
- 감사단 질문
- 담당자 섭외
- 정보검색
- 검색내용 정리
- 실사 대응
loading...
- 해당 아티클은 2024년 4월, 삼성SDS가 대외 고객을 대상으로 진행한 「Brity Automation Summit 2024」 컨퍼런스 중, 삼성바이오로직스 조성일 상무의 ‘생성형 AI 기반 업무 자동화 사례’ 세션 내용을 기반으로 작성되었습니다. -
2022년 11월, 'GPT-3.5' 모델이 출시된 후, 글로벌 빅테크 기업의 'Gemini 1.0 Pro', 'GPT-4 Turbo', 'Claude 2.1', 'Gemini 1.5 Pro'를 포함해 국내 기업인 업스테이지의 '솔라(Solar)' 등 다양한 LLM(Large Language Model)이 출시되고 있습니다. GPT-3.5가 세상에 처음 등장했을 때만 해도 할루시네이션(Hallucination)으로 인해 기업 업무에 적용하기에는 시간이 필요하다고 생각했습니다. 그러나, GPT-4.0을 사용하면서 이러한 생각이 조금씩 바뀌었습니다. 현재, 생성형 AI는 3개월만 지나도 빠르게 한 발 더 성장해 있어, 생성형 AI가 가져올 변화와 혁신은 두려울 정도입니다. IT 기술이 주도하고 있는 세상에서 바이오 제약회사인 삼성바이오로직스 역시 IT 및 생성형 AI 기반의 혁신 없이는 뒤처질 수 있다는 절실함을 느끼고 있었으나, 실제로 생성형 AI 도입에 대한 의사결정은 굉장히 어려웠습니다.
지난 수십 년간의 IT 경험을 되돌아보았을 때, 「2004년 SNS 혁명(페이스북)부터 클라우드(AWS), 스마트폰(App 생태계), 자율주행, 원격근무, 생성형 AI」까지 변화하고 있는 기술을 빨리 경험하고 흐름에 맡기는 것이 중요합니다. 이러한 기술 역사의 흐름은 AI와 밀접하게 연관되어 있습니다, 스마트폰의 App 생태계를 기반으로 GPT를 위한 앱스토어를 떠올렸는데 OpenAI의 'GPT Store(GPTs)'가 서비스되고, 마이크로소프트, 구글, 아마존 등 빅테크 기업들은 자사가 보유한 데이터, 플랫폼 및 클라우드를 기반으로 AI를 빠르게 접목하고 있는 등 생성형 AI는 상상을 초월할 정도로 확산되고 있습니다. 새로운 기술에 대한 겸손한 마음으로, AI가 얼마나 중요한지 느끼는 것만이 아니라 생성형 AI 기술을 빨리 경험하고 대응하는 것이 필요합니다. 그러나, 제한적인 리소스를 가지고 혁신을 진행해야 하는 비IT 기업에게는 결코 쉬운 일은 아닙니다. 여기서 중요한 점은 'AI 문화'를 통해 기업 임직원 모두가 참여해 기술을 캐치업하고 변화에 동참하는 것입니다. 둘째는 ‘IT 전문기업과의 기술 협력체’를 통해 혁신을 진행하는 것입니다. 기업은 도메인 관점에서 데이터 준비 및 생성형 AI를 이해하고, 삼성SDS와 같은 IT 전문기업은 생성형 AI 적용을 위한 플랫폼 준비와 파인튜닝, RAG*, 벡터화 등 실제 생성형 AI 기술 구현을 리딩해야 합니다.
* RAG(Retrieval Augmented Generation): 검색 증강 생성
삼성바이오로직스는?
삼성바이오로직스(SBL)는 2011년에 설립된 기업으로 최근 연평균 20~30% 성장하여 국내 시가총액 4위 기업이 되었습니다. 화이자(Pfizer), BMS(Bristol-Myers Squibb) 등 메이저 제약회사를 포함한 110개 이상의 고객사와 60만 리터 수준의 세계 최대 생산 능력을 보유하고 있으며, 265건 이상의 FDA*, EMA* 등 글로벌 규제기관의 승인을 받았습니다. 삼성바이오로직스는 바이오 의약품의 초기 개발부터 임상 및 상업 생산까지의 End-to-End 서비스를 제공합니다. 단순 화학약품이 아니라, '세포를 배양해서 사용할 수 있도록 정제한 후 바이알 형태로 무균 충전하고, 품질 분석을 통해 안전성을 확보, 최종적으로 규제기관으로부터 승인을 받는 프로세스'를 진행하며, 이러한 프로세스는 바이오 제약산업 측면에서는 매우 중요한 부분입니다.
* FDA(Food and Drug Administration): 미국 식품의약품청
* EMA(European Medicines Agency): 유럽 의약품청
 바이오 의약품 개발/생산 프로세스 (출처: 컨퍼런스 자료)
바이오 의약품 개발/생산 프로세스 (출처: 컨퍼런스 자료)
-
- 원료의약품 생산*
- 배양
- 정제
-
- 완제의약품 생산*
- 무균 충전
-
- 분석
- 품질 분석
- 안정성 연구
-
- 규제기관 승인
- 임상 및 판매
- 승인 지원
삼성바이오로직스, Pain-Point
바이오 제약산업은 수많은 SOP*를 보유하고 있고, 반드시 SOP에 규정된 내용과 절차를 준수해야 합니다. IT나 일반 제조업과는 다르게, 결과의 품질만 중요한 것이 아니라 좋은 품질이 나오더라도 절차를 위반할 경우 해당 의약품은 사용할 수 없고, 품질의 결과를 포함한 모든 절차 위반은 관리되어야 합니다. 그래서, FDA, EMA 등 글로벌 규제기관과 여러 메이저 고객사는 주기적인 Inspection/Audit을 진행하여 의약품 제조업체가 SOP의 규제 요구사항을 준수하는지와 제조된 의약품의 안정성을 점검합니다. 문제가 발생할 경우, 규제기관에서 ‘Warning Letter’를 대외적으로 발표하고, 생산이 중단되거나 제품 출시가 지연될 수도 있습니다. 특히, "Driven. For Life."라는 모토를 가지고 사람의 생명을 다루는 기업인 만큼 고객과의 신뢰가 손상될 경우, 장기적 비즈니스 관계에 악영향을 미칠 수 있습니다.
삼성바이오로직스는 업무를 수행하거나 규제기관/고객사 Inspection 진행 시, PDF 등의 내부 문서나 광범위한 데이터베이스(DB) 안에서 실무자들이 필요한 SOP*, Deviation*, CAPA*, CC* 등의 정보를 찾아내고 출처를 확인하는 데 많은 시간을 소요하고 있었습니다. '생성형 AI 활용한 Inspection & Audit 지원'으로, 빠르고 정확한 답변과 임직원 업무 생산성 향상을 통해 고객 요구에 대한 빠른 대응이 필요했습니다.
* SOP(Standard Operating Procedure): 제약 공정에 대한 표준 운영 절차를 다룬 문서
* Deviation: SOP에서 허용되지 않는 편차
* CAPA(Corrective and Preventive Actions): 예방조치 활동
* CC(Change Control): 변경 관리
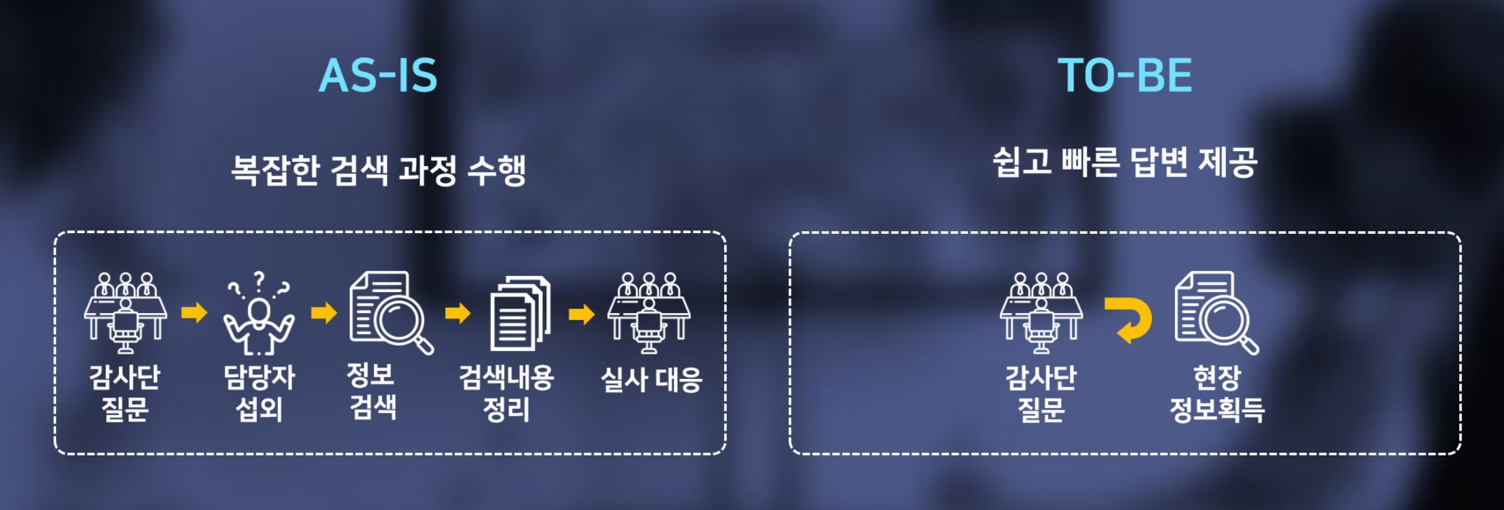 규제기관/고객사 Inspection 대응에 대한 Pain-Point (출처: 컨퍼런스 자료)
규제기관/고객사 Inspection 대응에 대한 Pain-Point (출처: 컨퍼런스 자료)
- 감사단 질문
- 현장 정보획득
삼성바이오로직스, 생성형 AI PoC
삼성바이오로직스는 규제기관 및 고객사의 감사단 질의에 대한 현장 대응력을 강화하기 위해, 삼성SDS와 함께 생성형 AI를 활용한 PoC 과제를 수행했습니다.
PoC는 삼성SDS의 업무 자동화 솔루션인 'Brity Automation*'을 통해 각 과제별 프로세스를 설계하고, 사용자 커뮤니케이션 채널을 위한 'Brity Web-Chat*', 삼성의 생성형 AI 모델(SR-LLM), 그리고 RAG 개발로 기능을 구현했습니다. ChatGPT와 같이 질문을 하면 일반적으로 대답해 주는 일반 질의(General Question)와 Brity Automation을 활용해 사전 정의된 용어집을 참고하여 도메인에 특화된 번역 기능을 기본적으로 제공합니다.
생성형 AI PoC 과제의 핵심 프로세스를 간단히 설명하면, 사용자가 Web-Chat을 통해 질의를 하면 Brity Automation으로 전달되고, Brity Automation은 삼성바이오로직스의 DB 데이터와 PDF 등을 임베딩/인덱싱한 Vector DB에서 답변을 검색합니다. 검색된 답변 후보군과 출처를 프롬프트에 추가해서 전송하면 LLM이 최종 답변을 생성하고, Brity Automation을 통해 Web-Chat으로 사용자에게 답변을 전달하게 됩니다.
* Brity Automation: 기업 업무 대상 Hyper-automation 구현에 특화된 업무 자동화 솔루션으로 UI 기반 자동화 설계 및 API 기반 워크플로우를 실행할 수 있으며, LLM을 활용한 지식검색 및 Chat 서비스를 지원함
* Web-Chat: 사용자가 생성형 AI와 소통할 수 있는 채널 역할을 수행. 삼성SDS가 다수의 챗봇 딜리버리를 통해 확보한 Asset으로, 삼성그룹 및 사내 솔루션/시스템 챗봇 구축 시 활용함 (2022년 12월 웹어워드코리아 최고 대상 수상)
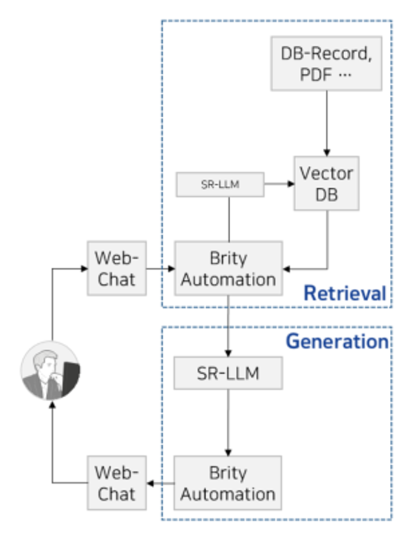 PoC 핵심 프로세스 도식 (출처: 삼성SDS)
PoC 핵심 프로세스 도식 (출처: 삼성SDS)
User > Web-Chat > Brity Automation에서 SR-LLM이동되고 > Vector DB전에(DB-Record, PDF...)애서 Vector DB로 내려옴 > 다시 Brity Automation으로 돌아오고 > SR-LLM > Brity Automation > Web-Chat > User
생성형 AI 주요 기술은 ‘RAG(Retrieval Augmented Generation)’, ‘Text-to-SQL’이며, 해당 기술을 적용한 2개 과제에 대해 자세히 설명하겠습니다.
1) GenAI SOP Q&A (RAG 적용, 복잡한 표를 포함한 SOP에 대한 질의응답)
LLM은 학습한 데이터의 cut off가 있기 때문에 최신 데이터를 반영하지 못합니다. 그러나, 사용자 질문에 대해 답을 포함하고 있는 문서의 문장을 찾아서 프롬프트에 추가한 후 LLM에 질의하면 LLM이 해당 문장을 참고해서 답변을 생성하는데, 이 기술이 바로 ‘RAG’입니다.
삼성바이오로직스는 복잡한 표와 이미지가 포함된 SOP 문서에서 원하는 답변을 찾기 위해 RAG 개발을 진행했습니다. 기업 내부 데이터는 LLM에 학습되어 있지 않기 때문에, PDF 형태의 SOP 문서를 Vector DB에 임베딩해서 저장하는 'Build knowledge base' 단계를 먼저 진행했습니다. 문서의 데이터를 로드하고, 작은 단위로 나누는 전처리 과정은 많은 경험이 필요합니다. 문서의 표(테이블)가 페이지에 걸쳐 있거나, 표 안에 표가 있거나, 셀이 병합되어 있으면 문제가 될 수 있으며, 문서 내 객체들을 컨트롤하는 것은 쉽지 않습니다. 텍스트 중간에 표가 포함되면 노이즈로 작용하기 때문에 우선적으로 SOP에서 텍스트와 표를 분리하는 작업을 진행했습니다. '텍스트'는 chunk size를 기준으로 passage로 분리, '분리된 표'는 별도의 전처리를 수행한 후 passage로 구성하고, 각각의 passage에 메타 데이터(문서명, passage 번호, 페이지 번호 등)를 추가하여 관계형 DB와 Vector DB에 저장했습니다.
 GenAI SOP Q&A - Data Flow (출처: 컨퍼런스 자료)
GenAI SOP Q&A - Data Flow (출처: 컨퍼런스 자료)
Step 1 Build knowledge base
1 SOP Documents > 2 Embedding
3 Vector database > "No data retention" 2 Embedding
Step 2 Develop Q&A chatbot
1 Question > 2 Embedding
3 Vector database > 2 Embedding > 3 Vectors > 4 Vector database > 5 SOP Documents, 6 Question + prompt Parameters > 7 LLM > Response
- Legend
- IN-HOUSE
- LLM
- SBL Internal
다음으로 사용자의 질문에 대해 Vector DB에서 passage를 검색한 후, LLM을 통해 최종 답변을 생성하는 'Develop Q&A Chatbot’을 구현했습니다.
사용자가 챗봇을 통해 질의하면, - 사용한 삼성 LLM(SR-LLM)이 한국어보다 영어로 질문할 때 더 좋은 답변을 생성하기 때문에 - 영어로 번역하고, 삼성바이오로직스의 용어집을 검색하여 약어가 있는 경우 전체 용어로 질문을 변환하는 등 LLM이 잘 답변할 수 있는 형태로 질문을 수정합니다. 수정된 질문(Question)을 Vector로 변환하고, Vector DB에 저장된 passage와 유사도 검색을 통해 상위 20개를 후보로 선정합니다. 해당 검색은 MP-Net*, DPR* 2개 모델을 적용하여 유사도 기반으로 검색 후 교집합 passage를 선택하는데, 해당 검색 기술은 성능은 유지하면서 LLM 호출 횟수는 50% 줄일 수 있어 삼성SDS는 2024년 1월에 특허를 출원했습니다.
이후, 후보 passage를 활용해 LLM에 전송할 콘텐츠를 구성합니다. 검색된 passage는 질문과 유사할 수 있지만 실제 답변은 그 앞뒤에 있는 경우도 많이 있습니다. 따라서, LLM에 1회 전송할 수 있는 토큰 수의 Max 값인 8K를 최대한 활용하기 위해 여러 번의 테스트를 거쳐 앞뒤로 6개씩의 passage를 추가하고, 표로 구성된 passage 경우는 해당 표만 LLM에 전송합니다. 이 부분 역시, 2024년 1월에 특허를 출원했습니다. LLM이 답변을 잘 생성하도록 'LLM 역할', '목표', 주어진 passage에서만 답변하라는 등의 '제약사항'을 '사용자 질의'와 앞서 작성한 '후보 passage 콘텐츠'와 합쳐서 프롬프트를 작성합니다.
이러한 프롬프트 작성은 정답이 없기 때문에 많은 경험을 통해 최적화하는 작업이 필요합니다. 20개 후보 passage별 프롬프트를 순차적으로 LLM에 보내, 답변을 찾지 못한 항목을 제외하면서 목표한 답변 개수가 될 때까지 반복하여 최종 답변을 생성하고, 근거가 되는 해당 문서명과 페이지 번호를 함께 제공합니다.
* MP-Net(Masked and Permuted Pre-training for Language Understanding): 전통적으로 FAQ에서 답을 찾아서 알려 주는 방식으로, 사용자 질문에 대해 FAQ의 질문과 유사한 걸 찾아 해당 내용으로 답변하는 방식 적용
* DPR(Dense Passage Retriever): 저차원 연속 공간의 모든 구절을 색인화하여 런타임 시 사용자의 입력 질문과 관련된 상위 k 구절을 효율적으로 검색
2) GenAI Quality Record Q&A (Text-to-SQL 적용)
'Deviation'라는 결함에 대한 조치/예방 활동을 기록하는 품질 DB를 가지고 있습니다. PoC는 품질 DB의 3개 테이블을 대상으로 진행했고, 사용자 질문에 대해 LLM을 활용한 Text-to-SQL* 기술 - SQL 비전문가들이 별도의 교육 없이 관계형 데이터베이스에 접근하여 데이터를 추출할 수 있는 방법으로 관심을 받는 영역 - 을 적용, SQL로 변환 후 DB에서 조회한 결과를 테이블 형태로 제공했습니다. 또한, 해당 DB는 품질 활동에 대한 기록이기 때문에, ‘문제에 대한 상세 Description' 또는 '조치 담당자 의견' 등의 컬럼(필드)에 대한 질문의 경우에는 SQL로는 필요한 데이터를 찾아 답변할 수 없어 RAG 기술도 함께 적용했습니다.
* Text-To-SQL(T2S): 사용자가 입력한 자연어 텍스트를 SQL(Structured Query Language)로 자동 변환하는 기술
먼저, DB 데이터를 정제하고, 사용자가 텍스트로 내용을 입력하는 컬럼은 RAG 적용을 위해 Vector DB에 임베딩합니다. 사용자가 DB 데이터에 대해 질의하면 LLM을 통해 영문으로 번역하고, LLM이 DB의 구조를 이해하고 SQL을 잘 생성할 수 있도록 프롬프트를 작성합니다. 해당 프롬프트에는 내부 DB 테이블 구조를 LLM에게 알려주기 위해 테이블 생성 SQL을 입력하고, 실제 저장된 데이터의 샘플도 추가합니다. 또한, LLM에게 SQL 전문가 역할을 주고, 사용자 질의에 대한 SQL 생성이 가능할 경우 SQL을 생성하도록 작성합니다. Brity Automation의 UI 기반 워크플로우를 활용하여 생성된 SQL에 대한 Validation을 빠르게 개발하고, 최종적으로 검증된 SQL로 내부 품질 DB에 질의하여 데이터를 수집, 품질 활동의 결과가 여러 개일 경우 테이블 형태로 가공해 답변합니다. SQL 실행 결과가 없거나 사용자가 입력한 컬럼에 대한 질문일 경우에는, SOP Q&A와 동일한 과정(RAG)을 진행하여 Vector 유사도 검색 후 LLM에 전송하여 최종 답변을 생성합니다.
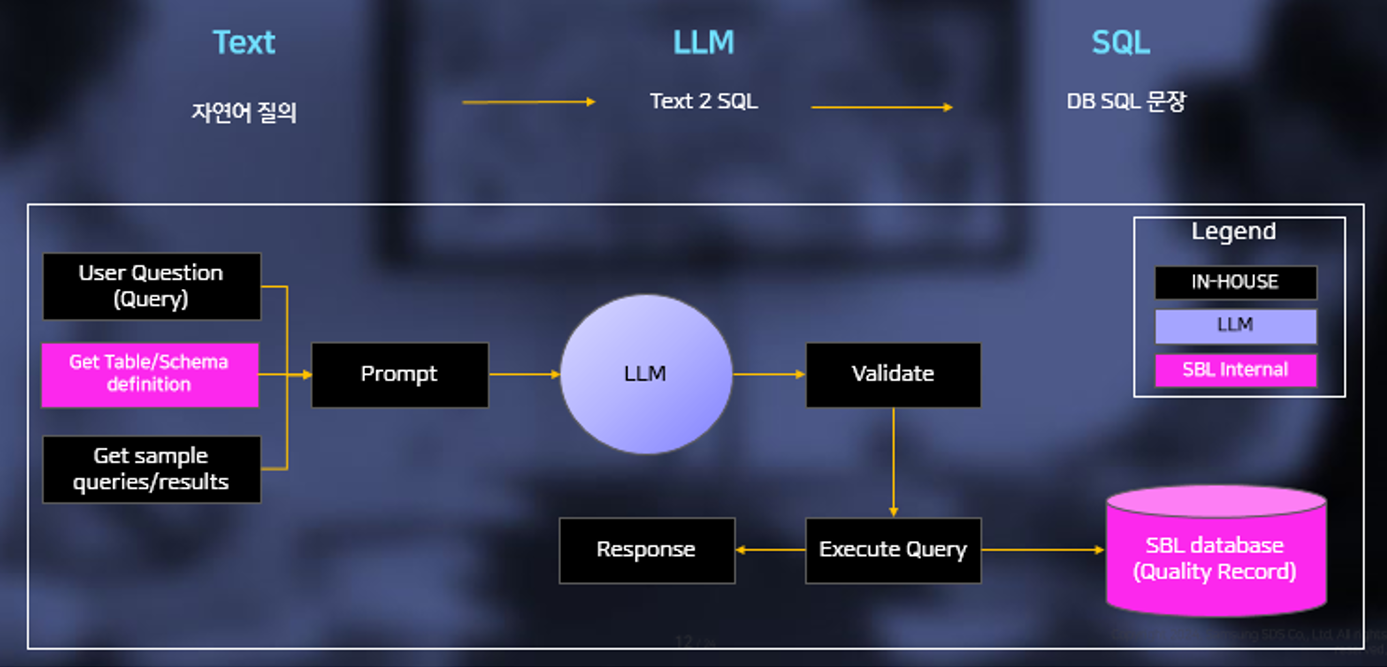 GenAI Quality Record Q&A - Data Flow (출처: 컨퍼런스 자료)
GenAI Quality Record Q&A - Data Flow (출처: 컨퍼런스 자료)
Text : 자연어 질의 > LLM : Text 2 SQL > SQL : DB SQL 문장
- Legend
- IN-HOUSE
- LLM
- SBL Internal
해당 PoC 과제들은 LLM 활용을 위해 가장 중요하다고 볼 수 있는 프롬프트 작성을 위한 구체적인 가이드를 구축해 적용했습니다. 또한, Brity Automation을 활용해 쿼리(Q&A), 요약(Summary) 등의 사용자의 의도에 대한 분류/분기, SOP 질의를 위한 Parameter 세팅, RAG 요청, 답변 유형에 따른 결과 포맷 적용 등의 연계 프로세스를 빠르게 구축하고, LLM, RAG 기술을 적용해 기존 프로세스와 인테그레이션(Integration)할 수 있었습니다.
2024년 1월, A100, 8장, Dedicated 환경에서 500명 대상으로 Pilot 오픈하고, 현재 하루 평균 1,500여 건의 LLM 요청을 처리하는 등 Inspection & Audit을 지원하고 있습니다. 향후, UI/UX 개선과 HR 등 사내 시스템과의 연계를 확대해 전사 오픈할 계획입니다.
생성형 AI 적용 Benefit
유튜브에서 보면 생성형 AI를 통해 모든 작업이 다 되는 것처럼 보이지만, 실제로 기업의 제한적 보안에 대응하면서 사내의 데이터를 정확하게 추출해서 딜리버리하고, 비전문가가 자연어로 DB에 질의해 필요한 정보를 활용할 수 있게 한다는 것은 쉬운 작업은 아니었습니다.
생성형 AI를 활용한 SOP 질의응답/요약 기능은 현재 일부 SOP를 대상으로 적용했으나, 전체 SOP는 훨씬 많고 SOP 당 짧게는 수십 장에서 수백 장으로 구성되어 SOP 문서 내에서 정보를 찾을 수 있다는 것은 매우 중요합니다. 실무 인력이 굉장히 많아지고 있는 상황에서, 신규 인력의 교육에 활용해 빠른 업무 투입이 가능하고, 정확한 절차를 숙지할 수 있어 공정 절차를 위반하는 횟수가 감소하면서 품질 향상을 기대할 수 있습니다. 또한, 중복된 표현/용어 등을 비교, 분석하여 절차를 효율화하고 표준화하고 있습니다. 공정 이슈, 변경, 조치 등을 기록한 품질 DB 데이터 활용을 통해서는 IT 비전문가도 쉽고 빠르게 DB 데이터에 접근할 수 있어 규제기관 실사 수행 중 품질 레코드 검색 소요 시간을 줄이고, 공정 이슈의 근본적인 원인 분석을 통해 업무 절차를 개선할 수 있습니다. 또한, 논리적이고 정확한 데이터를 제공해 고객 만족과 신뢰를 얻게 되었습니다.
Lessons Learned
프로젝트를 진행하면서 느끼는 점은 현업이 반드시 참여해야 한다는 것입니다. 현업이 데이터를 만들어 주지 않으면 어떤 프로젝트도 성공하기 어렵습니다. 대부분 생성형 AI 기술에만 집중하고 있는데, 생산성 증대로 내부 데이터가 많아지면 비표준화된 문서도 증가할 수 있습니다. 기업이 정확한 E2E 데이터를 연결하기 위해서는 먼저 데이터의 구조화 및 표준화가 필요하며, RAG나 프롬프트 작성도 표준화된 데이터 구조나 형식을 반영해야 합니다. 이러한 기업의 데이터는 분석해 가면서 지속적인 표준화 사이클을 구축해야 합니다.
또한, 신기술이 계속 나오고 급변하는 환경 속에서 다양한 LLM을 End-Point로 연결하고 사용자가 대화할 수 있는 솔루션/플랫폼을 보유한 생성형 AI 기술 기반의 파트너가 필요합니다. 파트너와의 지속적인 협의를 통해 요구 사항을 구체화하고, 기업에 필요한 Use Case가 구현 가능한지를 검증하는 과정이 필요하며, 이러한 과정에서 기업에 적합한 LLM, GPU 및 인프라를 산정하고, 기업 특성을 고려한 RAG 개발 및 Prompt 최적화로 정확도를 높일 수 있습니다. 혁신의 비전을 공유하고 프로젝트를 통해 얼마나 좋아지는가에 대해 함께 공감하는 것은 프로젝트의 성공 요소이며, 무엇보다도 CEO 등 경영진의 관심과 스폰서가 반드시 필요합니다.
맺음말
향후, 삼성바이오로직스는 표준화된 데이터를 생성하고 분석 가능하도록 정비하여, E2E 비즈니스 연계 및 파인튜닝 데이터로 활용하는 선순환 체계를 마련하고, 영업, 마케팅, HR 및 재무 등 다양한 업무 영역으로 생성형 AI 적용을 확대할 계획입니다.
일론 머스크(Elon Musk)는 "지속적인 변화와 개선을 통한 진보”를 제프 베이조스(Jeff Bezos)는 "변하지 않는 것에 집중하라"라고 말했습니다. 상반된 얘기를 하는데 같은 말로 이해됩니다. 변화와 혁신은 IT를 수행하는 입장에서는 항상 직면하는 과제이지만 빠르게 집중해 변화의 흐름에 함께 해야 하고, 앞서 말씀드린 '데이터 표준화’와 같은 변하지 않는 것에 집중하여 그 토대를 바탕으로 생성형 AI를 적용하는 기업은 성공적으로 내재화하고 좋은 사례를 만들 수 있을 것입니다.
▶ 이 글은 저작권법에 의하여 보호받는 저작물로 모든 저작권은 저작자에게 있습니다.
▶ 이 글은 사전 동의 없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
- #생성형 AI
- #GENERATIVE AI
- #초거대 AI
- #인공지능
- #AI
- #LLM
- #LARGE LANGUAGE MODEL
- #CHATGPT
- #챗GPT
- #삼성바이오로직스
- #고객 사례
- #생성형 AI 사례
- #RAG
- #RETRIEVAL AUGMENTED GENERATION
- #TEXT-TO-SQL
- #VECTOR DB
- #데이터 표준화
- #BRITY AUTOMATION
- #BRITY WEB-CHAT
![]()

홍은주
삼성SDS 전략마케팅팀
IT 동향 분석, 프로세스 혁신 및 경영전략 수립의 컨설팅 업무 경험을 기반으로, 삼성SDS 닷컴 내 Digital Transformation 및 솔루션 페이지 기획/운영 업무를 수행하였고 SDS 주요 사업영역별 동향/솔루션 분석을 통한 컨텐츠 기획 및 마케팅을 수행하고 있습니다.