

Data Swamp ! !
많은 기업들이 Hadoop과 Cloud 기반의 빅데이터 기술을 사용해 Data Lake의 확장형 아키텍처로 전환하고 있다. 그러나 Data Lake와 빅데이터 기술에 대한 투자 증가(2016년 20.7억달러, 2017년부터 2025년까지 28.6% 성장[1])에도 불구하고 기업의 일부만이 제대로 운영환경에 Data Lake를 배치하고 있다.[2]
이런 원인 중 하나는 많은 기업이 빅데이터 기술과 인프라에 대한 초기 투자 수익을 회수하지 못한다는 것이다. 이런 기업들은 주로 아래의 이유로 Data Lake를 구성하는데 실패하고 데이터 “늪”을 만든다.
⤑ 기술이 아닌 사용자 중심의 데이터 수집, 저장, 가공 및 메타데이터를 잘 관리하는 플랫폼이 필요하다.
2) Data Lake를 실제로 Ad-hoc 탐색, 분석으로만 사용한다.
⤑ 해결해야 하는 다양한 비즈니스 문제를 도출해야 한다.
3) 많이 담을 수 있다고 한꺼번에 너무 많은 쓰레기를 수집한다.
⤑ 초기에는 적은 데이터, 숙제가 있는 데이터를 수집해야 한다.
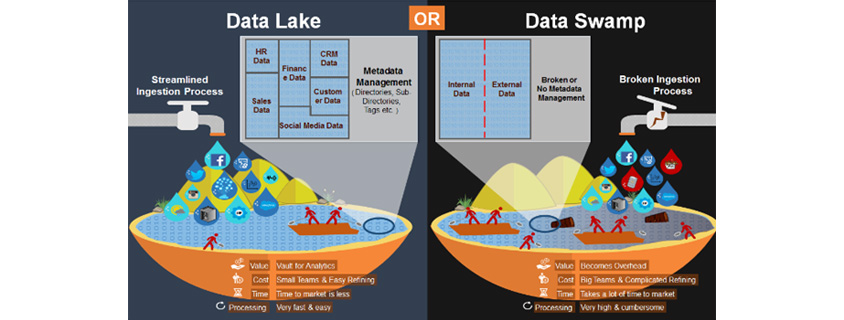 출처: Don’t Let Your Data Lake Turn Into A Data Swamp[4]
출처: Don’t Let Your Data Lake Turn Into A Data Swamp[4]
빅데이터를 잘 활용하는 기업들은 데이터 거버넌스를 기반한 Data Lake의 유연함과 전통적인 DW의 엄격한 제약을 잘 보완한다. 이것이 빅데이터 기술 투자에 대한 ROI를 창출하는 열쇠다.
Data Lake 성공 과정
Data Lake 성공의 첫 단계는 확장성 있는 아키텍처를 설계하는 것이다. 미래 성장을 염두해야 하기 때문에 Data Lake 기술 스택이 복잡하며 스토리지, 프로세싱, 데이터 관리 및 분석 도구에 대해 수많은 결정을 신중히 해야 한다.
두 번째 단계는 Data Lake에 장기적인 데이터 관리 및 거버넌스를 정의하는 것이다.
실험적인 샌드박스 내에서 데이터 관리는 중요하지 않을 수 있다. 그러나 다양한 사용자와 유즈케이스를 갖는 운영계 Data Lake에서의 데이터 관리는 매우 중요하다. 기업은 모든 데이터에 대한 계보와 품질을 명확하게 파악해야 한다.
그 다음, 데이터를 수집, 준비하고 보안을 유지하는 강력한 기능셋을 갖는 것이 매우 중요하다. 기본 플랫폼으로 무엇을 선택하든 다양한 데이터 성격(스트리밍, 배치)과 데이터 저장 구조(오브젝트 스토리지, 플래시, 인메모리, 파일 등)을 처리할 수 있는 기능셋이 있어야 하며 Data Lake가 몇 차례에 걸쳐 진화해도 이 모든 것을 일관성 있게 제공해야 한다.
중요한 점은 빅데이터로 성공을 거둔 기업의 특징이 값싼 저장소에 데이터를 저장하는 것이 아니다. 강력한 메타데이터 기반 데이터 관리 플랫폼을 통해 규모에 따라 건강한 Data Lake를 설계하고 배포하는 것이다. 물론, 이 데이터 관리 플랫폼은 투명성, 확장성이 뛰어난 최신 데이터 아키텍처를 제공해야 한다.
Data Lake 주요 기술 이점
▪ 가치를 창출할 수 있는 데이터의 종류는 무한하다.
- IoT 데이터부터 소셜 미디어 게시물에 이르기까지 모든 유형의 정형 데이터와 다양한 비정형 데이터를 저장할 수 있다.
▪ 모든 답을 미리 가질 필요가 없다.
- 원시 데이터를 저장하기만 하면 된다. 원시 데이터에 대한 이해와 인사이트가 향상될 때 데이터를 정제하면 된다.
▪ 데이터 조회 방법에 제한이 없다.
- 다양한 도구를 사용하여 데이터에 대한 인사이트를 얻을 수 있다.
▪ 더 이상 Silo를 만들지 않는다.
- 조직 전체가 하나의 통합된 뷰로 데이터에 접근할 수 있다.
DW와 Data Lake의 차이
DW와 Data Lake 의 차이점은 다음과 같다. DW는 다양한 기업형 애플리케이션으로부터 데이터를 흡수한다. 당연히 각 애플리케이션의 데이터는 자체 스키마가 있다. 따라서 DW 자체의 사전 정의된 스키마에 맞춰서 데이터를 변환할 필요가 있다.
또한, 기업의 데이터 모델에 맞는 품질의 데이터만 수집되도록 설계되었다.(ETL 필요) 그래서 DW는 제한된 질문에만 답변 가능하며 전사 차원의 사용에 적합하다.
반면, Data Lake는 원시 형태로 데이터를 제공받는다. 조직의 스키마에 맞추기 위해 거의 또는 전혀 손을 댈 필요가 없다. 따라서 수집된 데이터의 구조는 Data Lake에 수집될 때 알 필요가 없고 읽을 때 탐색을 통해 찾는다.
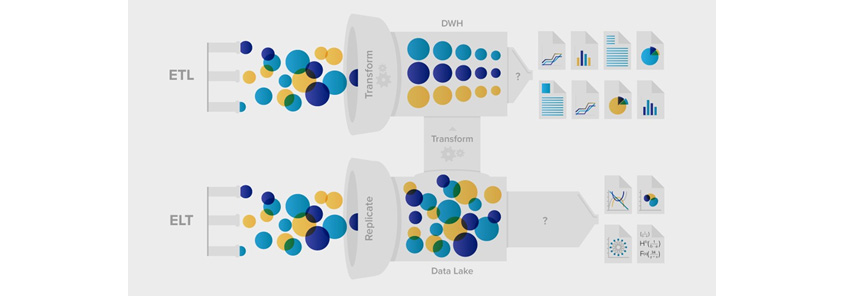 출처: ETL vs. ELT or Data Warehouse vs. Data Lake [5]
출처: ETL vs. ELT or Data Warehouse vs. Data Lake [5]
Data Lake의 가장 큰 장점은 유연성이다. 원시 형태의 데이터를 유지함으로써 훨씬 더 시의적절한 스트림을 데이터 분석에 사용할 수 있다. 표 1은 주요 차이점을 보여준다.
| Attribute | Data Warehouse | Data lake |
|---|---|---|
| Schema | Schema-on-write | Schema-on-read |
| Scale | Scales to moderate to large volumes at moderate cost | Scales to huge volumes at low cost |
| Access Methods | Accessed through standardized SQL and BI tools | Accessed through SQL-like systems, programs created by developers and also supports big data analytics tools |
| Workload | Supports batch processing as well as thousands of concurrent users performing interactive analytics | Supports batch and stream processing, plus an improved capability over data warehouses to support big data inquiries form users |
| Data | Cleansed | Raw and refined |
| Data Complexity | Complex integrations | Complex processing |
| Cost/Efficiency | Efficiently uses CPU/IO but | Efficiently uses storage and processing |
| high storage and processing costs | capabilities at very low cost | |
| Benefits | · Transform once, use many · Easy to consume data · Fast response times · Mature governance · Provides a single enterprise- wide view of data from multiple sources · Clean, safe, secure data · High concurrency · Operational integration |
· Transforms the economics of storing large amounts of data · Easy to consume data · Fast response times · Mature governance · Provides a single enterprise-wide view of data · Scales to execute on tens of thousands of servers · Allows use of any tool · Enables analysis to begin as soon as data arrives · Allows usage of structured and unstructured content form a single source · Supports Agile modeling by allowing users to change models, applications and queries · Analytics and big data analytics |
| Drawbacks | · Time consuming · Expensive · Difficult to conduct ad hoc and exploratory analytics · Only structured data |
· Complexity of big data ecosystem · Lack of visibility if not managed and organized · Big data skills gap |
Data Lake의 비즈니스 사례
지금까지 Data Lake의 기술적 아키텍처 이점에 대해 이야기했다. 이제는 Data Lake가 제공하는 비즈니스 이점에 대해 이야기해 보자. 기업형 DW는 복잡한 분석, 보고 및 운영을 수행하는데 있어 대부분의 조직에 기본적으로 사용되는 솔루션이었다. 그러나 대용량의 광범위하고 다양한 데이터가 표준이 되는 빅데이터 시대에 운영하기에는 너무 엄격하다. DW의 데이터 모델을 변경하는 것은 어려운 일이며 필드 간 통합 매핑은 엄격하고 비싸다.
더 중요한 것은 대부분의 DW 설계가 유연하지 못하고 시스템 복잡성 및 인적 오류를 허용하지 않기 때문에 현업에서 데이터 조작이나 가공을 IT 운영부서에 상당히 의존하고 이로 인해 비즈니스 혁신이 느려진다.
Data Lake는 이러한 문제를 해결 할 수 있다. 거의 모든 산업에서 잠재적인 Data Lake 유즈케이스가 발생한다. 예를 들어, 거의 모든 기업이 고객을 보다 완벽하고 세밀하게 분석하여 이익을 얻을 수 있으며 Data Lake를 통해 해당 고객의 360도 뷰를 파악할 수 있다. Data Lake는 DW를 보완 또는 대체해서 업계 전반에 막대한 데이터의 힘을 발휘할 수 있다.
Data Lake에서 파생된 몇 가지 비즈니스 이점을 살펴 보자.
단일 데이터 모델로부터의 자유
데이터는 정형 또는 비정형일 수 있기 때문에 블로그 포스팅, 제품 리뷰 등 모든 것을 저장할 수 있다. 그리고 데이터는 Data Lake에 저장하기 위해 일관성을 유지할 필요가 없다. 예를 들어 데이터를 제공하는 사람에 따라 매우 다른 데이터 형식으로 동일한 정보를 보유할 수 있다. 이는 DW에서는 문제가 될 수 있지만 Data Lake에서는 서로 다른 데이터 세트 간의 통합 스키마를 염려하지 않고 모든 종류의 데이터를 단일 저장소에 저장할 수 있다.
스트리밍 데이터 처리
오늘날 데이터는 스트리밍 세상이다. 스트리밍 데이터는 IoT 및 주식 시장의 센서데이터부터 소셜 미디어와 같은 매우 일상적인 데이터에 이르기까지 발전해 왔다.
다양한 데이터 도구
DW는 특정 종류의 분석에 적합하고 분석 데이터를 사전 준비하는 시간이 오래 걸릴 수 있다. Data Lake에서는 과도한 사전 작업 없이 다양하고 새로운 빅데이터 도구를 통해 데이터를 효율적으로 처리할 수 있다. Data Lake가 엄격한 메타데이터 스키마를 갖지 않기 때문에 데이터 통합에 필요한 단계가 줄어든다. Schema-on-Read를 통해 사용자는 쿼리 실행 시 자신의 쿼리로 사용자 정의 스키마를 만들 수 있다.
손쉬운 접근성
Data Lake는 DW를 괴롭히는 데이터 통합 및 접근의 어려움을 해결한다. Scale-Out 인프라스트럭처를 사용하면 분석을 위해 더 큰 데이터 볼륨을 통합할 수 있다. 또는 향후 미정의 용도로 저장하기만 하면 된다. 단일 기업형 데이터 모델의 고정된 뷰와 달리 Data Lake를 사용하면 실제로 데이터를 사용할 때까지 모델링을 연기할 수 있으므로 더 나은 인사이트와 데이터 탐색 기회를 만들 수 있다. 이 장점은 데이터 볼륨, 다양성 및 메타데이터가 풍부하게 증가함에 따라 향상된다.
확장성
빅데이터는 일반적으로 데이터의 볼륨, 다양성 및 속도 간의 교차점으로 정의된다. DW는 아키텍처의 제한으로 인해 특정 볼륨 이상으로 확장할 수 없다. 데이터 처리 시간이 너무 오래 걸려 조직이 모든 데이터를 최대한 활용할 수 없다. Petabyte 규모의 Data Lake는 원하는 규모로 구축하고 유지하는데 비용 효율적이고 상대적으로 간단하다.
Data Lake의 단점
무수한 기술 및 비즈니스 이점에도 불구하고 Data Lake를 구축하는 일은 복잡하고 개별 조직마다 상황과 요구가 다르다. 여기에는 다양한 기술 통합과 시장에서 항상 쉽게 사용할 수 있는 기술이 필요하다. 다음은 기업형 Data Lake를 만들기 위해 기업이 알아야 할 3가지 핵심과제다.
가시성
DW와 달리 Data Lake는 데이터 거버넌스가 내장되어 있지 않고, Data Lake 초창기에는 거버넌스를 전혀 고려하지 않았다. 실제로 기업들은 데이터를 관리하지 않고 수시로 적재해 왔다. 대부분 이 방법을 사용하길 원하지만 (대개 빠르고 비용이 덜 든다고 생각하기 때문에) 이런 유형의 데이터 덤프는 궁극적으로 데이터 유형, 데이터 계보, 품질에 대한 가시성이 낮은 데이터 늪으로 이어져 실제로 데이터 검색 및 분석에 자신있게 사용할 수 없다. 데이터가 표준화되지도 않았는데 오류가 허용되지 않는 데이터 정확성이 최우선일 경우, 데이터 덤프는 데이터에서 가치를 끌어내기 매우 어렵다. 특히 Data Lake가 Add-on 기능이었다가 데이터 아키텍처의 핵심으로 전환될 때 그렇다.
거버넌스
데이터가 Data Lake에 유입되면 메타데이터가 자동 적용되지 않는다. 보유 데이터에 대한 정보를 제공하는 세 종류의 1)기술, 2)운영, 3)비즈니스 메타데이터가 없으면, Data Lake를 구성하고 관리 정책을 적용하는 것은 불가능하다. 메타데이터는 데이터 계보 추적, 데이터 품질 모니터링, 데이터 개인정보 보호, 역할 기반 보안 실행, 데이터 수명주기 정책 관리를 가능하게 한다. 이것은 엄격히 규제되는 산업 분야의 조직에 특히 중요하다.
Data Lake는 빅데이터 생태계 내에서 데이터가 사용, 변환되는 방법을 추적하기 위해 메타데이터 도구를 이용해 Data Lake에 통합되는 방식으로 설계되어야 한다. 이것이 올바르게 수행되지 않으면 Data Lake가 운영환경에 배치될 수 없다.
복잡성
거대한 Data Lake 환경을 구축하는 일은 복잡하며 수많은 기술을 통합해야 한다. 또한 미래 성장을 위해 전략적으로 아키텍처를 결정하는 일은 매우 어렵다. 기업은 1) 데이터 Silo를 제거하기 위해 기존 데이터베이스, 시스템 및 애플리케이션을 통합하는 방법; 2) 특정 프로세스를 자동화하고 운영하는 방법; 3) 조직의 민첩성을 높이기 위해 데이터 접근을 확대하는 방법; 4) 데이터를 개인적으로 안전하게 유지하기 위해 전사적인 거버넌스 정책을 구현하고 시행하는 방법을 결정해야 한다.
또한, 대부분의 조직은 기업형 Data Lake를 성공적으로 구축하는 데 필요한 모든 기술을 자체 보유하지 않기 때문에 빅데이터 기술을 학습하고 여러 관련 솔루션 제공업체들을 검토하느라 비용이 많이 드는 실수와 지연을 초래한다.
마치며
성공적인 Data Lake를 구축하는 일은 쉽지 않다. 그러나 Data Lake의 트렌드 현상은 과거 EDW에 열광했던 것처럼 지금 시대의 Must Have 아이템이 되고 있다. 잠깐의 트렌드가 아닌 향후 10년 이상의 장기 핵심기술로 자리잡을 모양새다. 이에 따라 Data Lake 관리 플랫폼도 성장을 지속하고 있다.
References
[1] Worldwide Market Reports, Global Data Lakes Market, November 2018
[2] IDC. “Worldwide Semiannual Big Data & Analytics Spending Guide.” March 2017
[3] Architecting Data Lakes by Ben Sharma
[4] Don’t Let Your Data Lake Turn Into A Data Swamp
[5] ETL vs. ELT or Data Warehouse vs. Data Lake
[6] 데이터 레이크 기술동향과 도입원칙, 정보통신기술진행센터 2018
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
![]()

삼성SDS 개발실 빅데이터개발팀
IoT플랫폼개발그룹으로서, 빅데이터 처리 및 분석 경험을 바탕으로 IoT 및 Data Lake 플랫폼 연구/개발과 빅데이터 전문가로 활동하고 있습니다.