

Many organizations dream of automated operations through DevOps. Surely, automation is an important principle for DevOps, but that’s not all. The real DevOps philosophy is, like the Agile philosophy, to quickly and securely deliver customer-based value. Introducing one or two automation tools alone cannot achieve the desired amount of transfer lead time reduction or robust operation improvement. Therefore, I suggest a guide from the engineering perspective for organizations that partly introduced DevOps and only found its performances falling short of their expectations or for organizations that want a genuine enhancement of Agile values.
Agile philosophy enabling the quick transfer and constant enhancement of customer values centered around the most viable products (MVPs) are spreading in the development ecosystem. Even organizations that lack the Agile culture use Agile methods partially, such as Scrum processes and activities. Even if Agile is applied at some level, the more time spent in operation and maintenance for developed applications, the slower the delivery of customer value with insufficient operational stability and quality. The two characteristics, operational stability and agility, are traded off and hard to achieve when the business values from the application grow. DevOps aims to expand the Agile value from development to operations and ensure stability. So, DevOps is an Agile version with expanded operation capability. (Figure 1)
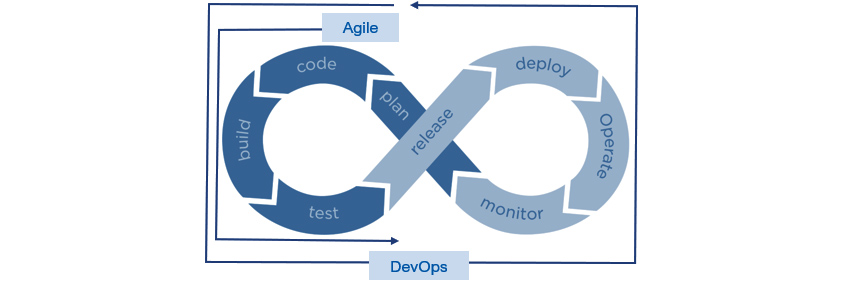
- plan -> code -> build -> test
- -> release -> deploy -> operate -> monitor
Some people define DevOps only as continuous integration (CI) or continuous delivery or deployment (CD), or they see it in the context of automated deployment. However, the author defines it as a collection of philosophies and practices (techniques and practical actions) to cooperate with development and operation to achieve one successful business goal. DevOps processes have a circular structure where development and operation are linked in one process and constantly improved. This shows applying Agile is not one direction and a single work and can improve all related things, including the application itself, process, tools, and practices through management and maintenance. In 2016, IBM released a DevOps methodology, Garage (Figure 2), to suggest a circular process with development and operation that is 100% integrated based on the shared philosophy (culture) of Agile.
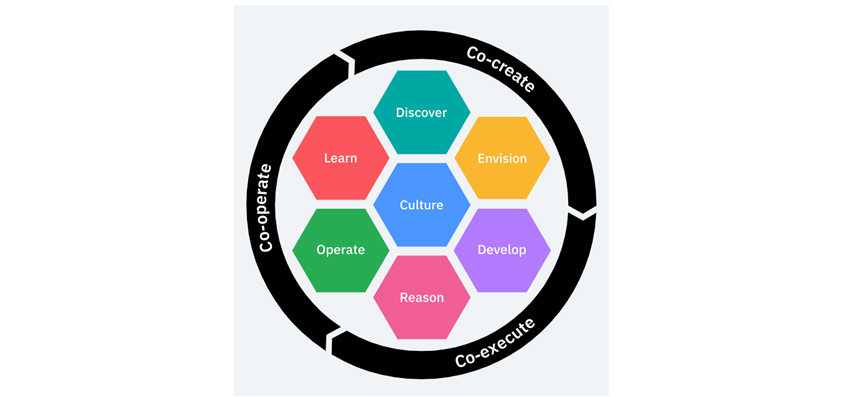
- discover, learn, culture, envision, operate, reason, develop
Customer value is produced and refined through design thinking (or its subset). Such refined requirements are developed through Agile engineering practices and delivered to customers through code-based verification and automated deployment. Various indicators required for operation and quantitative figures of customer value are collected and measured in real time to be used for improvement and problem prevention. Failures that can be solved by themselves are cleared sometimes through automation workflow or cloud-native architecture. Customer feedback, stakeholder reviews, and internal retrospective and post-mortem activities are reflected in the earlier process of DevOps for continuous improvement.
Today, Agile and DevOps have become essential for organizations to value and seek out. In some industries, those even influence the survival of the business. Organizations that have partially adopted DevOps already should try to apply it across their organization.
I learned how DevOps is applied in developing and running a super scalable backend system from hands-on experience. I chose the engineering approach (rather than a cultural approach) to explain how to apply DevOps in five topics successfully.
1. Architecture aspect - Acceptance of cloud native
The cloud-native approach accelerates the implementation of DevOps. However, in reverse, DevOps is used to actualize cloud native. One notion does not belong to another. Implementing DevOps to deliver customer-based values as agile and stable as possible is practically impossible without cloud native.
The term “cloud native” is described in a various way over the past years. Some explained cloud native as workloads ported to the cloud, while some vendors focused on PaaS (Platform as a Service) to explain it. Those are misunderstandings. Cloud native is different from cloud computing. Cloud native is an architecture and adoption strategy that “makes the most use of the cloud.” It is a computing philosophy to maximize agility, portability, failover, and automatic scalability, and the best technology and architecture to practice DevOps and Site Reliability Engineering (SRE) philosophies.
Gartner defines how to achieve cloud native in two approaches, which I prefer a lot. The first one is container native, and the second one is Cloud Service Provider (CSP) native. The former is achieved by utilizing the major technologies of the Cloud Native Computing Foundation (CNCF), such as containers and Kubernetes. The latter is accomplished by the cloud service provider's capabilities, such as the application hosting Platform as a Service (PaaS ), Azure app services, Azure Functions, Azure Container Apps, or AWS Lambda. Container native can be implemented by open-source software (OSS ) technology. Therefore, organizations carefully review whether to implement cloud native based on their open-source capabilities.
In my experience, it was not easy to install on your own (the so-called Vanilla Kubernetes), configure, and use Kubernetes. Further, configuring and running thousands of Kubernetes ecosystems’ OSS is hard to achieve without skilled OSS capabilities. If your organization has enough OSS capabilities, it can build and run the Kubernetes ecosystem through IaaS or directly build its computing environment. Before the AWS Elastic Kubernetes Service (EKS) was launched, our organization also configured and operated a Kubernetes environment for some microservices directly into VM using an OSS called Kops (https://kops.sigs.k8s.io/). It was a huge challenge to manage the control plane, upgrade the Kubernetes versions, and patch it while maintaining the best node images. Kops didn’t support node auto-scaling, so our organization had to set separate auto configurations on the monitoring environment. (Today, kops auto-scaling is available through CNCF's separate OSS.) Here is the conclusion: Even organizations with OSS capabilities struggle.
Even if container-native organizations can handle difficult Kubernetes management, they should carefully review and select the necessary tooling. They should choose mature tooling in the CNCF Landscape (https://landscape.cncf.io/, Figure 3). The maturity can be defined by the number of contributors, commit and release frequency, and the number of stars in GitHub. Of course, a proof of concept (PoC) or pilot test should be performed before the actual application. When choosing an OSS, you should always look at security vulnerabilities, functional errors, performance issues, and licensing issues. When the tools are chosen, it is required to select operator installation over direct installation. Most tools provide an operator (https://operatorhub.io/), which facilitates configuration and integrated operations in a Kubernetes environment. For example, using a Redis for in-memory persistence facilitates configuration and operation through the Redis Operator (https://operatorhub.io/operator/redis-operator), not installing with a Statefulset yaml. Operators offered by the Operator Hub provide a capability level (Figure 4), and selecting the Seamless Upgrades level or higher is recommended. To check the capability level, visit https://sdk.operatorframework.io/docs/overview/operator-capabilities/.
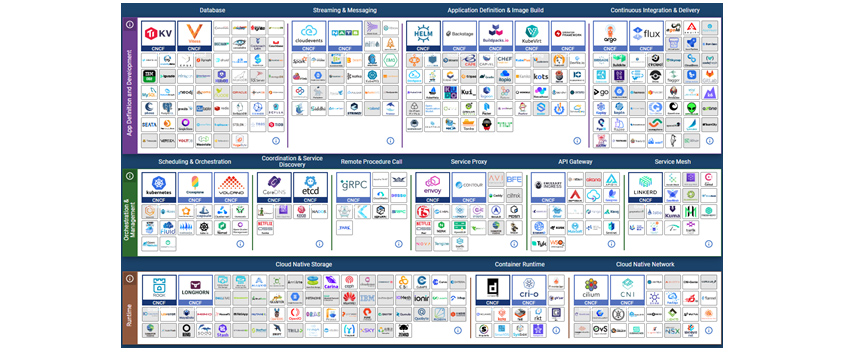 [Figure 3] Cloud-native landscape
[Figure 3] Cloud-native landscape
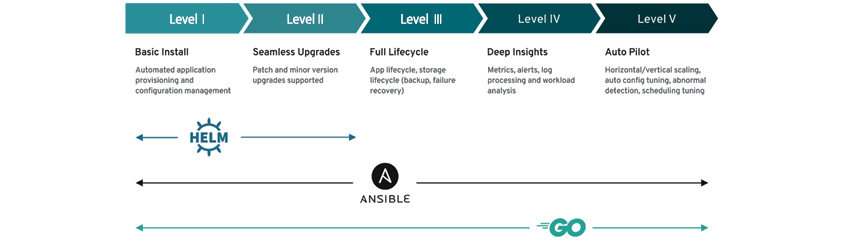
- basic install / seamless / full lifecycle / deep insights / auto pilot
- automated application provisioning and configuration / patch and minor version upgrades supported / app lifecycle, storage lifecycle(backup, failure recovery) / metrics alerts, log processing and workload analysis / horizontal·vertial scalling,auto config turning, abnormal detection, schedulling tuning
On the other hand, CSP native is easy to use for organizations with relatively weak OSS capabilities. It allows organizations to focus on the application itself without concern about how to design and run architecture that ensures agility, portability, failover, and auto-scalability. If you use a Java app, you can just create a .jar file and deploy it to a PaaS application. Examples are the Azure App Service, Spring Cloud, and Cloud Foundry.
The CSP native helps make applications into cloud-native applications, which gives an edge in time-saving and resource utilization. Of course, if your organization has basic container capabilities, managed container native can be an option. This approach, also called Container as a Service (CaaS), is known as a more practical cloud-native adoption method in that it can delegate most Kubernetes management to the CSP native while leaving management for resources to be used directly by the organization. The well-known cases are AKS of Azure, EKS of AWS, and GKE of GCP. Using managed Kubernetes clusters supported by CSP allows you to avoid vendor lock-in and benefit from cloud-native.
Whether it is container native or CSP native, the application itself needs modernization to run a cloud-native application. In summary, the term referring to cloud native as an application architecture, cloud-native application architecture is a modernized application. Practically speaking, it means applications designed with 12-factor app rules (https://12factor.net/) or Gartner's LIFESPAR principles (Table 1). This will be explained in detail in the next article.
| 12 Factor App | LIFESAR |
|---|---|
|
· Codebase · Explicitly declared dependencies · Treat back-end services as resources · Separated build and run stages · Stateless processes · Port binding · Concurrency · Graceful disposability · Dev/prod parity · Treating logs as streams · Admin processes |
· Checking latency · All metrics are measured · Checking failure · Event-driven asynchronous · Security · Concurrency (parallel) · Automation · Monitoring resource consumption |
If the legacy application should prioritize agility based on customer value, it must consider refactoring with the 12-factor app. It will be ideal for redesigning with a microservice architecture, but it is available to apply most of the 12-factor apps to the existing monolithic application. Mini-service architecture may be chosen as a realistic alternative for such requirement.
Of course, the developing application should reflect the above factors when planning the architecture. Moving toward cloud native requires applications to be basically modernized like above. If an application is not prepared, then no cloud native will reach the desired level (for example, the delivery lead time, operational stability index) regardless of what method it uses.
Cloud native is hard to achieve through a big-bang approach, such as conducting next-generation projects. You should approach it in a journey of practicing one at a time. It is important to define the goal and vision first, then realize each step. Below is an example of the order and tools for the cloud-native journey the author experienced.

- datadog,prometheus,grafana,pagerduty : continuous monitoring
- puffet,terraform : infra as code
- chef : immutable infrastructure
- jenkins blueocean, spinnaker, travis CI : blue green deployment/canary
- grizzly,akka,operators : microservice
- helm chart : containerzation
- kops, eks,iks : orchestration
2. Development and maintenance - Acceleration of agile development practices The hardest and still important...
It is literally an era of developers. Now, it is not surprising the developer's capability determines dozens of productivity differences. Developers are the most critical resource in all areas of cloud native, Agile/DevOps, and digital transformation. Developers in the existing SI industry were considered just coders. However, today's developers are 100% different highly competent professionals. In the past, they only coded with the artifacts of the analysis/design. Now, they directly participate in most software development life cycles from analysis, functional design, non-functional design (architecture), development, testing, and deployment to operation. Direct participation means having coding or implementation capabilities rather than attending a meeting or writing reports. Some tech companies, including Amazon, use the word Software Development Engineer (SDE) to emphasize the meaning of software engineering focused on development/implementation. In a narrow sense, developers mean SDE only, but in a broader sense, the meaning includes software development engineers in testing (SDET) and DevOps engineers. SDETs write test engineering in code, and DevOps engineers write and maintain infrastructure in code.
Developers should create functions prioritizing customer value with product managers by attending design thinking or user story workshops and discovering clues for designing functions to realize such architectures for non-functional requirements. Tools and the artifacts from them are not important, but functions and architectures should be highly competent, like those operating in the field. Developers should write both unit test code with quality coverage and integration test code. For test-driven development (TDD) practices, developers should emphasize creating testable function code and writing test code rather than the sequence of creating test code first and developing functions later. Test code are not the only thing that test engineers can create. As shown below (Figure 6), developers write unit and integration test code, and test engineers focus on the system and acceptance tests.
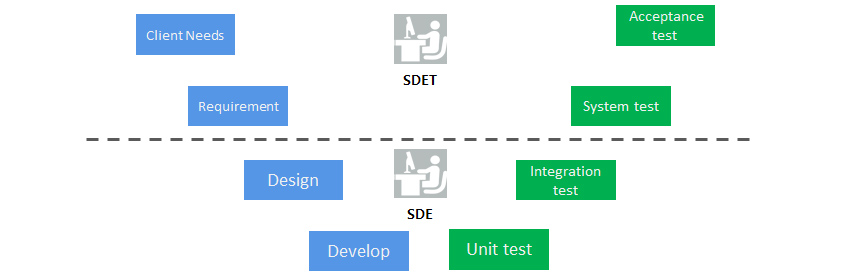
- client needs/acceptance test
- requirement/system test
- design/integration test
- develop/unit test
Test code written by developers is important in the modern development culture. The architectures should not be fixed to one-time, non-functional requirements, but begin as an architecture having an early stage, minimum requirements only, and keep improving and complementing, as the MVP implementation method would. Test code verifies these changes in architecture. Therefore, developers should retain test code to be confident in constantly attempting to improve and develop. If they have no test code, they wouldn't even try to change simple package structure out of anxiety and side effects on operational stability. This phenomenon is more visible in systems in full-fledged operation. Developers should write both the unit test and integration test code, but the unit test code should come first. Unit test code should be developed and maintained from the early stage, regardless of the increase in man-months. The first implementation of unit test code may take more man-months than writing code for implementing functions. In my experience, developers with zero experience in test code spend as much time writing test code as is the equivalent to implementing the feature code. However, once they get familiar with and accustomed to the task, man-months for test code reduce to 20% less than writing programming code. If test code writing becomes part of development, then developers can go one step closer to test-driven development (TDD), focusing on the minimal implementation of code to pass the test code only and keep refactoring). TDD is essential among Agile engineering practices.
Some organizations outsource writing test code. However, if they don’t use the code as artifacts of test-driven development, they will soon not use that code. Test code should be developed and maintained as artifacts of test-driven development. Test engineers should conduct performance, resiliency, security, and system-to-system tests based on cooperation with developers. The acceptance of testing is also the responsibility of the test engineers. The difference between test engineers and testers is whether they write test code. Test engineers write code for functional testing, such as API, UI, as well as system tests. The testing alone should be performed by CI/CD pipelines while collecting and measuring test results.
Developers should fully consider cloud-native application architecture. Cloud native has a very simple meaning of “implementation supported by the full benefits from clouds,” but the techniques for implementation are not easy to learn. Developers should have an understanding and great capabilities to implement container, CI/CD, microservice architecture, and application modernization. In other words, the applications to be developed are designed with, in particular, microservice or mini-service architecture at least, have their own boundary, and implement persistence as RDB or NoSQL, depending on the nature of the business. Communication between microservices is implemented by REST APIs and is built to be stateless to ensure proper caching and horizontal scaling. So, developers should design large-scale distributed architectures with event-driven technologies or command query responsibility segregation (CQRS) technologies and configure auto scheduling through container orchestration. Further, they should use a variety of open-source software properly to increase reliability and productivity while maintaining reviews on vulnerabilities of open-source software or open-source licenses.
Implemented functions will be deployed through various inspection automations and deployment automations with CI/CD and, once deployed, developers should manage monitoring and failure responses. To handle such a wide range of tasks, they had to choose “extreme automation.” Previous SI development/maintenance was done by each manager of software architects, infrastructure architects, data architects, testers, application managers, system operators, and database managers. So, I hear the question even still, “Is it possible to work as you said?” That's why the importance of automation should be emphasized for further DevOps acceleration. For more details about automation, it will be covered in the next chapter.
All developers (SDE, SDET, DevOps engineers) use configuration management tools to manage code and review code after writing all branches (logically separated space reflecting unit requirements). The code quality and productivity between developers may be 100 times different. As functional programming prevails, development productivity and maintainability gaps are much larger than those of traditional programming. Code reviews becomes more important when applied with advanced techniques like functional programming. Developers learn how to abstract dozens of lines of code into a few lines, improve code quality, and get inspired for growth and knowledge. Such a development culture is directly reflected in the productivity and quality of the applications, delivering improvement in a virtuous cycle.
Therefore, code review should be included in the development lifecycle as an essential activity. In the mutual code review, developers should find code smells (codes that are not errors but deteriorate maintainability and productivity) that cannot be found in static checks but can increase technical debt through the peer review to continuously decrease technical debt. Through the code review of each one’s exclusive coding techniques, tips, algorithms, etc., developers can improve their development capabilities and practice shared culture. Besides trunk-based code, code merged from feature branches to main branches should undergo code reviews and CI.
3. Infrastructure automation - How far it goes? Fully immutable infrastructure
Let's begin with the most basic, CI. CI checks whether developer-written code is well incorporated without problems. Then, the unit/integration test code is automatically performed to deliver reports on the coverage, success/failure, changes in testing results, etc. CI conducts basic static analysis for code vulnerabilities or code styles, including security checks, open-source license/vulnerability checks, etc. Usually, the end of CI is the packaging. It can deploy application packages to a library repository or a container registry by container packaging. Because it manages packaged artifacts in centralized methods and easily uses the CD pipeline.
Below is an example of a simple CI/CD pipeline where the stages of the pipeline (sets of tasks) can be configured depending on each project.
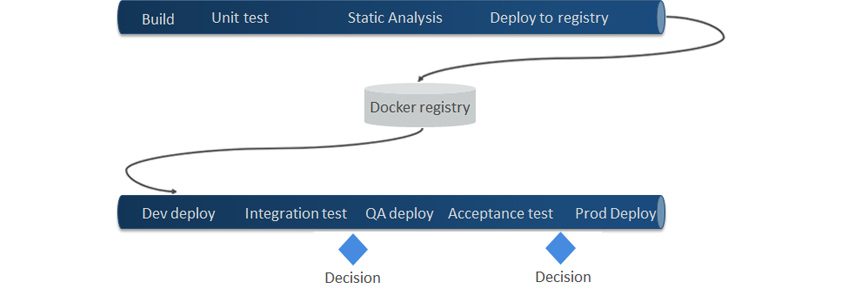
- build/unit test/static analysis/deploy to registry ->
- docker registry ->
- dev deploy/integration test/(decision)/QA deploy/acceptance test/(decision)/prod deploy
In particular, the pipeline below shows an example of configuring and triggering a Git tag. You can set the tag as a version and configure the pipeline settings to have the release candidate version deployed to the test environment and the release version to the production environment.
The immutable infrastructure paradigm is one of the difficult things about CI/CD automation. A somewhat odd definition of “once deployed infrastructure is immutable” expresses the nature of Infra as Code (IaC) well. The definition contains the obsessive nature of the immutable infrastructure that codified the infrastructure, and the actual infrastructure must match 100% and modify existing code to deploy changes. Fully managing infrastructure with code means easy history management, rollback, and configuring reproducible infrastructure anywhere. Different environments between production, test, and development environment often cause application failures. For example, an application works well in the development environment and then fails in the production. Therefore, we need to introduce IaC to prevent failure from occurring due to errors in infrastructure configuration and find the problems in configuring reproducible infrastructure. IaC is also used as an automation tool for quickly provisioning infrastructure in business continuity and disaster recovery (BCDR).
IaC's Immutable Infrastructure paradigm fits well if you configure the application host environment (VMs or containers where the application will be launched) than provisioning cloud resources. The reason behind this is the waste of unnecessary man-months to recover data of persistence when removing and regenerating existing resources whenever the PaaS cloud resources change. Therefore, the common practice is applying immutable infrastructure centered around containers in stateless applications. When hosting applications in VMs, all configurations of VMs should be codified, declared, and created as images using tools like Chef or Puffet. To deploy a new version of the application package (jar or war for JVM), the existing VM should be removed and replaced by new regenerated VMs by code. That is, new VMs of images created by code replace existing VMs. (This is called a rollout deployment.) The blue-green deployment is to place existing VMs and new VMs simultaneously and change the frontend routing after validation. Another option is canary deployment to deploy one to two packages first for deployment stability in detailed verification. Images of VMs written in code are sometimes used in auto-scaling extensions. Some organizations that strictly follow the immutable infrastructure philosophy, track configuration changes through the cron job and force overrides to prevent manual changes in VMs. So they show how much they are obsessed with aligning code and infrastructure.
If developers use container orchestration tools like Kubernetes to run applications, they can manage immutable and declarative infrastructures through Kubernetes Manifest or Helm Chart with more ease.
IaC is configured in the CD pipeline, but code that provision cloud resources should be configured separately to the application CD pipeline for better management efficiency. For example, a change in applications with containers doesn’t mean Kubernetes cluster configuration or PaaS DB will change accordingly.
For configuration management of infrastructure code in Git, developers should perform development practices, including branch strategies and code reviews, the same as handling programming code. Once infrastructure code is committed, developers can implement a GitOps environment using Git functions only to apply infrastructure or utilize dedicated GitOps tools, such as ArgoCD or FluxCD.
The picture below shows an example of the application's code, test, and IaC's repository structure. Possible management methods are central management in the applications, separate testing and infrastructure management, single repository management for small-scale applications and MSA environments, and separate repository management for separated DevOps teams. You can utilize an appropriate repository strategy according to each structure and the nature of the applications.
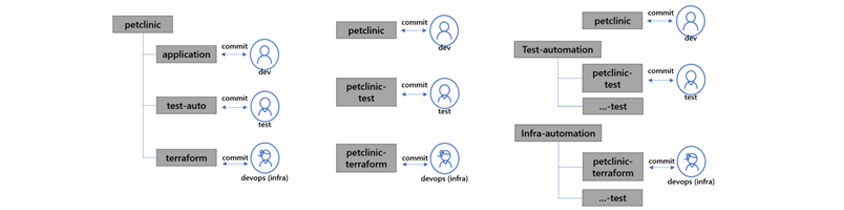
- petclinic ->
- application <-> (commit) dev
- test-auto <-> (commit) test
- terraform <-> (commit) devops(infra)
- petclinic <-> (commit) dev
- petclinic-test <-> (commit) test
- petclinic-terraform <-> devops(infra)
- petclinic <-> (commit) dev
- test-automation ->
- petclinic-test / ...-test <-> (commit) test
- infra-automation ->
- petclinic-terraform / ...-test <-> devops(infra)
4. Scale-out - Do you have enough operational capacity to stand scale-out?
In the past, development and operational units were separated. Once an application is developed, it is transferred to and conservatively run by an operational unit with minimum changes for reliability.
Even though DevOps is to break the barrier between development and operation, the clearest way to do so is to let the development unit run and the operational unit develop. In other words, single organization handles development and operation. It is not easy for a development unit to operate. However, leaving the development unit to do the development work and the operational unit to do the operation differs from DevOps' continuous improvement cycle principle. Development teams at tech companies like Netflix and Microsoft declare a software development philosophy “You build it, you run it.” Development is the starting point to achieving value realization of DevOps through extreme automation to streamlined operations. No operational experience means having no idea how to come up with ways to improve operational efficiency. Regarding developer capabilities, developers without operational experience would lack non-functional design and architecture capabilities. Operational experience provides developers with which part should be automated, how to optimize architectures, and how to manage and monitor large-scale traffic to create programming code with operational efficiency. This is also the case for applications, tests and infrastructure code.
If the development team develops a new service, there is no need for the entire development team members to go to the operation team. Still, at least the operation team should consist of the development team members. The same goes for developers, test engineers, and DevOps engineers, and you should be aware that the operational capacity is necessary for improvement in development.
The important operation task would be system monitoring and failure responses, achieved in an autonomous failover monitoring the environment through high-level automation. Here is an easy-to-understand example. Auto-scaling out configures to increase the CPU or memory usage when the load is high and to horizontal scale out accordingly. It can automate adjusting system resources upon increased user requests or external events (traffic increase due to weather changes and at a certain time). Auto-scaling may take at least a few minutes or even a dozen minutes because of image provisioning if an application-hosting environment is a VM. This time can be reduced in a container environment to a mere few seconds. So, the container environment is popular.
There are thousands of automation cases for operations. When the difference between the number of inbound and outbound messages in the message queue exceeds a threshold, it triggers the restarting of message clients and self-recovery, and when multiple evictions occur due to lack of memory in the Redis cache environment, it triggers the erasure of the least used data first from among the caches that do not expire. (For your information, the monitoring slack message I received the most when I worked at the Global Development team was “Recovered.” Over 90% of the system error alerts were self-recovered.)
The existing monitoring was a risk alert or notification for a particular situation. Today's monitoring can configure a self-recovering environment using automation tools and an intelligent monitoring environment. That said, we can slash the consumption of operational resources. This method is also the key to manage what thousands or tens of thousands of infrastructure environments by only a few employees in tech companies, such as Meta and IBM. You should know that advanced companies introduce automation more than you could imagine.
5. Organization - Are we really in the same boat?
Although the organization is technically not an engineering aspect, it is surely the key to successful DevOps implementation we should consider. An Agile team, also called Scrum or Squad, consists of developers (SDE), test engineers (SDET), DevOps engineers, and product managers. They often belong to Development, DevOps, and PM teams and are organized in the matrix organization form. This is done because operating an original department system is good for sharing strategies for each role, job training, propagating cases, and maintaining a consistent evaluation system. Most companies adopt similar organizational structures regardless of their Agile maturity. However, for a well-functioning squad team on Agile and DevOps philosophies, they should set shared goals and evaluation systems in the team regardless of the existence of the original department.

- squad #1 / squad #2 / squad #3
- SDE,SDET,DevOps,Product Owner(or BA) / SDE,SDET,DevOps,Product Owner(or BA) / DevOps,Product Owner(or BA),UX
In the example above, each squad member may belong to its original development team or be dispatched from another shared professional organization. So, squad teams are organized in a matrix based on their functions. UX means the member is dispatched from the UX group, DevOps engineers from the Enterprise Infrastructure Engineering team, and test engineers from the Test Shared team. This structure may be a natural choice to maintain resource utilization and high expertise. Even if the team members are from various units, their priorities must be the same. And the goal is defined as the success of the application developed/operated by the squad team and the realization of customer value and business performance. Test engineers' number one Key Performance Indicator (KPIs) or Objectives & Key Results (OKRs) should be perfectly aligned with the squad team's test engineering indicators. The original Test Shared Team's performance goals should always be treated as subordinate or less important. To achieve the squad team's goals, squad team members should be motivated as much as possible for the best functioning of the team. For maximized teamwork, the developers, test engineers, DevOps engineers, and product managers should dedicate themselves to the squad team. The entire team should have a shared vision, goals, and performance indicators for the only goal, “product success,” regardless of their roles. For each role's evaluation, the squad team's evaluation should come first. Only then can the team members will achieve success. In other words, they will share strategies and visions and try to main continuous improvement loops to achieve their goal of surpassing a certain level of the quantitative and qualitative indicators, such as the delivery lead time, quality, high availability, the number of users, the customer feedback score, revenue, etc., for applications they are developing and operating.
We've learned how to successfully introduce and continue to operate DevOps from an engineering perspective. Further considerations are needed for DevOps besides what we've explained in this article. For example, we should take a look at ways to define and refine customer value, establish and measure indicators of development/operation, and evaluation methods. Among the Agile and DevOps practices, this article addressed practices that are not usually applied in the field, so you should consider all practices to decide which one to apply further, including the SRE related practices.
We hope this article will be a little help for many organizations to achieve more with DevOps.
References
[1] “Microsoft official DevOps blog”, https://devblogs.microsoft.com/devops/
[2] “A CTO’s Guide to Cloud-Native”, Gartner, 2022
[3] “Top Strategic Technology Trends for 2022: Cloud-Native Platforms”, Gartner, 2022
[4] “Cloud-Native Transformation”, O'Reilly (Acorn), 2022
[5] “Digital Transformation Field Manual”, Miraebook, 2021
[6] “IBM Garage”, https://www.ibm.com/kr-ko/garage/
▶ The content is protected by the copyright law and the copyright belongs to the author.
▶ The content is prohibited to copy or quote without the author's permission.

Have hands-on experience in various departments, including Solution Development Center, SI, ITO, and DevOps Lab. Since then, served as a lead software engineer in the IBM Watson (Weather) Global Development team to develop and run an extremely large backend listed in the top 10 traffic volume with a cloud-native architecture. Taught cloud native and DevOps in various organizations, including the IBM Developer Conference, KT, Kookmin Bank Group, Hana Bank, Korean Institute of Information Scientists and Engineers, ISAKA Korea, and Kyung Hee University. Currently serves as a cloud-native Computing Architect for innovative applications and modernized infrastructure at Microsoft.
- Sách trắng phân tích công nghệ ChatGPT - Phần 1: Chat GPT là gì
- Ưu điểm và điểm cần cân nhắc khi sử dụng đa nền tảng đám mây
- Hiện đại hóa kỹ thuật số, sáng kiến chiến lược cho doanh nghiệp tương lai bền vững
- Các vấn đề và giải pháp thực tế trong bảo mật đám mây
- Nền tảng đám mây có thực sự cần thiết không? Mối lo ngại và sự thật
- Digital Twin (Bản sao kỹ thuật số) cho đổi mới sản xuất