클러스터 리소스 최적화를 위한 Spark 아키텍처 ①

빅데이터 엔지니어링의 중심에 있는 Spark
2003년 Google에서 GFS 논문이 발표되고, 이를 참고하여 개발된 Hadoop 프로젝트가 2006년에 오픈소스로 공개되었습니다. Hadoop을 통해 일반 PC로도 빅데이터를 다룰 수 있게 된 덕분에, 우리는 본격적인 빅데이터 시대를 맞이했죠. 이후 2009년 UC Berkeley AMPLab의 박사과정 중이던 Matei Zaharia는 ‘Mesos’라는 Cluster Manager의 예제 Application을 개발했습니다. 당시 Hadoop의 MapReduce는 기본적으로 Disk I/O를 많이 발생시켰기 때문에 Batch 처리에만 적합했습니다. 이를 극복하기 위해 머신러닝과 같이 반복 작업을 많이 하는 알고리즘이 메모리 상에서 바로 수행될 수 있게 해주는 프레임워크를 Mesos Application으로 개발한 것이죠. 이것이 오늘날 많은 빅데이터 엔지니어가 사용하는 ‘Spark’의 시작입니다. 이후 Spark는 빠른 속도와 강력한 기능으로 인해 많은 개발자들이 찾는 오픈소스가 되었고, 이제는 빅데이터 Ecosystem의 중심에 서 있습니다.
 Hadoop Ecosystem
Hadoop Ecosystem
이제 Spark는 데이터 엔지니어들 사이에서는 흔한 기술입니다. 누구나 빅데이터를 다루기 위해 검토해보는 기본 도구 중 하나가 된 것입니다. 하지만 단순한 작업이 아닌, 기업 환경에서 다양한 사용자의 많은 작업들을 한 번에 처리하는 일은 Spark를 활용해도 쉽지 않습니다. 특히 기업에서 막대한 돈을 쏟아 빅데이터 플랫폼을 구축했는데, 효율적으로 사용하지 못한다면 여간 안타까운 일이 아니죠. 그러나 다행히 Spark는 무책임한 오픈소스가 아니었습니다. 운영자들이 효율적으로 리소스를 관리할 수 있도록 도와주는 여러 기능들을 포함하고 있죠. 앞으로 두 차례에 걸쳐 Spark Architecture에 대한 소개와 함께 리소스를 효율적으로 관리하는 몇 가지 방법을 공유하고자 합니다.
Spark Architecture 101
Spark 리소스를 알아보기 위해서는 기본적으로 Spark Cluster의 Architecture에 대한 이해가 선행되어야 합니다. 하지만 Architecture를 제대로 이해하기 위해선 아티클의 많은 분량을 할애해야 하기 때문에 전체적인 맥락을 파악할 수 있는 수준에서 간략히 소개하겠습니다. Spark는 여러 모듈로 구성되어 있습니다. 크게 두 부분으로 나누어 보면, 컴퓨터 Cluster의 리소스를 관리하는 Cluster Manager와 그 위에서 동작하는 사용자 프로그램인 Spark Application으로 구분됩니다.
Spark Cluster Manager로는 Spark에 built-in된 기본 모듈 Spark Standalone과 Hadoop에서 사용되는 Yarn, 그리고 UC Berkeley에서 개발한 Mesos가 있습니다. 최근의 Spark 2.3부터는 Container Orchestration 도구로 유명한 Kubernetes도 Spark의 Cluster Manager로 사용할 수 있게 되었습니다.
본 아티클에서는 Spark Standalone을 중심으로 이야기를 진행하겠습니다. Standalone Cluster Manager는 Master와 Worker로 구성됩니다. Master 노드에는 Spark Master 프로세스가 실행되고, 나머지 노드에는 Spark Worker 프로세스가 실행되죠. Worker가 Master에 등록되면 Cluster 구성이 완료되고, Spark Master WebUI 또는 Rest API를 통해 연결이 정상적인지 쉽게 확인할 수 있습니다. Cluster가 구성되면, Cluster에 Spark Application을 실행할 준비가 완료된 셈입니다.
 Spark Cluster Architecture
Spark Cluster Architecture
◎ (Spark) Application: Spark에서 수행되는 사용자 프로그램으로, Driver Program과 여러 Executor 프로세스로 구성
◎ Driver Program: main 함수를 실행시키고 그 안에서 SparkContext를 생성하는 메인 프로세스
◎ SparkContext: Driver Program에서 Job을 Executor에 실행하기 위한 Endpoint
◎ Cluster Manager: Application 자원을 할당, 제거하는 등 Cluster 자원을 관리하는 서비스
◎ Master: Standalone의 Master 프로세스 또는 Cluster의 Master 역할로서 Worker를 관리하는 컴퓨터 노드
◎ Worker: Standalone의 Worker 프로세스 또는 Cluster에서 Slave 역할로서 실제 연산 작업을 수행하는 컴퓨터 노드
◎ Executor: Application에서 Driver Program이 요청한 Task들의 연산을 실제로 수행하는 프로세스
◎ Job: Application에서 Spark에 요청하는 일련의 작업. 여러 개의 Task로 나뉘어 실행됨
◎ Task: Spark Executor에서 수행되는 최소 작업 단위
이 Cluster에 Spark Application을 실행한다고 가정해보겠습니다. Application은 기본적으로 Driver Program 프로세스로 실행됩니다. 이 프로그램 안에서는 ‘SparkContext’라는 아주 중요한 객체를 생성시켜야 합니다. 이를 통해 Spark Cluster와 커뮤니케이션할 수 있기 때문입니다. SparkContext를 통해 Application에서 요구하는 리소스를 요청하면, Spark Master는 Worker들에게 요청받은 리소스만큼의 Executor 프로세스를 실행하도록 요구합니다. 또, 내부에서 사용 가능한 CPU cores 숫자도 할당받게 됩니다. 즉, 위 그림에서는 2개의 Executor 프로세스에서 각각 3개 작업을 동시 실행하는 총 6 CPU cores를 할당받음을 볼 수 있습니다. 이 리소스 사이즈는 Application을 실행시킬 때 매개변수나 설정 파일로 전달할 수 있습니다. Application은 1개 이상의 Job을 실행시키고, 이 Job은 여러 개의 Task로 나누어서 Executor에게 요청하고 결과를 받으면서 Cluster 컴퓨팅 작업을 수행합니다.
컴퓨팅 파워 측면에서 리소스를 효율적으로 사용한다는 의미는 주어진 CPU cores를 쉼 없이 최대한 활용하면서, 동시에 사용자들의 여러 작업을 합리적인 선에서 최대한 응답해준다는 것입니다.
안정적 리소스 확보와 빠른 실행을 위한 Spark Context 관리
앞서 설명한 바와 같이 Spark Application이 실행되면, Driver Program은 Spark Context를 생성하면서 이를 통해 Spark Application의 자원인 Executor 수와 각 Executor에서 사용 가능한 CPU cores 수를 확보하게 됩니다. 그 과정에서 Worker에 충분한 리소스가 없다면 오류가 발생되죠. 그리고 Spark Application이 종료될 때, Spark Context가 자원을 해제하면서 모든 Executor 프로세스가 종료됩니다.
이는 1+1과 같이 아주 단순한 작업을 수행함에 있어서도 Spark Context 생성, Executor 프로세스 실행, 작업 완료 후 Application 종료에 필요한 부가 시간이 필수불가결하다는 의미이기도 합니다. 부가 시간은 환경마다 다르겠지만, 필자의 경험상 8초 이상으로 볼 수 있습니다. 8초가 짧은 시간이라 생각할 수도 있지만, 잠깐 동안에도 데이터를 확인하거나 굉장히 많은 Application들이 실행되는 환경에서는 치명적일 수도 있는 시간입니다. 또한 Application 간 데이터가 공유되지 않아 별도의 저장공간에 데이터를 쓰고, 읽는 작업이 추가로 필요합니다. 때문에 전체적인 분석 시간이 늘어날 수밖에 없습니다. 이 문제를 해결하기 위한 방법 중 하나는 Spark Context를 사전에 띄워 놓고, 필요할 때마다 살아 있는 Spark Context에 Job을 요청하는 것입니다.
아래 예시와 같이 Filter → Correlation → Unload(DB) 작업을 수행하는 분석 모델이 있다고 가정해 보겠습니다. 왼쪽의 일반적인 상황에서는 각 Application을 하나씩 수행한 후, 다음 Application을 수행하는 방식으로 모델을 수행합니다. 반면 오른쪽은 하나의 Application을 Daemon 형태로 실행한 후, 이곳에 Job Group들을 실행하는 방식입니다.
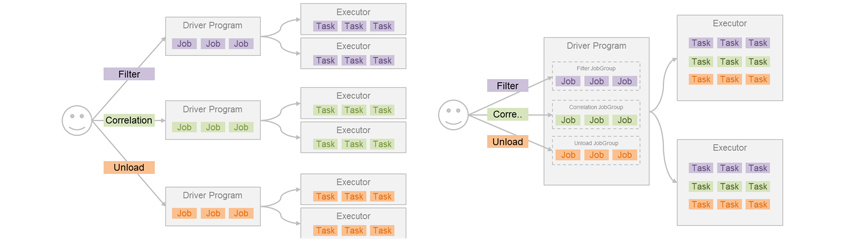 Spark Applications vs Spark Job Groups
Spark Applications vs Spark Job Groups
즉 왼쪽은 Application의 실행/중지가 세 차례 이루어지는 반면, 오른쪽은 단 한 번도 이루어지지 않음을 확인할 수 있습니다. 결과적으로 순수한 분석 시간에는 차이가 없지만 Application 실행/종료에 따른 시간, 각 Application에서 공유하는 데이터를 읽고 쓰는 시간을 줄여서 전체적인 분석 시간을 단축시킬 수가 있습니다. 물론 3개의 함수를 동시에 실행시키는 모델을 하나의 Application으로 작성할 수도 있습니다. 다만 모델 간의 데이터를 호환해야 하거나, 여러 개의 작은 모델을 수행하는 상황이 온다면 또다시 동일한 문제 상황에 직면하게 됩니다.
그렇다면 이 환경을 어떻게 구현할 수 있을까요? 사실 이 문제에 도움을 줄 수 있는 오픈소스 프로젝트가 이미 존재합니다. 미디어 플랫폼 회사 Ooyala에서 공개한 Spark Job Server가 바로 그것입니다. 이를 이용하면 위와 같은 아키텍처를 쉽게 구성할 수 있습니다. 또한 Application 실행을 Spark Submit 명령이 아닌, RESTful API로 처리할 수 있어 활용 면에서도 훨씬 간편합니다.
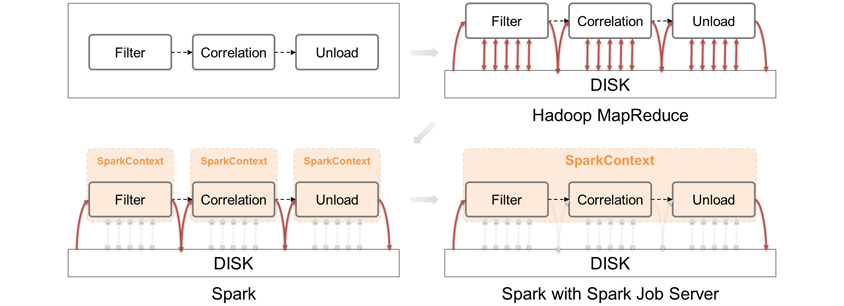 MapReduce vs Spark vs Spark Job Server
MapReduce vs Spark vs Spark Job Server
이렇게 Spark Context를 독립적으로 관리하면 하나의 Spark Cluster에서 Multi-tenancy를 지원할 수도 있고, Application의 리소스 확보도 안정적으로 이룰 수 있습니다. 더불어 Disk I/O도 많이 줄여서 성능 향상도 꾀할 수 있습니다.
지금까지 Spark Cluster에 대한 기본적인 개념과 Spark Job Server를 활용한 효율적인 리소스 관리 방법을 살펴봤습니다. 다음 2편에서는 Spark에서 제공하는 기능(Fair Scheduler, Dynamic Resource Allocation 등)을 통해 다수의 Application이 실행되는 환경에서 효율적으로 Spark 리소스를 제어하는 방법에 대해 전해드리겠습니다.
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
SPARK
BIGDATA
SPARKJOBSERVER
스파크
빅데이터
클러스터컴퓨팅
개념
Architecture
삼성SDS

노광선 프로는 삼성SDS 빅데이터 플랫폼 Brightics AI 개발 조직에서 개발 및 기술 지원 업무를 맡고 있습니다. 사내외 여러 Site에서 Spark, Hadoop 기반의 빅데이터 플랫폼 구축을 위한 기술 지원 업무를 수행했습니다. 현재는 Kubernetes를 활용한 Containerization 업무를 수행하고 있습니다.