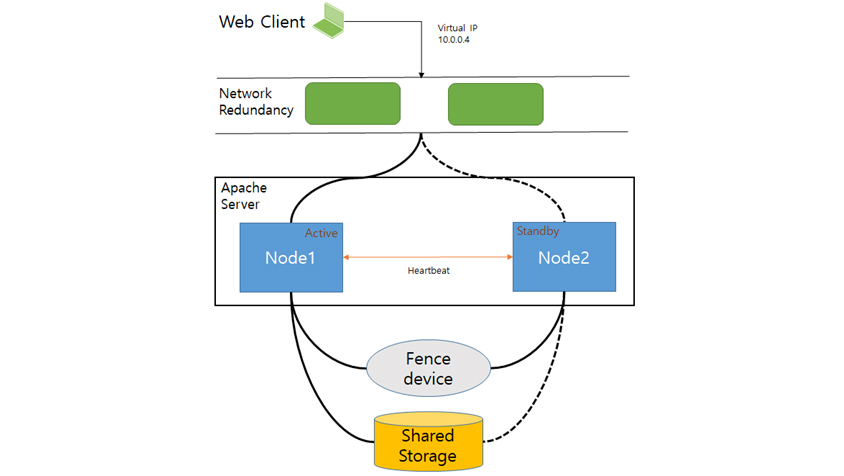
- Virtual IP 10.0.0.4
- Network Redundancy
- Node 1(Active), Node 2(Standby) 상호작용(Heartbeat)
- Fence Device
- Shared Storage
◎ 클러스터 노드는 웹 클라이언트가 가상 IP를 통해 아파치 HTTP 서버에 액세스할 수 있도록 네트워크에 연결된다. 이때 네트워크 장애에 대비해 하나의 네트워크를 더 둔다. 이렇게 두 개의 개별 네트워크를 구성하는 것을 RRP(Redundant Ring Protocol)라고 하며 한 네트워크에 장애가 발생할 경우 다른 네트워크로 통신을 계속할 수 있다.
◎ 하트비트(Heartbeat) 구성을 통해 노드-1, 노드-2에 문제가 있는지 확인한다.
◎ 아파치 서버는 노드-1 또는 노드-2에서 실행될 수 있으며 활성화된 노드는 아파치 데이터가 보관되는 공유 스토리지에 접근할 수 있다.
◎ [그림 1]에서 웹 서버는 노드-1(Active)에서 실행되고 노드-2(Standby)는 노드-1이 작동하지 않는 경우에 서비스를 실행할 수 있다.
◎ 서비스 운영 중 Active 노드에서 문제가 발생하는 경우 펜스(Fence) 장치를 통해 해당 노드가 공유 자원에 접근하지 못하도록 하고 서비스를 Standby 노드로 이관해 운영할 수 있다.
[그림 1]에서 서비스 중인 노드에 리소스 이슈가 발생하거나 네트워크 오류, OS 차제 행(Hang)이 발생하면 자동으로 장애 조치(Failover/Fencing)를 할 수 있다. 기본적인 장애 조치 조건은 아래와 같다.
◎ 서비스 중인 노드의 네트워크 오류로 인해 통신이 되지 않을 때
◎ 리소스 중지 요청 실패
◎ 리소스 모니터 요청이 실패하면 설정에 따라 동일한 노드에서 리소스 재시작이나 장애 조치(Failover/Fencing)
◎ 리소스에 제약 조건(-INFINITY) 설정이 되어 있는 경우 장애 조치(Failover/Fencing) 발생
◎ OS 행(Hang)이나 크래쉬(Crash) 발생 시
클러스터 구성(리소스) 변경
RHEL HA 클러스터 구성 후 리소스에 대한 추가, 제거 및 등록된 리소스 옵션 변경에 관련된 문의를 많이 받는다. 환경에 따라 절차는 달라질 수 있지만 일반적인 방법은 아래와 같다.
# pcs resource [create|update|delete] [등록된 리소스 이름] [리소스 별 옵션]=[값] ……
리소스의 전체 옵션 정보는 다음과 같이 실행하면 확인 가능하다.
# pcs resource describe [리소스 타입]
몇 가지 예제는 다음과 같다.
◎ 파일시스템(Filesystem) 리소스 추가
# pcs resource create [리소스 이름] Filesystem device="[장치 위치]" directory="[Mount Point]" fstype="[Filesystem Type]" run_fsck="no" force_unmount="true" op OCF_CHECK_LEVEL=10 --group [리소스 그룹 이름]
◎ 파일시스템 리소스 옵션 변경
# pcs resource update [Filesystem 리소스 이름] op monitor interval=20 timeout=120 OCF_CHECK_LEVEL=20
◎ 파일시스템 리소스 제거
# pcs resource delete [Filesystem 리소스 이름]
◎ IPaddr2 리소스 추가
# pcs resource create [리소스 이름] IPaddr2 ip=[IP] cidr_netmask=[NETMASK] --group=[리소스 그룹 이름]
◎ IPaddr2 리소스 옵션 변경
# pcs resource update [IPaddr2 리소스 이름] ip=[IP] cidr_netmask=[NETMASK]
◎ IPaddr2 리소스 제거
# pcs resource delete [IPaddr2 리소스 이름]
클러스터 상태 확인 시 나타나는 실패 이력 삭제
클러스터 상태 확인 명령 수행 시(# pcs status) 아래와 같은 내용을 종종 볼 수 있다. 이는 특정 리소스가 수행한 작업에 대해 실패했던 이력을 보여주는 것이다. 시스템 운영관리자는 해당 이슈를 확인, 조치한 후 이력을 제거하는 작업도 해야 한다.
** [fence agent 이름]_monitor_20000 on rhcs01-hb 'unknown error' (1): call=416, status=complete, exitreason='',*
last-rc-change='[발생 시간]', queued=1ms, exec=79ms
이력을 제거하는 방법은 다음과 같다.
# pcs [resource|stonith] cleanup
# pcs status → 이력 삭제 확인
하지만 # pcs stonith cleanup으로 stonith 관련 이력을 삭제할 때 pacemaker 버전을 체크해야 한다. pacemaker-1.1.18-11.el7, pcs-0.9.162-5.el7_5.1 이하인 경우 전체 구성된 리소스가 재시작되는 버그가 있기 때문에 아래 방법으로 이력을 삭제하도록 한다.
# pcs stonith update [fence agent 이름] meta failure-timeout=1m
# pcs stonith update [fence agent 이름] meta failure-timeout=
# pcs status → 이력 삭제 확인
네트워크
RHEL HA 운영 과정에서 발생하는 이슈는 네트워크와 관련된 것이 많다. “/var/log/messages”에서 이슈 내용을 확인할 수 있으며 주로 나타나는 메시지는 다음과 같다.
1) 멤버십(corosync) 관련 메시지
구성된 하트비트 네트워크를 통해 서로 상대방 노드에 문제가 있는지 확인한다. 이슈가 있으면 아래 메시지를 볼 수 있다.
……[TOTEM ] Automatically recovered [RING ID]
FAULTY 이후 1초 내 자동으로 복구되었을 경우에는 간헐적인 네트워크 이슈가 발생한 것으로 네트워크 환경을 확인하여 조치해야 한다.
아래는 패킷 재전송 관련한 메시지이다. 전송 요청된 패킷이 어딘가에서 지연이 발생하여 재전송 요청되었다는 내용이다.
……[TOTEM ] Retransmit List: 42380
……[TOTEM ] Retransmit List: 42380
……[TOTEM ] Retransmit List: 44820
……[TOTEM ] Retransmit List: 44820
……[TOTEM ] Retransmit List: 467a8
위처럼 42380 값이 계속 이어지지 않고 44820로 변경된 것은 패킷 전송이 지연되긴 했지만 결국 전송이 완료되었다는 것을 의미한다. 이 같은 상황이 자주 발생하면 클러스터 서비스에 문제가 생길 수 있으므로 네트워크 환경을 확인하여 조치해야 한다.
아래 메시지는 클러스터 노드 상태에 변경이 있을 때 발생하는 메시지로 네트워크 이슈로 인해 상대방 노드 상태를 확인할 수 없어 클러스터 멤버에서 제외한다는 의미이다.
……[TOTEM ] A new membership ([멤버 IP]) was formed. Members left: 2
……[TOTEM ] Failed to receive the leave message. failed: 2
상대방 노드 상태를 알 수 없는 상황이 지속되는 경우 서비스 시작을 위해 상대 로드를 펜싱할 수 있다.
2) 리소스 모니터 타임아웃
특정 리소스의 상태를 확인할 때 시간 내에 응답을 받지 못하는 경우 아래와 같은 메시지가 나타난다.
…… warning: [리소스 이름]_monitor_30000: …… - timed out after 10000ms
…… error: Result of monitor operation for [리소스 이름] on [노드 이름]: Timed Out
일반적으로 리소스의 모니터 타임아웃이 발생하는 원인은 여러 가지가 있지만 우선적으로 네트워크 문제인지 아니면 시스템 자원을 너무 많이 사용하고 있지 않은지 살펴봐야 한다. 네트워크가 잠시 흔들릴 경우에는 리소스 복구 과정에서 정상화될 수 있다.
“/var/log/messages”에서 리소스 모니터 타임아웃 발생 전·후의 메시지를 확인하여 시스템 자원을 많이 사용하고 있는지 알아본 다음 조치하면 된다.
3) 펜스 모니터 타임아웃
아래 메시지는 펜스 에이전트(Fence Agent)가 펜스 장치의 상태를 모니터링하는 작업이 시간 내에 응답을 받지 못하면서 발생한 것이다.
……notice: Operation 'monitor' [PID] for device '[fence agent 이름]' returned: -201 (Generic Pacemaker error)
……crmd[PID]: error: Result of monitor operation for [fence agent 이름] on [노드 이름]: Error
……pengine[PID]: warning: Processing failed op monitor for [fence agent 이름] on [노드 이름]: unknown error (1)
……warning: fence_ipmilan[PID] stderr: [ Failed: Unable to obtain correct plug status or plug is not available ]
……warning: fence_ipmilan[PID] stderr: [ ]
……warning: fence_ipmilan[PID] stderr: [ ]
응답시간을 늘리거나 펜스 장치와의 통신에 문제가 없었는지 연결 상태를 확인하여 조치한다. ipmitool 툴을 통해 펜스 장치를 확인하는 방법은 다음과 같다.
Ex) /usr/bin/ipmitool -I lanplus -H [IPMI 호스트] -p 623 -U [사용자 이름] -P [비밀번호]
Ex) /usr/sbin/fence_ipmilan -P -a [IPMI 호스트] -l [사용자 이름] -p [비밀번호] -o status –v
모니터링에 실패하면 리소스는 기본적으로 회복(Recover/stop – start) 작업을 수행한다. 일시적인 네트워크 문제라면 회복 작업을 통해 정상화 할 수 있다.
VMware
VMware 가상화 환경에서도 RHEL HA 기능을 사용할 수 있다. 공유 가능한 가상 디스크(VMDK)를 생성하여 서로 다른 가상 머신에서 동일한 디스크로 접근이 가능하다. 이처럼 공유 스토리지 클러스터 솔루션을 사용할 수 있기 때문에 높은 활용도를 보인다. VMware와 관련된 주요 문의는 아래와 같다.
1) VMware 가상화 환경에서 구성 가능 여부
VMware 가상화 환경에서 RHEL HA 구성 가능한 버전은 다음과 같다.
- VMware vSphere: 5.x 및 6.x 버전
- VMware vSphere Hypervisor(ESXi): 5.x 및 6.x 버전
2) VMware 환경에서 확인되는 “/var/log/messages” 내용
VMware 펜스 장치의 상태를 모니터링 하는 작업이 네트워크 및 계정 이슈(vCenter 계정/패스워드변경) 등으로 인해 vCenter와 통신 문제가 있는 경우 아래의 메시지가 나타난다.
……warning: fence_vmware_soap[PID] stderr: [ ]
……warning: fence_vmware_soap[PID] stderr: [ ]
……notice: Operation 'monitor' [PID] for device '[fence agent 이름]' returned: -201 (Generic Pacemaker error)
다음의 메시지는 fence_vmware_rest 스크립트 내에서 UnicodeDecodeError 예외 발생에 의해 나타난다.
해당 예외는 VMware Rest API 단에서의 일시적인 장애이거나 문자열 처리 중 예상치 못하게 Unicode가 들어오면서 발생하는 것일 수 있다. 이러한 에러는 장애 발생 당시 VM annotation이나 name 등 VM 관련 부분 어딘가에 한글과 같은 유니코드가 포함되어 있는지 확인이 필요하다.
VMware 버전 패치로 인해 "vCenter Server Appliance 6.5 U3i" 이상이면 fence_vmware_rest와 vCenter 간 전달·응답 방법 변경으로 인해 감지를 하지 못할 수 있다. VMware 버전 이슈인 경우 fence-agents-vmware-rest-4.2.1-11.el7_6.10.x86_64 이상 혹은 최신 버전을 설치하면 된다.
아래 메시지는 네트워크 지연 발생 또는 pacemaker 노드의 rest agent와 vCenter API 간 응답을 정상적으로 받지 못하면 발생한다.
……fence_vmware_rest: Failed: Unable to obtain correct plug status or plug is not available
……warning: fence_vmware_rest[PID] stderr: [ [발생시간] ERROR: Failed: Unable to obtain correct plug status or plug is not available ]
vCenter 간 네트워크 통신에 문제가 없는지 확인 및 조치가 필요하다. vCenter 통신은 아래와 같이 확인 가능하다.
# fence_vmware_rest --ip [IP] --username "[사용자]" --password "[비밀번호]" --plug [호스트이름] --ssl --ssl-insecure --action status -v
마치며
RHEL HA는 클러스터 환경에서 사용되고 있다. VMware와 같은 가상 게스트에서도 구성이 가능하다. 애플리케이션 가용성을 높이기 위해 하드웨어, 네트워크, 서버 프로세스, WAS, DBMS와 같은 시스템 구성 요소들에 대한 장애 상황 감지 및 장애 극복(Failover) 기능이 지원된다. RHEL HA를 백분 활용하여 클러스터를 안정적으로 운영할 수 있기를 바란다.
References
[1] http://linux-ha.org/doc/man-pages/re-ra-Filesystem.html
[2] https://www.redhat.com/en/store/high-availability-add
[3] https://bugzilla.redhat.com/show_bug.cgi?id=1906502
[4] https://access.redhat.com/articles/3131271
[5] https://access.redhat.com/articles/3349791
[6] https://access.redhat.com/solutions/122293
[7] https://access.redhat.com/solutions/1470423
[8] https://access.redhat.com/solutions/2018033
[9] https://access.redhat.com/solutions/38510
[10] https://access.redhat.com/solutions/4741631
[11] https://kb.vmware.com/s/article/2151774
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에게 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의 없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
![]()

에스코어㈜ 소프트웨어사업부 오픈소스SW그룹
에스코어 소프트웨어사업부에서 Red Hat Enterprise Linux 기술 서비스를 담당하고 있습니다.