

목차
백악관, 인공지능과 프라이버시의 갈등을 제어하다
올해 3월 미국 백악관 예산국(Office of Management and Budget)은 인공지능 활용에 대한 행정명령 'Advancing Governance, Innovation, and Risk Management for Agency Use of Artificial Intelligence'를 발표했습니다. 이 명령은 연방 정부 기관들이 미국 정부와 시민들의 권리를 위해 인공지능 기술을 어떻게 규제해야 하는지에 대한 가이드라인을 제시하고 있습니다.
행정명령의 일환으로 각 기관들은 최고 인공지능 책임자 즉 CAIO(Chief Artificial Intelligence Officer)를 임명해야 합니다. CAIO의 핵심 임무 중 하나는 사용자인 미국 국민의 프라이버시를 보호하는 것입니다. 인공지능 시스템을 구축하고 활용하는 과정에서 시민들의 개인 정보가 많이 모이고 활용되는 만큼 프라이버시 또한 철저히 보호되어야 한다는 의도입니다. 백악관은 연방 정부 차원에서 인공지능에 대한 지원과 함께 프라이버시 훼손의 위험을 예방하려는 정책을 본격 펼치기 시작했습니다.
CAIO(Chief Artificial Intelligence Officer)란?
연방 정부 기관에서 AI 기술의 책임감 있는 활용을 감독하고, 특히 시민들의 프라이버시 보호를 핵심 임무로 하는 최고 책임자입니다. AI 시스템 구축과 활용 과정에서 개인정보 보호를 철저히 관리합니다.
이러한 흐름에 맞추어 본 가이드는 transfer learning(전이 학습), face recognition(얼굴 인식) 등 다양한 머신러닝 환경에서의 프라이버시 유출 위협 문제를 기술적, 정책적 관점에서 살펴보도록 하겠습니다.
환경 1) Transfer Learning과 프라이버시의 충돌
Transfer Learning의 개념과 목적
Transfer Learning(전이 학습)란?
한 분야에서 우수하게 학습된 모델의 지식을 다른 분야로 전이하여 활용하는 머신러닝 기법입니다. 제한된 데이터와 컴퓨팅 자원으로도 높은 성능의 모델을 구축할 수 있게 해주는 핵심 기술입니다.
Transfer Learning은 머신러닝과 프라이버시 충돌 문제에서 흔히 언급되는 알고리즘 학습의 한 형태입니다. 모델의 성능은 높이면서도 데이터 활용의 효율성을 살리려는 의도를 담고 있습니다. Transfer Learning은 전이 학습이라는 이름에서 알 수 있듯 모델 성능을 다른 분야로 전이하는 것(knowledge sharing)에 가장 큰 목적이 있습니다. 어느 특정 분야에서 머신러닝 모델을 처음부터 우수하게 학습시키는 것은 많은 시간과 비용이 듭니다. 이런 문제를 해결하기 위해 풍부한 컴퓨팅 환경에서 우수하게 훈련된 모델을 다른 분야로 옮겨서 활용할 수 있다면 시간과 비용을 낮출 수 있겠다는 아이디어가 Transfer Learning으로 구현된 것입니다.
일반적으로 딥러닝 분석은 다량의 클래스 데이터를 요구하지만 모든 분야에서 충분한 양의 클래스 데이터를 확보하는 것은 불가능에 가깝습니다. 클래스를 정할 수 없는 경우, 아직 정해져 있지 않은 경우 등 현실적인 한계가 있기 때문입니다. 그래서 Transfer Learning은 한 분야에서 학습한 모델을 다른 분야에 적용해 데이터가 부족한 상황에서도 성능 좋은 모델을 만들 수 있게 해줍니다. 다음 개념도는 우수하게 훈련된 모델(teacher model) 중 일부 층을 떼어와 개별 모델(student model)에서 활용하는 모습을 보여주고 있습니다.
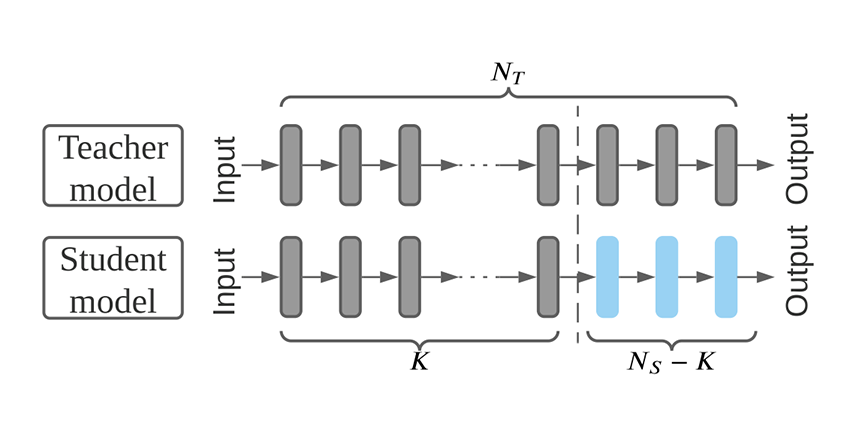 Transfer Learning 개념도. 출처: Ye et al., 2022
Transfer Learning 개념도. 출처: Ye et al., 2022
Transfer Learning 실제 적용 사례들
예를 들어, 이미지넷(ImageNet)과 같은 대규모 데이터셋으로 사전 훈련된 합성곱 신경망(Convolutional Neural Network) 모델은 시각적 특징을 풍부하게 학습하게 됩니다. 이러한 우수한 모델을 이미지 인식이 필요한 새로운 컴퓨터 비전 작업에 활용한다면 해당 분야에서 처음부터 모델을 구축하는 것보다 작은 규모의 데이터로도 우수한 성능을 얻을 수 있게 됩니다.
텍스트 데이터 기반의 자연어 처리 분야에서도 Transfer Learning은 유용하게 쓰이고 있습니다. 사전 학습된 언어모델(pre-trained language model)인 BERT나 GPT를 들 수 있습니다. 사전 학습 언어 모델들은 구글, OpenAI 등 빅테크 기업에서 대량의 텍스트 데이터로 사전에 학습해 일반적인 맥락에서의 언어 이해력을 우수하게 갖추게 됩니다. 그 뒤 활용 목적이나 분야에 따른 미세한 조정(fine-tuning)을 거쳐 텍스트 분류, Q&A, 번역, 문장 생성 등의 추가 작업을 하게 됩니다. 비슷한 원리로 음성 인식 등 다양한 분야에서 Transfer Learning은 폭넓게 활용되며 각 도메인만의 요구사항을 충족시키는 중요한 모델로 쓰입니다.
이처럼 Transfer Learning은 제한된 데이터와 컴퓨팅 문제를 극복하고 머신러닝 모델의 성능을 높이는 데 기여하고 있습니다. 특히 딥러닝의 발전과 함께 그 중요성이 더욱 커지고 있으며 적절한 사전학습 모델의 선정과 전이 기법의 활용은 중요한 숙제입니다.
Transfer Learning에서 발생하는 5가지 프라이버시 침해 유형
그러나 Transfer Learning의 단점 중 하나는 바로 프라이버시 침해 문제입니다. 그 주된 이유는 Transfer Learning에서 사전 학습된 모델이 원 데이터의 정보를 일부 포함하거나 공격에 취약한 구조를 갖기 때문입니다.
1. Model Inversion Attack(모델 역공학 공격)
첫째는 Model Inversion Attack, 즉 모델 역공학 공격입니다. 아래 그림에서 볼 수 있듯 프라이버시 침해 의도를 가진 공격자가 공격 목표가 되는 모델에 접근해 이 모델을 훈련시킨 원 데이터를 역으로 파악하는 것입니다. 다양한 입력 데이터를 모델에 투입한 뒤 그에 따른 출력 데이터를 분석하여 패턴을 파악합니다. 이를 통해 모델이 학습한 데이터의 특징을 역으로 추정하고, 원본 데이터와 유사한 샘플을 생성해냅니다. 원 데이터에는 프라이버시 정보가 포함되어 있으므로 공격자는 결국 프라이버시와 유사한 결과를 얻을 수 있게 됩니다.
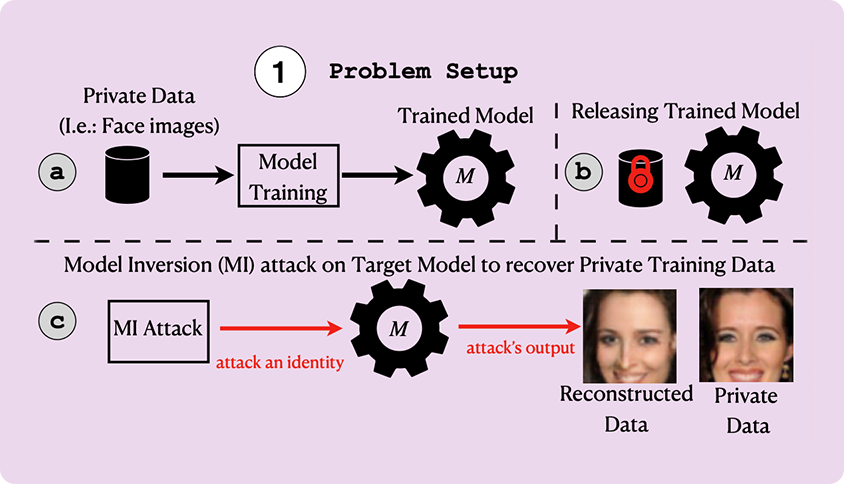 Model Inversion Attack 개념도. 출처: Nguyen et al., 2023
Model Inversion Attack 개념도. 출처: Nguyen et al., 2023
2. Membership Inference Attack(멤버십 추론 공격)
두 번째는 Membership Inference Attack(멤버십 추론 공격)입니다. Membership Inference Attack은 개인의 프라이버시 데이터가 모델 학습에 쓰였는지 여부 즉 멤버십 여부를 파악하는데 목적을 두고 있습니다.
아래 개념도에서 볼 수 있듯 공격자는 특정 데이터 샘플을 모델에 입력하고, 출력 결과의 확신도를 파악하게 됩니다. 만약 공격자가 모델에 입력한 샘플이 학습 데이터에 포함되었다면 높은 확신도를 보일 것입니다. 반대로 공격자가 모델에 입력한 샘플이 학습 데이터에 포함되지 않았다면 해당 샘플은 상대적으로 낮은 확신도를 보일 것입니다.
이러한 특성을 기반으로 공격자는 개인의 데이터가 모델 학습에 사용되었는지 여부를 추론할 수 있게 됩니다. 결국 특정 개인의 데이터가 어떤 목적으로 사용되었는지에 대한 정보를 노출시킴으로써 프라이버시를 침해하게 되며 이는 의학, 금융, 범죄 등의 분야에서 해당 개인에게 피해를 주게 됩니다.
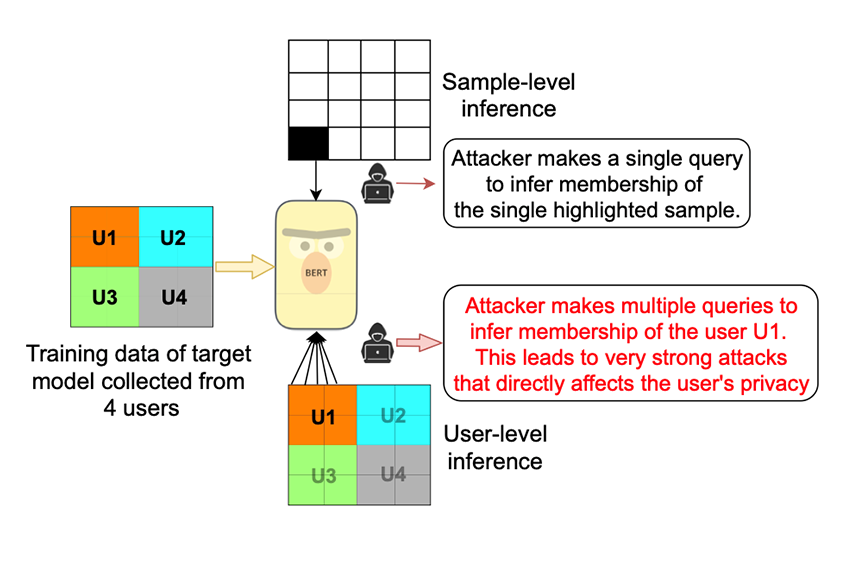 Membership Inference Attack 개념도. 출처: Shejwalkar et al., 2021
Membership Inference Attack 개념도. 출처: Shejwalkar et al., 2021
3. Attribute Inference Attack(속성 추론 공격)의 복합적 위험
세 번째는 Attribute Inference Attack (속성 추론 공격)입니다. Attribute Inference Attack은 모델의 출력값에 공격자가 공개 혹은 비공개적으로 얻을 수 있는 정보를 결합해 개인의 프라이버시를 보다 풍부하게 파악하는 공격 방법입니다. 이는 학습된 모델의 출력과 외부 정보를 결합함으로써 모델이 직접 예측하지 않은 프라이버시까지도 공격자가 추론할 수 있다는 특징이 있습니다.
예를 들어, 아래 그림에서 볼 수 있듯 각 유저들의 전공, 성별, 소속 등과 같은 속성이 Facebook과 같은 소셜 미디어에서 얻은 정보를 바탕으로 보다 풍부하게 추론될 수 있는 것입니다. 따라서 엄밀히 말해 Attribute Inference Attack은 모델로부터 직접, 혹은 모델을 훈련시키기 위한 데이터에서 직접 프라이버시를 유추하는 방식이 아닌 소셜 엔지니어링 (social engineering)을 통한 부가적인 프라이버시 유추 방식으로 이해될 수 있습니다.
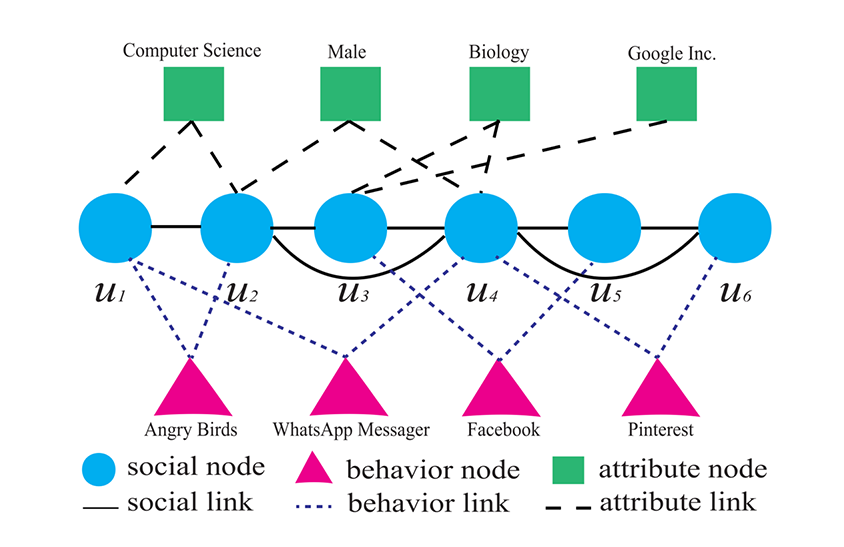 Attribute Inference Attack 개념도. 출처: Gong & Liu, 2018
Attribute Inference Attack 개념도. 출처: Gong & Liu, 2018
4. Data Memorization(데이터 포화) 문제
그 외에 Data Memorization (데이터 포화), 중앙 집중식 학습도 프라이버시 침해를 유발할 수 있는 요인이 됩니다. Data Memorization은 모델이 학습 데이터의 특징을 그대로 갖고 있는 현상을 말합니다. 모델 성능을 높이기 위한 취지에서 학습 데이터에 모델이 지나치게 적합하는 과적합 (Overfitting)이 되어 개별 데이터를 그대로 기억하는 것이 Data Memorization이라 할 수 있습니다. 과적합 문제는 모델의 일반화 성능을 떨어뜨리는 주 요인이 되기도 하지만 프라이버시 측면에서는 공격자가 모델 파라미터를 추출하고 분석해 원본 데이터의 민감한 정보를 복원할 가능성이 있습니다. 당연히 이는 프라이버시 침해 등의 문제로 이어질 수 있습니다.
5. 중앙집중식 학습 문제
중앙집중식 학습은 다름 아닌 중앙 서버에 데이터가 모여 학습을 진행하는 방식을 뜻합니다. 모델 훈련을 위한 데이터가 한 곳에 모이게 되므로 외부에서의 해킹, 내부에서의 공격 등이 발생할 경우 데이터에 담긴 프라이버시가 쉽게 유출되게 됩니다. 서버뿐 아니라 데이터 전송 과정에서 도청, 유실 등의 위험 또한 존재합니다.
Transfer Learning 보안 강화 방안
- 모델 역공학 공격 방지: 출력 정보 최소화 및 노이즈 추가
- 멤버십 추론 공격 대응: 차등 프라이버시(Differential Privacy) 적용
- 과적합 방지: 정규화 기법과 데이터 증강으로 Data Memorization 최소화
- 분산 학습 도입: 중앙집중식 학습의 단일 장애점 해결

환경 2) 얼굴 인식과 프라이버시의 충돌
얼굴 인식 기술의 활용 현황
앞선 섹션에서 Transfer Learning 환경에서의 프라이버시 문제를 살펴봤다면 이번 섹션에서는 보다 구체적으로 머신러닝 응용 시스템의 하나인 얼굴 인식 (facial recognition) 기술에서의 프라이버시 문제를 살펴보겠습니다.
얼굴 인식은 컴퓨터 비전과 머신러닝을 활용한 대표적인 기술 사례입니다. 핸드폰 비밀번호 해제, 건물 출입, 결제, CCTV 분석 등의 분야에서 얼굴 인식 기술은 활발히 쓰이고 있습니다. 사람의 신원을 간편하게 파악할 수 있다는 장점 때문에 다양한 분야에서 활용되고 있습니다.
 얼굴 인식을 통한 정치 성향 파악의 예시. 출처: Kosinski, 2021
얼굴 인식을 통한 정치 성향 파악의 예시. 출처: Kosinski, 2021
얼굴 인식 기술의 5단계 프로세스
얼굴 인식 기술 프로세스
- 얼굴 영역 탐지: Canny Edge Detector, Haar Cascade 등으로 이미지에서 얼굴 영역 식별
- 얼굴 정렬: 탐지된 영역에서 정규화와 특징점 추출
- 임베딩: DeepFace, FaceNet 등으로 이미지를 고차원 벡터로 변환
- 얼굴 매칭: 벡터 간 유사도 측정으로 가장 비슷한 데이터 매칭
- 신원 확인: 매칭 결과를 바탕으로 최종 신원 인식
이미지나 비디오에서 얼굴을 탐지 및 식별하는 얼굴 인식 기술은 크게 5가지 단계로 진행됩니다.
가장 먼저 필요한 작업은 얼굴 영역을 탐지(face detection)하는 단계입니다. Canny Edge Detector, Histogram of Oriented Gradients, Haar Cascade 등의 알고리즘이 쓰입니다.
이어 두 번째 단계로 얼굴 정렬 (face alignment)이 필요합니다. 탐지된 영역 경계 안에서 얼굴 이미지의 정규화와 특징점 추출이 진행됩니다.
세 번째 단계는 정렬된 이미지를 숫자값으로 바꾸는 임베딩 (embedding)이 진행됩니다. DeepFace, FaceNet 등의 알고리즘을 활용해 고차원의 벡터로 얼굴 이미지를 변환하게 됩니다.
네 번째 단계는 얼굴 매칭 (face matching)입니다. 벡터 간 유사도 (similarity) 측정이 중요한 단계로 임베딩을 거친 얼굴 이미지 벡터와 가장 비슷한 값을 갖는 데이터를 매칭하는 단계입니다.
마지막 단계는 매칭된 얼굴 이미지의 신원을 확인하는 단계입니다. 데이터에 따라 혹은 얼굴 인식 목적에 따라 다양한 수준의 신원이 최종적으로 인식되게 됩니다.

얼굴 인식 기술의 4가지 핵심 프라이버시 위험
얼굴 인식 기술은 개인의 신원을 대표하는 신체 정보인 얼굴 이미지 데이터를 수집하고 의사 결정에 직접 활용할 수 있게 해준다는 점에서 편리하지만 다음과 같은 프라이버시 문제와 직결됩니다.
1. 얼굴 인식 기술의 오작동 위험
첫째, 얼굴 인식 기술의 오작동입니다. 위에서 살펴본 얼굴 인식 기술은 여러 단계를 거치게 되며 이 과정에서 임베딩, 정규화, 유사도 측정 등 다양한 변환이 진행됩니다. 이 과정에서 발생 가능한 연산 오류 및 시스템 구동 차원의 에러 등 여러 오작동을 생각해 볼 수 있습니다.
2. 대량 바이오 데이터 유출의 심각성
둘째, 데이터 유출 문제도 얼굴 인식과 관련한 부정적 측면입니다. 대량의 민감 바이오 정보인 얼굴 이미지 데이터가 수집되고 관리되는 과정에서 해킹이나 유출 사고가 100% 일어나지 않을 것이라고 단언할 수 없습니다. 네트워크와 서버 상에서 얼굴 이미지가 외부 침입으로부터 안전하게 지켜져야 하는 필요성이 높아지고 있습니다.
3. 편향성과 차별의 위험
셋째, 얼굴 인식 기술의 편향성 문제도 야기할 수 있습니다. 훈련과 테스트에 쓰였던 데이터가 특정 인종 혹은 특정 성별에 치우친 특성을 내포하고 있다면 이는 해당 인종과 성별에 불리한 얼굴 인식 결과가 발생할 수 있기 때문입니다. 악의적 목적으로 악용되어 사회 약자 혹은 소수자 집단을 탄압하는데 얼굴 인식 기술이 잘못 쓰일 수 있습니다.
4. 투명성과 통제권 부재 문제
넷째, 이는 사회적으로 더 큰 맥락에서 투명성과 통제권의 문제와 연결됩니다. 즉 얼굴 인식 시스템이 개발 및 도입되는 과정에서 일반 시민들이 자신들의 얼굴 데이터가 어떻게 수집되고 활용되는지 투명하게 알 필요가 있으며 경우에 따라서는 통제도 할 수 있어야 합니다. 그러나 얼굴 인식 기술의 높은 활용에 비해 아직 투명성이나 통제권에 대한 시스템적, 정책적 수단은 일반 시민 입장에서 부족한 것이 사실입니다.
얼굴 인식 시스템 프라이버시 보호
- 데이터 최소 수집 원칙: 목적에 필요한 최소한의 바이오 데이터만 수집
- 편향성 테스트: 다양한 인종, 성별, 연령대 대상 성능 검증
- 투명성 확보: 데이터 수집 및 활용 목적 명확한 고지
- 사용자 통제권 보장: 개인정보 삭제 요구권 및 처리 거부권 제공
프라이버시 관점에서 본 Transfer Learning과 얼굴 인식 기술의 차이점
지금까지 Transfer Learning과 얼굴 인식 기술이라는 두 맥락에서 야기될 수 있는 프라이버시 문제를 살펴봤습니다. 인공지능 전 분야가 Transfer Learning과 얼굴 인식 기술만으로 대표될 수는 없으나 인공지능과 프라이버시 갈등을 잘 보여주고 그에 따른 기술적, 정책적 함의를 이야기할 수 있다는 점에서 적절한 분야라 할 수 있습니다. 끝으로 프라이버시 관점에서 Transfer Learning과 얼굴 인식 기술의 차이점을 정리하고 본 리포트를 맺도록 하겠습니다.
Transfer Learning vs 얼굴 인식 상세 비교
얼굴 인식 기술은 주로 안전, 치안, 인증, 보안 등의 분야에서 활용되며, 일상생활 전반에 걸쳐 광범위하게 적용될 수 있습니다. 따라서 얼굴 인식 정보는 개인의 신원을 직접 식별할 수 있는 고유한 바이오 데이터로 민감한 개인 식별 정보에 해당하며 프라이버시 유출 문제 발생시 사회, 정부뿐 아니라 개인에게도 심각한 피해를 줄 수 있습니다. 반면 Transfer Learning은 효율성이 중요한 의료, 금융 등 특정 도메인에서 활용됩니다. Transfer Learning에서 다루는 데이터는 분야에 따라 다양하지만 얼굴만큼 직접적이고 민감한 개인 식별 정보를 포함하지는 않습니다. 프라이버시 유출 문제 발생시에도 사후 수습하거나 모델을 업데이트 하는 등의 대처가 가능합니다. 얼굴 인식 기술의 프라이버시 문제는 사회 전반의 감시, 개인의 표현의 자유 훼손 등 사회적, 법적 문제로 이어질 수 있으나 Transfer Learning의 프라이버시 문제는 주로 데이터 관리와 모델 설계 과정에서 발생하므로 사회 전반에 미치는 직접적 영향은 얼굴 인식 기술에 비해 상대적으로 넓지 않다고 할 수 있습니다.
References
- Nguyen, N. B., Chandrasegaran, K., Abdollahzadeh, M., & Cheung, N. M. (2023). Re-thinking model inversion attacks against deep neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 16384-16393).
- Oseni, A., Moustafa, N., Janicke, H., Liu, P., Tari, Z., & Vasilakos, A. (2021). Security and privacy for artificial intelligence: Opportunities and challenges. arXiv preprint arXiv:2102.04661.
- Zhuang, F., Qi, Z., Duan, K., Xi, D., Zhu, Y., Zhu, H., ... & He, Q. (2020). A comprehensive survey on transfer learning. Proceedings of the IEEE, 109(1), 43-76.
- Fredrikson, M., Lantz, E., Jha, S., Lin, S., Page, D., & Ristenpart, T. (2014). Privacy in pharmacogenetics: An {End-to-End} case study of personalized warfarin dosing. In 23rd USENIX security symposium (USENIX Security 14) (pp. 17-32).
- Ye, D., Chen, H., Zhou, S., Zhu, T., Zhou, W., & Ji, S. (2022). Model Inversion Attack against Transfer Learning: Inverting a Model without Accessing It. arXiv preprint arXiv:2203.06570.
- Shejwalkar, V., Inan, H. A., Houmansadr, A., & Sim, R. (2021, November). Membership inference attacks against nlp classification models. In NeurIPS 2021 Workshop Privacy in Machine Learning.
- Gong, N. Z., & Liu, B. (2018). Attribute inference attacks in online social networks. ACM Transactions on Privacy and Security (TOPS), 21(1), 1-30.
- Kosinski, M. (2021). Facial recognition technology can expose political orientation from naturalistic facial images. Scientific reports, 11(1), 100.
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에게 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의 없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
사이버 보안에 관심이 있으신가요?
다음으로 인사이트 리포트 “더 강력한 방패 : 사이버 보안과 생성형 AI의 만남”을 통해 생성형 AI가 어떻게 한층 더 정교하고 효율적인 보안 솔루션 제공에 기여하는지 확인해보세요!
![]()