새로운 인공지능 기술 GAN ② - GAN의 개념과 이해

지난 아티클에서 소개했던 지도학습은 인공지능 기술의 폭발적인 발전을 선도해왔습니다. 하지만, 모든 데이터에 대한 정답을 개발자가 알려줘야 학습이 가능하다는 특징 때문에 소요 시간 및 리소스의 한계라는 단점이 있고 궁극적으로 인공지능이 가야 할 방향과도 다소 거리가 있습니다. 따라서, 많은 AI전문가들은 미래의 인공지능은 비지도학습이 이끌어갈 것이며 그 중심에는 GAN(Generative Adversarial Networks)이 있을 것이라고 전망합니다.
- 노벨 물리학상을 받은 미국의 물리학자 Richard Feynman
Richard Feynman의 명언은 비지도학습의 의미와 일맥상통합니다. 즉, 단순히 지도학습에 의해 분류만 하는 것이 아니라, 정답 없이 새로운 것을 지속적으로 생성해 낼 수 있는 능력을 가진다는 것은 그 데이터를 완전히 이해하고 있다는 의미로서 생성할 수 있는 능력을 가지게 되면, 분류하는 것도 자동적으로 쉬워진다는 이야기입니다. 어려운 수학 문제를 혼자서 쉽게 풀 수 있어도, 다른 사람에게 이해시키기 위해 설명하는 것은 그보다 어렵지만 다른 사람에게 설명을 잘 할 수 있다면, 그 문제를 푸는 일은 식은 죽 먹기일 것입니다. 이러한 개념이 비지도학습의 대표주자인 GAN에 적용되고 있습니다.
처음 GAN을 제안한 Ian Goodfellow는 GAN을 경찰과 위조지폐범 사이의 게임에 비유했습니다. 위조지폐범은 최대한 진짜 같은 화폐를 만들어(생성) 경찰을 속이기 위해 노력하고, 경찰은 진짜 화폐와 가짜 화폐를 완벽히 판별(분류)하여 위조지폐범을 검거하는 것을 목표로 합니다. 이러한 경쟁적인 학습이 지속되다 보면 어느 순간 위조지폐범은 진짜와 다를 바 없는 위조지폐를 만들 수 있게 되고 경찰이 위조지폐를 구별할 수 있는 확률도 가장 헷갈리는 50%로 수렴하게 되어 경찰은 위조지폐와 실제 화폐를 구분할 수 없는 상태에 이르게 됩니다.
여기서 경찰은 분류 모델, 위조지폐범은 생성 모델을 의미하며, GAN에는 최대한 진짜 같은 데이터를 생성하려는 생성 모델과 진짜와 가짜를 판별하려는 분류 모델이 각각 존재하여 서로 적대적으로 학습합니다.

적대적 학습에서는 분류 모델을 먼저 학습시킨 후, 생성 모델을 학습시키는 과정을 서로 주고받으면서 반복합니다. 분류 모델의 학습은 크게 두 가지 단계로 이루어져 있습니다. 하나는 진짜 데이터를 입력해서 네트워크가 해당 데이터를 진짜로 분류하도록 학습시키는 과정이고 두 번째는 첫 번째와 반대로 생성 모델에서 생성한 가짜 데이터를 입력해서 해당 데이터를 가짜로 분류하도록 학습하는 과정입니다. 이 과정을 통해 분류 모델은 진짜 데이터를 진짜로, 가짜 데이터를 가짜로 분류할 수 있게 됩니다. 분류 모델을 학습시킨 다음에는 학습된 분류 모델을 속이는 방향으로 생성 모델을 학습시켜줘야 합니다. 생성 모델에서 만들어낸 가짜 데이터를 판별 모델에 입력하고, 가짜 데이터를 진짜라고 분류할 만큼 진짜 데이터와 유사한 데이터를 만들어 내도록 생성 모델을 학습시킵니다.
이와 같은 학습과정을 반복하면 분류 모델과 생성 모델이 서로를 적대적인 경쟁자로 인식하여 모두 발전하게 됩니다. 결과적으로, 생성 모델은 진짜 데이터와 완벽히 유사한 가짜 데이터를 만들 수 있게 되고 이에 따라 분류 모델은 진짜 데이터와 가짜 데이터를 구분할 수 없게 됩니다. 즉, GAN은 생성 모델은 분류에 성공할 확률을 낮추려 하고, 분류 모델은 분류에 성공할 확률을 높이려 하면서 서로가 서로를 경쟁적으로 발전시키는 구조를 이루고 있습니다.

보다 구체적으로, GAN은 아래와 같은 목적함수 V(D,G)를 이용하여 아래 수식처럼 minmax problem을 푸는 방식으로 학습하게 되며, 여기엔 GAN의 기본적인 학습내용이 모두 포함되어 있습니다.
![min/G max/D V(D,G) = E <sub>(x~pdata<sup> (x)</sup>)</sub> [logD(x)]+E <sub>(z~pz<sup>(z)</sup></sub>) [log(1 - D(G(z))]](https://image.samsungsds.com/global/ko/support/insights/gan2_05.jpg?queryString=20200929112822)
위 수식에서 X~Pdata (x)는 실제 데이터에 대한 확률분포에서 샘플링한 데이터를 의미하고 Z~Pz(z)는 일반적으로 가우시안분포를 사용하는 임의의 노이즈에서 샘플링한 데이터를 의미합니다. 여기서 z를 통상적으로 latent vector라고도 부르는데 차원이 줄어든 채로 데이터를 잘 설명할 수 있는 잠재 공간에서의 벡터를 의미합니다. 본론으로 돌아가서, D(x)는 분류자이고 진짜일 확률을 의미하는 0과 1사이의 값이라서, 데이터가 진짜이면 D(x)는 1, 가짜이면 0의 값을 내놓습니다. 두 번째 항에 있는 분류자인 D(G(z))는 G가 만들어낸 데이터인 G(z)가 진짜라고 판단되면 1, 가짜라고 판단되면 0의 값을 가지게 됩니다.
우선 D가 V(D,G)를 최대화하는 관점에서 생각해봅시다. 위의 수식을 최대화하기 위해서는 우변의 첫 번째 항과 두 번째 항 모두 최대가 되어야 하므로 logD(x)와 log(1 -D(G(z)) 모두 최대가 되어야 합니다. 따라서, D(x)는 1이 되어야 하며 이는 실제 데이터를 진짜라고 분류하도록 D를 학습하는 것을 의미합니다. 마찬가지로 1-D(G(z))는 1이 되어 D(G(z))는 따라서 0이어야 하며, 이는 생성자가 만들어낸 가짜 데이터를 가짜라고 분류하도록 분류자를 학습하는 것을 의미합니다. 다시 생각해보면 V(D,G)가 최대가 되도록 D를 학습하는 것은 판별자가 진짜 데이터를 진짜로, 가짜 데이터를 가짜로 분류하도록 학습하는 과정입니다.
다음으로 생성자G가 V(D,G)를 어떻게 최소화하도록 학습하는 지에 대한 관점에서 생각해봅시다. 위의 수식의 우변 첫 번째 항에는 G가 포함되어 있지 않으므로 생성자와 연관이 없어 생략이 가능합니다. 두 번째 항을 최소화하기 위해서는 log(1 - D(G(z))가 최소가 되어야 합니다. 따라서 log(1 - D(G(z)는 0이 되어야 하고 D(G(z))는 1이 되어야 합니다. 이는 판별자가 진짜로 분류할 만큼 완벽한 가짜 데이터를 생성하도록 생성자를 학습시키는 것을 의미합니다. 이처럼 V(D,G)를 최대화하는 방향으로 분류자 D를 학습하고, V(D,G)를 최소화하는 방향으로 생성자를 학습하는 것을 Minmax problem이라고 합니다.
이때, 생성 모델로서의 GAN이 우연히 데이터를 우연히 만들어 내는 것인지, 데이터를 완벽히 이해하고 있는 가치 있는 모델인지를 알아보는 것이 매우 중요합니다. 이를 위해 생성자로서의 메커니즘을 좀 더 심도 있게 분석해 봅시다. 앞에서 설명한 latent vector z는 생성자 G의 입력으로 사용됩니다. G의 출력이 사람의 얼굴이라고 했을 때, 왼쪽을 바라보는 얼굴을 만들어 내는 z(왼쪽)들의 평균벡터와 오른쪽을 보고 있는 얼굴에 대응하는 z(오른쪽)들의 평균을 계산하고 이 두 벡터사이의 축을 중간에서 보간(interpolation)하여 생성자로 입력하면 천천히 회전하는 얼굴이 나오는 것을 확인할 수 있습니다.
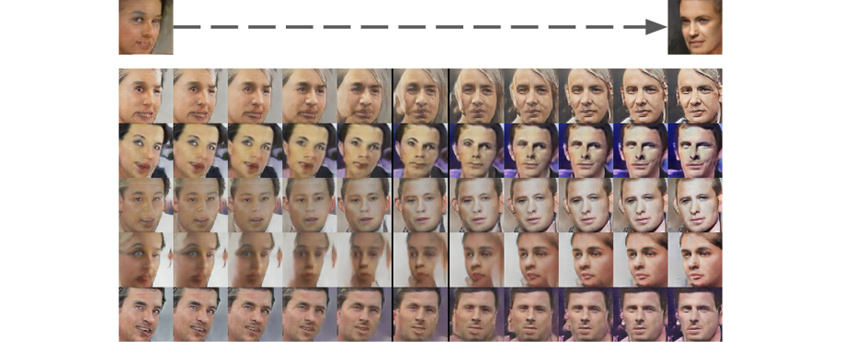
이 결과는 생성자가 학습한 딥러닝 매핑 (z→G(z))이 단순히 불연속적인 1:1 매칭이 아니라, 정확히 영상의 의미를 이해하고 영상이라는 데이터의 확률분포를 정확히 표현하고 있어서, 입력에서의 약간의 변화가 출력에서도 부드러운 변화로 표현 가능하다는 놀라운 사실을 보여줍니다.
이러한 GAN의 놀라운 개념을 증명시켜주는 유명한 사례에는 이미지의 산술적인 연산이 있습니다. ‘안경을 쓴 남자’ 이미지를 생성하는 z 에서 ‘안경을 쓰지 않은 남자’ 이미지의 입력인 z 를 빼고 ‘안경을 쓰지 않은 여자’ 이미지에 해당하는 z 를 생성자 G에 넣어주면 ‘안경을 쓴 여자’ 이미지가 아래 그림처럼 생성된다는 것이 밝혀졌습니다.

이는 GAN 생성자의 결과물을 우리가 원하는 데로 마음껏 조작할 수 있다는 가능성을 확인한 것이며, 단순한 데이터의 분류로서의 이해가 아닌 새로운 것을 창조할 능력을 가지게 된 것을 의미합니다 (Now, I can create!).
이상으로 비지도학습 GAN에 대해 설명드렸습니다. 다음 아티클에서는 GAN의 다양한 적용 사례를 살펴보겠습니다.
* ICON 출처
Icons made by Freepik from www.flaticon.com is licensed by CC 3.0 BY
Icons made by monkik from www.flaticon.com is licensed by CC 3.0 BY
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의없이 2차 가공 및 영리적인 이용을 금하고 있습니다.

장준혁 교수는 한양대학교 융합전자공학부 교수로 재직 중입니다. 인공지능 딥러닝 및 음성인식 분야의 권위자로 Elsvevier Digital Signal Processing 편집위원, 한국통신학회 신호처리연구회 위원장 등 폭넓은 활동을 전개하고 있으며, AI스피커 연구, 딥러닝 음성인식, 바이오진단 등의 분야에 연구를 진행하고 있습니다.