알기쉬운 딥러닝 - 딥러닝과 빅데이터란 무엇인가?
빅데이터 시대가 열린 이후 다양한 기술 핫 키워드가 등장하기 시작하였다. 특히, 올해 3월 구글의 알파고와 이세돌 9단이 바둑 대국을 한 이후 인공지능(Artificial Intelligent, AI)이 세계를 강타했다. 그로 인해 딥 러닝(Deep Learning)과 머신 러닝(Machine Learning)에 대해서도 관심이 증폭되었다. 과연 딥 러닝과 머신 러닝이 무엇인지, 딥러닝과 빅데이터 사이에 연관성이 있는지 알아보도록 하자. 또한, 딥러닝의 응용사례도 살펴보도록 하자.
딥 러닝(Deep Learning)이란?
엑셀에서 데이터의 추세선 옵션을 이용한 그림 그리기는 한번쯤은 해보거나 보았을 것이다. 이는 회귀분석(Regression Analysis)을 엑셀로 활용한 아주 간단하고 쉬운 방법 중 하나이다. 많이 들어봤겠지만 회귀분석은 데이터간의 관계를 분석하고 모델식을 만드는 데이터 마이닝 기법 중에 하나이다. 정확성이 상대적으로 떨어지고 모델 정교화를 위해 분석가의 노력이 많이 필요하다는 단점을 가지고 있다. 그래서 등장한 것이 인공신경망(Artificial Neural Network, ANN)이다. 이는 사람의 뇌를 영상케하는 방법으로, 블랙박스 형태로 데이터를 입력하면 자동으로 복잡한 수학식으로 모델링 되는 기법이다. 예를 들면, 텍스트, 사진, 동영상 등에서 강아지를 구분해야 할 때 강아지의 특징들을 확인하고 다양한 요소들을 조합하여 자동으로 강아지를 검출한다.
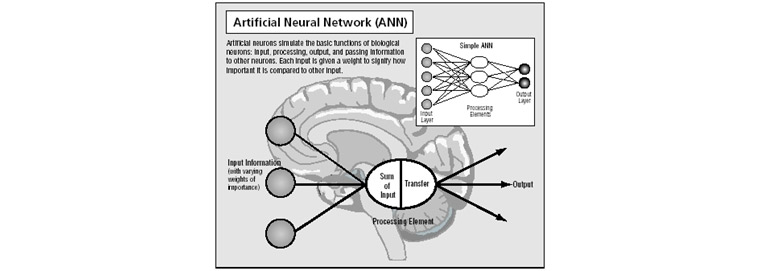 | 인공신경망 (출처: Science Clarified 홈페이지)
| 인공신경망 (출처: Science Clarified 홈페이지)
훈련 데이터(Training Data)를 통해 학습된 속성을 기반으로 예측 및 분류하는 알고리즘을 연구하는 분야를 우리는 머신 러닝(Machin Learning; 기계학습)이라고 부른다. 즉, 인공신경망은 머신 러닝의 한 분야이다. 인공신경망의 정확성을 높이기 위해 학자들의 연구가 많이 이루어졌다.
특히 최적화 이론(Optimization)과 다양한 커널 함수(kernel function)를 활용해서 모델식의 정확성을 높였다. 또한, 빅데이터 기술이 등장하면서 많은 데이터를 모델링에 쓸 수 있었으며 정확성도 더욱 높아지는 효과를 볼 수 있었다. 여기서 인공신경망에 빅데이터를 결합한 것을 우리는 딥 러닝(Deep Learning)이라고 부른다. 따라서 딥 러닝은 머신 러닝의 한 종류라고 할 수 있다.
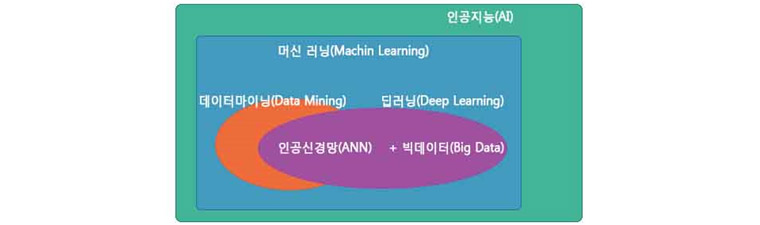 | 머신 러닝, 딥 러닝, 빅데이터 관계도
| 머신 러닝, 딥 러닝, 빅데이터 관계도
더 자세히 이야기하면 강아지를 분류할 때 인공신경망은 분석가가 사진 속 이미지가 강아지인지 아닌지를 미리 알려줘야 한다. 또한 강아지의 특징을 사람이 미리 정의 내려야 한다. 하지만 딥 러닝은 강아지를 포함한/포함하지 않는 사진을 방대하게 주고 자동으로 강아지인지 아닌지를 군집화하고 분류한다.
즉, 사람의 노력 없이 컴퓨터가 스스로 훈련해서 강아지의 패턴을 찾아내고 자동으로 분류해준다. 이를 가능하게 해준 것이 빅데이터 기술이다.
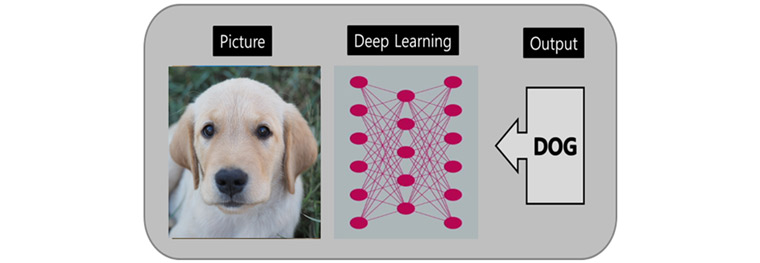 | 딥 러닝을 활용한 강아지 분류
| 딥 러닝을 활용한 강아지 분류
딥 러닝을 주로 사용하는 분야는 음성인식 및 이미지 인식이다. 데이터 양도 많아지고 있고, 정확성이 상대적으로 높기 때문에 딥러닝 기술을 활용하여 많은 기업에서 관련 서비스를 제공하고 있다. 예를 들면 페이스북, 구글이 대표적인 기업이다.
페이스북 사용자라면 누구든지 알 것이다. 친구들과 찍은 사진을 올리면 자동으로 친구의 이름이 태그 되는 것을 볼 수 있다. 이는 딥 러닝 기술을 활용하여 친구의 얼굴을 인식하고 분류하는 딥 페이스(Deep Face)라는 알고리즘이다. 인식 정확도는 97.25%이며 인간이 인식(97.53%)한 것과 거의 비슷하다고 할 수 있다. 딥러닝 기술은 광고에도 활용되고 있다. 게시한 사진의 제품을 분석하여 이를 기반으로 사용자에게 맞춤형 광고를 하고 있다.
 | 페이스북의 딥페이스 기술 (출처: mirror.co.uk)
| 페이스북의 딥페이스 기술 (출처: mirror.co.uk)
구글에서는 사진 태킹, 음성 인식에 딥 러닝을 활용하고 있다. 오래 전 개발되었던 구글 번역기도 딥 러닝 기술을 활용한 이후 정확도가 점점 높아지고 있다. 또한, 구글은 이용자들의 사진들을 인식하고 분류해 앨범을 자동으로 만들어주는 서비스도 제공하고 있다.
중국의 구글이라고 불리는 바이두는 음성인식, 이미지 인식, 이미지 검색 기능을 강화하기 위해 딥러닝 기술을 사용하고 있다. 국내의 경우, 네이버의 음성 검색에서 딥 러닝 기술을 적용하고 있다. 또한 뉴스 요약 및 이미지 분석에도 딥 러닝을 확대 적용하고 한다.
 | 딥러닝을 활용한 네이버의 음성검색 (출처: bloter.net)
| 딥러닝을 활용한 네이버의 음성검색 (출처: bloter.net)
올해 초 구글이 개발한 알파고로 인해 세상이 들끊면서 인공지능에 대한 인기가 치솟았다. 알파고도 딥 러닝 기술을 활용한 사례라고 볼 수 있다. 또한, 자동차 무인주행도 마찬가지로 딥 러닝을 활용하였다. 아직은 안전상의 문제로 대중화되지는 못했지만, 예전에 비해 기술발전이 크게 이루어지고 있다.
과거의 경우 차가 건널목을 지나려고 할 때 건널목에 사람이 있는지, 차가 있는지, 신호가 바꿨는지 등등 일일이 사람이 질문을 만들어서 넣어줘야 했다. 하지만 지금은 건널목에서 차가 지나갈 때의 위험한/정상인 상황의 방대한 동영상 및 사진 데이터를 넣어두고 컴퓨터가 그 데이터를 학습하고 건너야 할지 말아야 할지를 자동으로 파악한다.
알파고도 마찬가지로 수많은 바둑 상황 데이터를 넣어두고 상황에 맞게 자동 판단한다. 다른 점은 가능한 모든 상황에 따라 이길 확률을 계산하고 확률이 높은 수를 선택한다는 것이다. (Monte-Carlo Tree Search 방법 사용)
 | 구글의 알파고와 무인주행 (출처: 주간 동아) (출처: bloter.net)
| 구글의 알파고와 무인주행 (출처: 주간 동아) (출처: bloter.net)
인공신경망의 기술적 발전과 방대한 데이터를 다룰 수 있는 빅데이터 기술의 발전으로 인해 딥 러닝은 우리 생활에서 큰 역할을 하기 시작하였다. 하지만 다양하고 방대한 데이터의 보유 여부에 따라 딥 러닝의 성공여부가 갈린다. 즉, 아직 발생하지 않았거나 거의 발생하지 않는 상황의 데이터까지 컴퓨터가 자동으로 판단할 수 없다. 이런 함정으로 인해 5번의 경기 중 이세돌 9단이 이길 수 있었던 계기가 된 것이다. 무인주행의 사고 또한 마찬가지이다.
많은 양의 사고 영상 및 위험한 상황의 데이터를 보유하고 있어도 우리가 상상하지 못하는 사고는 항생 발생하기 마련이다. 딥 러닝의 성공적 적용을 위해서는 다양한 데이터의 수집하고 우리가 알지 못하는 미지의 상황에 대한 대체방법을 생각해야 한다.
많은 양의 데이터가 있더라도 그것을 어떻게 딥 러닝 기술로 활용할 것인지, 정확도를 높이기 위한 미세 조정을 어떻게 할지, 인간이 만족할 만한 수준에 이르기까지 앞으로 많은 노력과 비용이 들것이라 생각한다.
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에게 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의없이 2차 가공 및 영리적인 이용을 금하고 있습니다.

김서연 수석보는 2009년 미국 조지아텍 산업공학과 박사학위를 취득하고 싱가포르 국립대학교 산업공학과에서 연구원으로 근무하다가 2010년 9월에 삼성SDS 인프라사업부로 입사를 하였습니다. 현재 Data Scientist로써 다수의 빅데이터 과제를 진행하고 있으며 데이터분석 및 Data Scientist 양성과정을 개설하고 사내 강사로 활발히 활동하고 있습니다. 또한, CommonSDS 뿐만 아니라 IE매거진에도 빅데이터 관련 글을 기고함으로써 관련 지식을 전파하고 사내외 세미나를 통해 빅데이터 지식 교류 등 폭 넒은 활동을 하고 있습니다.