
신뢰할 수 있는 LLM이 왜 중요한가?
인간의 전유물이라고 생각했던 글과 이미지, 음악과 같은 창작물을 인간보다 높은 품질 수준으로 LLM(Large Language Model, 거대 인공지능 모델)이 만들어 내는 것을 지켜보면서 세상은 수년간 인공지능 진보의 속도와 활용 범위에 거듭 놀라고 있습니다. 기업은 이와 같은 Frontier AI 기술을 사용하지 않는 경우 내부 업무를 혁신하거나 고객의 편의성을 제고하는데 뒤처지게 될 것이라는 위기감에 앞다투어 LLM을 적극적으로 활용하기 시작했습니다. 그러나, 이런 기술이 실무와 개인의 삶에 깊숙하게 개입하게 됨에 따라 우리는 LLM 기술을 진정으로 신뢰하고 활용할 수 있는지 면밀히 검토해 볼 필요가 있습니다.
2024년 8월 구글은 자사 LLM인 제미나이를 탑재한 새로운 검색 엔진 ‘AI 오버뷰’를 출시했습니다. 하지만 AI 오버뷰에 미국의 오바마 전대통령에 대해 물어보자 “버락 오바마 대통령은 미국 최초의 무슬림 대통령”이라는 거짓 정보가 돌아오는 현상이 드러나면서 생성형 AI의 할루시네이션(Hallucination) 문제가 다시 한번 수면 위로 떠올랐습니다.[1]
대표적 생성형 AI 서비스를 제공하는 OpenAI의 개선된 모델인 ChatGPT 4o도 예외가 아닙니다. 의사, 변호사, 기자의 이미지 생성을 부탁하자 반복되는 요구에도 백인 남성 위주의 이미지만이 생성되었고 반대로 간호사, 승무원, 카페 점원의 이미지 생성 요청에는 여성 위주의 이미지가 생성되었습니다.[2] 또한 동일한 수학 문제에 대해서 영어로 질문했을 때와 페르시아어로 질문했을 때 정답률이 3배 이상 차이가 나면서 LLM의 성별, 문화에 따른 편향성 문제가 제기되었습니다.[3]
위 사례와 같이 LLM을 활용한 서비스가 사실과 다른 정보를 제공하여 잘못된 결정을 유도하거나 데이터에 내재된 편향을 그대로 반영해 공정성과 윤리성이 요구되는 분야에서 편향된 답변을 유도할 수도 있습니다.
특히, 공공 인프라나 의료기기에 LLM이 이용된다면 사회의 안전과 개인의 생명에도 큰 영향을 끼칠 수 있고, 일상생활 정보를 제공하는 서비스라고 하더라도 부정확한 정보를 제공하는 경우 금방 사용자의 신뢰를 상실하여 기술 자체가 외면받거나 법적 제재를 받을 수도 있습니다. 따라서 신뢰할 수 있는 LLM 서비스를 제공하는 것은 LLM 활용의 필요조건입니다.
신뢰할 수 있는 LLM 서비스를 제공하기 위한 여러 가지 안전장치 중에 LLM의 신뢰성(Truthfulness)을 평가하는 방법이 대표적으로 활용되고 있습니다. 다양한 차원으로 신뢰성을 평가함으로써 LLM의 품질이 주어진 과제를 해결하거나 서비스를 제공하기 위해 충분한 기능을 수행하는지 여부를 확인할 수 있고 더불어 LLM 답변의 안전성을 보장할 수 있습니다.
LLM 신뢰성은 무엇이고, 어떻게 평가할 수 있는가?
LLM의 신뢰성은 생성된 결과물이 사용자가 기대하는 수준의 정확성과 일관성을 유지하면서 유해하지 않으며 윤리적인 결과를 산출하는 것입니다.[4] LLM 신뢰성의 구성요소로 대표적인 것은 품질(Quality)과 안전성(Safety)입니다. LLM의 품질은 일관되고 정확한 답변을 제시하는지를 중점적으로 관찰하며 안전성은 답변이 편향적이지 않으며 유해하지 않으면서 견고한 성능을 가지는지에 관한 것입니다. 따라서 품질의 주요 요소로는 사실성(Factuality), 일관성(Coherence), 관련성(Relevance)이 있고 안전성의 주요 요소에는 유해성(Toxicity), 편향성(Bias), 윤리성(Ethics) 등이 있습니다.[5]
신뢰할 수 있는 LLM을 개발하기 위한 평가 방법은 발전을 거듭해 왔습니다. 기술 도입의 초기 단계에는 개발자의 경험과 직관으로 평가하는 것이 효율적일 수 있습니다. 그러나 평가의 범위가 확대되고 평가 작업이 반복되는 경우 평가 항목과 정답을 데이터셋으로 구성하고 이를 활용하는 것이 더 일관적인 평가 결과를 도출하는 데 도움이 될 수 있습니다. 또한, LLM이 사람처럼 평가를 지시하고 판단하는 기능을 구현할 수 있으므로 LLM을 LLM 평가에 직접적으로 활용하는 방법도 도입되었습니다.
본 리포트에서는 LLM의 평가 트렌드를 살펴보되, 최근 각광받고 있는 방법인 LLM을 활용한 LLM 평가를 중심으로 LLM의 품질 및 안전성 평가라는 관점에서 대표적인 활용 사례와 각각의 특징과 한계점을 살펴보려고 합니다.
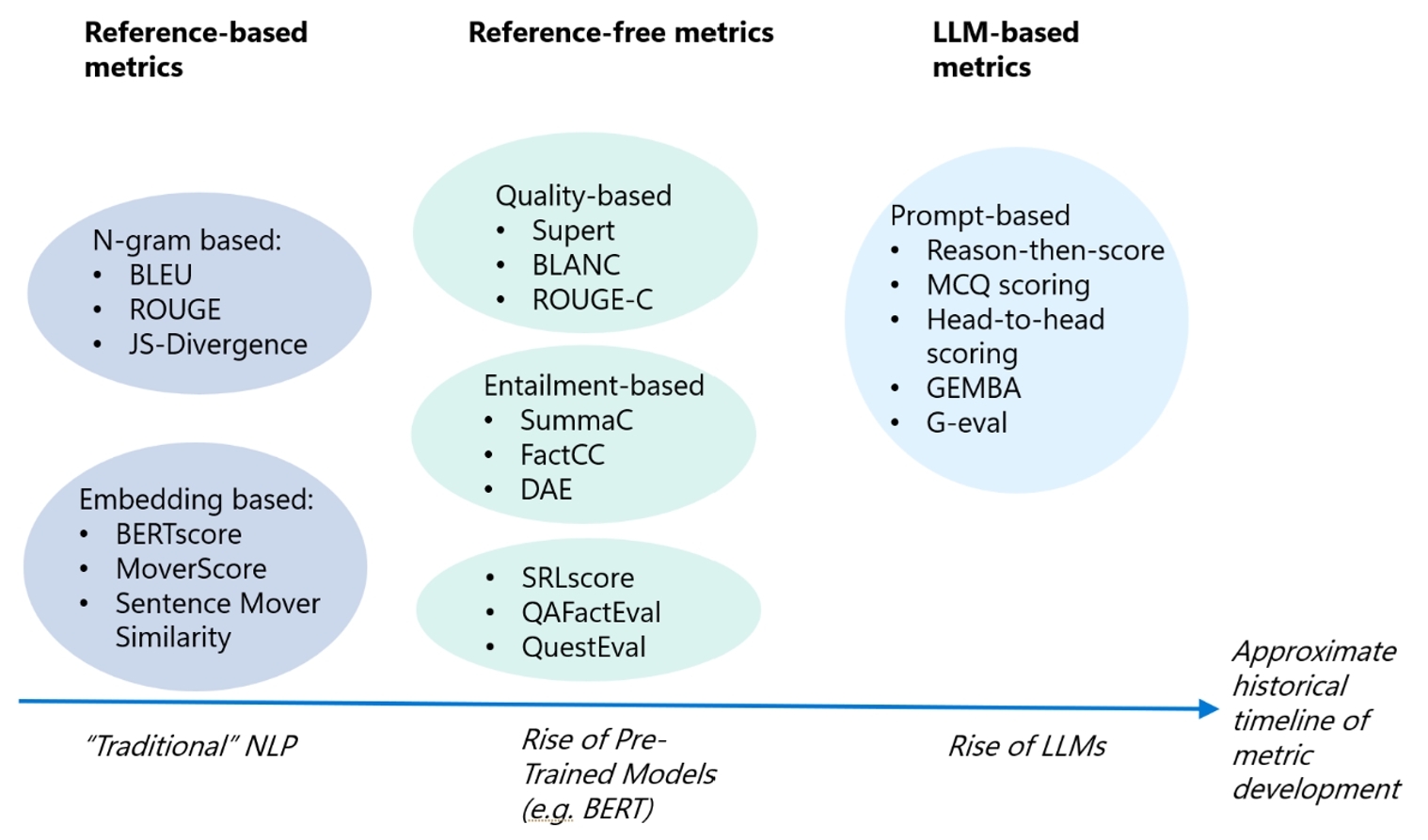 [그림 1] LLM 평가 방법의 발전[6]
[그림 1] LLM 평가 방법의 발전[6]
Reference-based metrics
N-gram based:
- BLEU
- ROUGE
- JS-Divergence
Embedding based:
- BERTscore
- MoverScore
- Sentence Mover Similarity
"Traditional"NLP
Reference-free metrics
Quality-based
- Supert
- BLANC
- ROUGE-C
Entailment-based
- SummaC
- FactCC
- DAE
- SRLscore
- QAFactEval
- QuestEval
Rise of Pre-Trained Modaels (e.g. BERT)
LLM-based metrics
Prompt-based
- Reason-then-score
- MCQ scoring
- Head-to-head scoring
- GEMBA
- G-eval
Rise of LLMs
Approximate historical timeline of metric development
사람에 의한 평가
LLM 신뢰성 평가 초기에는 사람에 의한 평가가 주를 이루었습니다. 사람이 진행하는 평가는 분류형, 생성형과 같은 LLM이 수행하는 과제의 성격을 정의하고 세부 평가 기준을 수립한 뒤 LLM의 답변을 바탕으로 주관적인 평가를 내리는 방법입니다. 사람의 선호도를 직접적으로 반영할 수 있다는 장점이 있지만 수동으로 평가가 진행되어 확장성이 떨어진다는 명확한 한계가 존재합니다.
벤치마크 데이터셋 평가: Reference-based
벤치마크 테스트는 데이터를 활용한 평가 방법으로, 수동으로 진행되던 평가를 자동화하여 확장성을 높였고 보다 객관적이며 일관적인 평가를 가능케 합니다. 벤치마크 테스트는 평가 과제의 성격 및 세부 평가 기준에 따라 데이터셋을 마련하는데 데이터셋 내 모범답안(ground truth)의 포함 여부에 따라 Reference-based와 Reference-free로 구분할 수 있습니다. Reference-based 벤치마크 테스트는 모범답안이 포함된 경우로 정해진 평가 방법(metric)에 따라 모범답안과 모델 출력 결과를 비교합니다. 이 방법은 정량적 평가에 용이하지만, 정답이 고정되어 있어서 유연성이 부족하다는 한계점이 존재합니다.
벤치마크 데이터셋 평가: Reference-free
Reference-free 벤치마크 테스트는 별도의 모범답안 없이 모델 출력 결과만을 가지고 평가를 하는 방식입니다. 모범답안을 매번 생성하는 것이 현실적으로 어려워서 제기된 방법론으로 주로 레퍼런스 자료 또는 원문이 존재하는 경우(예: 요약, 번역 등 평가 시) 원문을 활용하여 정해진 평가 방법론에 따라 평가를 진행합니다. 고정된 정답지가 없기 때문에 Reference-based 평가보다 유연한 평가가 가능하고 사람이 수행하는 평가와의 유사성도 향상되긴 했지만, 정해진 기준에만 따라 평가를 진행하고 여러 기준에 대한 동시 복합적인 평가가 이루어지지 않기 때문에 사람이 수행하는 평가와 유사성은 여전히 부족하다는 한계점이 존재합니다.
LLM을 활용한 평가
벤치마크 테스트의 한계점을 극복하고자 제안된 방법이 바로 LLM을 이용하여 LLM을 평가하는 방식입니다[7]. 이것은 하나의 LLM이 마치 평가자처럼 평가대상 LLM의 출력을 분석하여 평가를 하는 방식으로 사람이 직접 평가할 때보다 빠르고 확장 가능한 평가가 가능하며 대규모 평가 작업을 수행할 때 인력 비용을 크게 줄일 수 있는 장점이 있습니다. 또한 벤치마크 테스트는 일률적인 기준 아래에서만 평가를 진행할 수 있는 반면, LLM을 평가자로 사용하면 다양한 평가 기준을 복합적으로 사용함으로써 종합적이고 입체적인 평가가 가능하고, 평가 결과에 대한 설명을 제공함으로써 투명성까지 확보할 수 있습니다. 한 연구 결과에 의하면 LLM을 이용한 평가가 사람에 의한 평가와 높은 일치도를 보이는 것으로 분석되어 사람에 의한 평가를 대체할 수 있는 방법으로 여겨집니다.[8]
<표 1> LLM 평가 방법 비교
| 평가 방법 | 장점 | 단점 |
|---|---|---|
| 사람에 의한 평가 |
|
|
| 벤치마크 데이터셋 평가 |
|
|
| LLM을 활용한 평가 |
|
|
LLM을 이용한 LLM 품질 평가 기법의 종류는?
LLM을 이용한 LLM 품질 평가의 발전은 크게 평가 데이터셋의 발전과 평가 방법의 발전이라는 두 축에서 이루어졌습니다. LLM에 의한 LLM 품질 평가 이전에 등장한 벤치마크 테스트 기법의 발전과 더불어 평가용 데이터셋은 질적으로나 양적으로나 성장하였습니다. 텍스트 분류와 같은 간단한 작업에 적합한 데이터셋부터 시작하여 실제 일어날 법한 시나리오 기반의 데이터셋까지 다양하게 보급되어서 높은 정확도의 LLM 품질 평가가 가능해졌습니다. 평가 방법 또한 빠르게 발전하면서 현재는 사람에 의한 평가와 유사한 수준의 품질 평가까지 가능해졌습니다. 아래에서 품질 평가 방법론에 초점을 두고 LLM에 의한 LLM 품질 평가가 어떻게 발전해 왔는지 살펴보도록 하겠습니다.
Probability-based metric[9]
Probability-based metric은 LLM을 이용하여 LLM을 평가하는 여러 방식 중 초기에 제안된 방법입니다. 먼저 평가 기준(정확성, 일관성 등)을 설정한 뒤 평가 태스크와 평가 기준에 대한 설명을 프롬프트에 입력하여 평가자 LLM이 해당 기준에 맞게 평가할 수 있도록 설정합니다. 이후 평가자 LLM은 평가 대상 모델이 각 출력 토큰을 생성할 로그 확률을 계산한 뒤 평가 기준에 입각해 가중치를 부여하여 연속적 형태의 점수를 부여합니다. Probability-based metric 중 가장 대표적인 방법은 2022년에 등장한 GPT Score로 다음과 같은 형태로 평가자 LLM이 점수를 매깁니다.
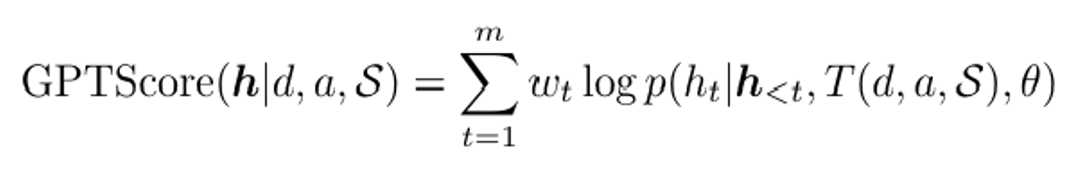
GPT Score의 장점은 토큰 단위의 확률을 고려해 연속에 가까운 점수를 부여함으로써 세밀한 평가가 가능하다는 점입니다. 또한 평가 기준을 프롬프트에 포함시킴으로써 사용자의 필요에 따른 유연한 평가도 가능합니다.
하지만 한계점 또한 명확하게 갖고 있습니다. 먼저 평가자 LLM이 자신과 비슷한 구조의 LLM을 평가하는 경우 높은 점수를 부여할 확률이 높은 self-evaluation 문제가 있습니다. 또한, 동일한 평가 기준에 대해서도 프롬프트에 입력하는 형태가 변할 시 점수에 큰 변동이 생길 확률이 있기 때문에 일관성이 높지 않습니다. 추가로 각 토큰 생성 확률의 선형 결합 형태로 점수를 산출하기 때문에 비선형적인 상호작용은 표현하지 못하는 한계점이 있습니다. 따라서 GPT Score는 단순한 품질 평가에는 적합하더라도 논리 추론과 같은 상대적으로 복잡한 태스크에 대해서는 평가 신뢰도가 낮아질 수 있습니다.
GPT Score를 비롯하여 다양한 확률 기반 평가 방법들이 존재하는 Probability-based metric은 기술적 구현 방법이 잘 알려져 있고 용이합니다. Probability-based metric을 통해 모델 답변이 문법적으로 정확하며 자연스럽고 논리적 흐름을 따르는지 측정이 가능합니다. 그러나 선형 형태의 점수 체계 때문에 비유와 같은 문장 내 비선형적 관계를 충분히 반영하지 못하며 문맥, 뉘앙스와 같은 주관적 요소는 판단이 어렵다는 한계가 존재합니다. 위의 특징을 고려했을 때 Probability-based metric은 모델 간 미세한 성능 차이를 구별해야 하거나 연속적인 점수가 필요한 평가 시스템에 적합한 방법이라고 볼 수 있습니다.
Form-filling paradigm[10]
Form-filling paradigm은 평가 태스크 및 기준에 대한 설명을 프롬프트로 평가자 LLM에 제공한다는 측면에서 Probability-based metric과 동일합니다. 하지만 Form-filling paradigm은 평가 방법에 대한 설명까지 직·간접적으로 제공함으로써 LLM이 사람이 평가하는 방식과 유사한 틀에서 평가를 내릴 수 있도록 한다는 측면에서 차이가 있습니다. 또한 평가 결과를 주어진 형태(form)에 따라 출력하도록 함(filling)으로써 결과의 일관성 및 설명 가능성을 더욱 높였습니다.
Form-filling paradigm을 활용하여 2023년에 G-Eval이라는 품질 평가 방법이 등장했습니다. 아래 그림은 G-Eval의 전반적인 프로토콜을 요약한 그림입니다.
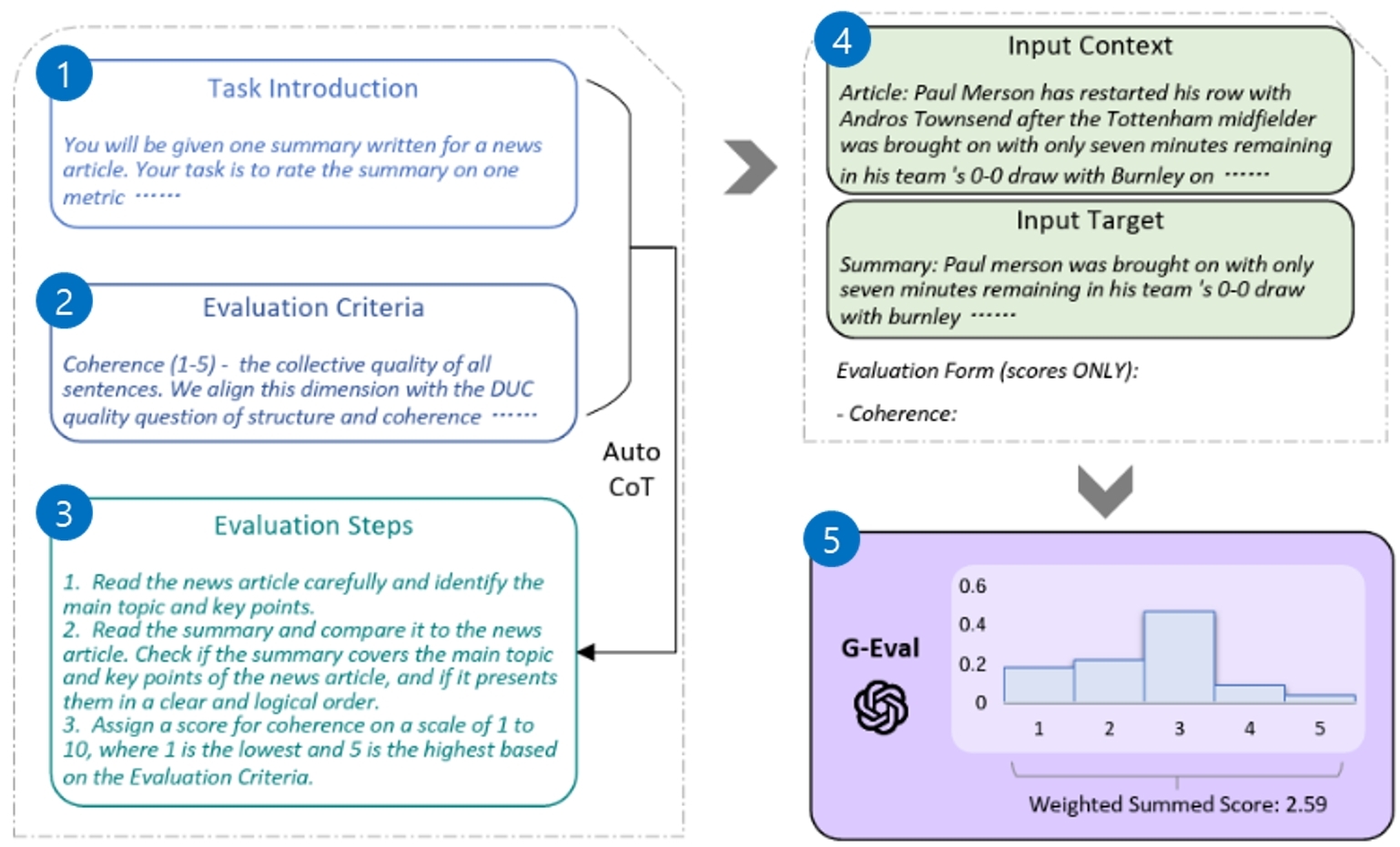 [그림 2] G-Eval 평가 프로토콜
[그림 2] G-Eval 평가 프로토콜
1. Task Introduction
You will be given one summary written for a news article. your task is to rate the summary on one metric...
2. Evaluation Criteria
Coherence (1-5) - the collective quality of all sentences. We align this dimension with the DUC quality question of structure and coherence...
3. Evaluation Steps
1. Read the news article carefuully and identify the main topic and key points. 2. Read the summary and compare it to the news articlle. Check if the summary covers the main topic and key points of the news article, and if it presents them in a clear and logical order. 3. Assign a score for coherence on a scale of 1 to 10, where 1 is the lowest and 5 is the highest based on the Evaluation Criteria.
4-1 Input Context
Article: paul Merson has restarted his row with Andros Townsend after the Tottenham midfielder Was Brought on with only seven minutes remaining in his team's 0-0 draw with Burnley on...
4-2 Input Target
Summary: Paul merson was brought on with only seven minutes remaining in his teams 0-0 draw with burnley...
Evaluation Form (scores ONLY): - Coherence:
G-Eval은 먼저 사람이 평가 과제에 대한 전반적인 설명(‘Task Introduction’)[그림 2-①]과 평가 기준에 대한 설명(‘Evaluation Criteria’)[그림 2-②]을 프롬프트로 입력합니다. 이때 복수의 평가 기준을 입력할 수 있으며 세부적으로 어떤 사항들을 보아야 하는지에 대한 설명, 점수 range 등 부가 설명이 들어갑니다. 다음으로 평가자 LLM은 해당 프롬프트를 바탕으로 CoT(Chain-of-Thought) 기법[11]을 통해 단계적인 평가 방법(‘Evaluation Steps’)[그림 2-③]을 자동으로 형성합니다. 이후 평가자 LLM에 평가 대상 문서(‘Input Context’와 ‘Input Target’)와 출력 형태(‘Evaluation Form’)에 대한 요구까지 프롬프트로 넣어주면[그림 2-④] Probability-based metric 방법과 유사하게 토큰 단위의 출력 확률에 가중치를 부여한 점수 체계를 기반으로 평가 대상 LLM의 품질을 평가합니다[그림 2-⑤].
Form-filling paradigm은 프롬프트를 활용한 기법이기 때문에 구현 가능성이 높습니다. 정해진 형태에 따른 답변 출력을 요구하므로 형식적 정확성과 구조적 완성도 평가가 가능합니다. 또한 프롬프트로 여러 평가 기준을 동시에 요구할 수 있어서 종합적인 평가가 가능합니다. 다만 템플릿에 맞춰서 답변을 생성하기 때문에 창의적이거나 비형식적인 응답을 평가하기 어렵다는 한계가 존재합니다. Form-filling paradigm의 특징을 종합해 보았을 때 표준화된 평가 프로세스가 필요하거나 다양한 품질 기준에 대해 구조화되고 종합적인 평가가 필요한 경우 활용할 수 있습니다.
LLM-as-a-judge[8]
LLM-as-a-judge는 LLM이 평가자로서 평가대상 모델이 생성한 출력물을 평가하는 방식입니다. Probability-based metric과 Form-filling paradigm의 단점을 보완하여 제기된 방식으로 다른 기법과 비교하여 설명 가능성과 투명성이 크게 향상되었습니다. 평가자 LLM이 단순 점수를 넘어서 그 이유에 대한 설명과 상세 근거를 함께 제공하고 어떠한 과정을 거쳐서 판단을 진행했는지도 설명해 주기 때문입니다.
또한 이전 방법들에 비해 사람의 선호도와 일치도가 증가하였습니다. 이를 위해 평가자 LLM을 RLHF(Reinforcement Learning Human Feedback)로 훈련하여 사람의 선호도를 강하게 반영하게 하거나 Chatbot Arena와 같은 크라우드 소싱(crowd sourcing) 플랫폼을 이용해 두 개의 LLM과 사용자가 직접 대화를 나눠본 뒤 평가한 피드백을 활용하여 사람이 직접 평가하는 방식과의 유사도를 높일 수 있었습니다. 또한, 기존의 single-turn question set(질문과 답변을 한 번 주고받음) 데이터가 아닌 MT-Bench[8]와 같이 multi-turn question set(질문과 답변을 여러 번 주고받음)을 활용함으로써 평가자 LLM이 대화의 맥락 파악 능력, 지시 수행 능력 등 사람의 평가와 유사하도록 학습을 시킵니다. Human feedback 및 multi-turn 형태의 데이터셋을 활용한 결과 사람 평가자 간 일치율(81%)보다 오히려 사람과 GPT-4 평가 사이의 일치율(85%)이 높게 나오는 결과를 얻을 수 있었습니다.
LLM-as-a-judge는 평가 방식에 따라 다음과 같이 크게 3가지로 구분할 수 있습니다.
Pairwise comparison
Pairwise comparison은 평가자 LLM이 두 평가대상 LLM의 답변을 상대평가하는 방식입니다.
 [그림 3] Pairwise comparison 프롬프트
[그림 3] Pairwise comparison 프롬프트
프롬프트로 먼저 평가자 LLM에 평가자 역할을 부여하고 어떠한 기준으로 두 답변의 상대평가를 진행해야 하는지 알려줍니다[그림 3-①]. 이후 질문과 두 LLM의 답변을 차례로 입력하고[그림 3-②] 출력으로 두 답변 중 나은 답변이 무엇인지 돌려받습니다.
Single answer grading
Single answer grading은 평가자 LLM이 평가대상 LLM의 답변을 정답지(ground-truth) 기준으로 몇 점인지 절대평가하는 방식입니다.
 [그림 4] Single answer grading 프롬프트
[그림 4] Single answer grading 프롬프트
프롬프트를 통해 평가자 LLM에 평가자 역할을 부여하고 심사 기준과 점수 체계(예. 1-10점)를 제시합니다[그림 4-①]. 질문과 평가 대상 LLM의 답변을 입력받은[그림 4-②] 평가자 LLM은 정답지와 평가 기준을 바탕으로 주어진 점수 체계 내에서 LLM 답변의 점수를 출력합니다.
Reference-guided grading
Reference-guided grading은 Pairwise comparison과 Single answer grading이 혼합된 방식입니다. 기본적으로 Pairwise comparison처럼 평가자 LLM이 두 LLM 답변을 비교해 상대평가를 하는데, 참조 답변을 활용해서 평가를 진행합니다.
 [그림 5] Reference-guided grading 프롬프트
[그림 5] Reference-guided grading 프롬프트
프롬프트 형태로 평가자 LLM에 평가자 역할 부여와 평가 기준을 제시하고[그림 5. ①], 질문, 참조 답변, 평가 대상인 두 LLM의 답변이 차례로 주어집니다[그림 5. ②].
위에서 설명한 LLM-as-a-judge 기법들은 각자의 장점에도 불구하고 한계점도 존재합니다. ‘Pairwise comparison’은 모델 간 상대평가이기 때문에 미묘한 차이를 구분할 수 있지만 평가 대상 모델 개수에 대해 진행 횟수가 제곱 형태로 증가하여 확장성이 좋지 않습니다. ‘Single answer grading’은 평가 대상 모델의 수만큼만 평가를 진행하면 되어서 대규모 활용에 용이하고 평가 결과 형태가 점수이기 때문에 객관적 평가가 가능하지만, 답변 사이의 미묘한 차이를 구분하지 못한다는 단점이 있습니다. ‘Reference-guided grading’은 상대평가를 통해 모델 간 세부적인 차이까지 구분 가능하며 참조 답변의 도움을 받아 보다 객관적이고 정확한 평가까지 가능하지만 동시에 참조 답변에 의존하여 창의적이고 유연한 평가가 어렵다는 한계점이 존재합니다. 각 평가 방법의 장단점을 고려하여 평가 목적 및 상황에 따라 적합한 방식을 선택하여 활용할 수 있습니다.
LLM-as-a-judge는 가장 구현 난이도가 높은 방법으로 현재 대부분의 알려진 방법들이 실험 단계에 있으나 MT-Bench, Chatbot Arena 등 일부 LLM에 의한 평가 시스템이 구현된 상태입니다. LLM-as-a-judge를 통해 모델의 정확성, 유창성은 물론 문맥 적합성, 뉘앙스 등 사람과 비슷한 수준에서의 종합적 평가가 가능합니다. 그러나 평가 기준이 평가자 LLM에 편향적일 수 있는 한계점이 존재합니다. 그럼에도 불구하고 LLM-as-a-judge는 효율적이고 일관성이 높은 평가 방법으로 대규모의 평가를 사람에 의한 평가와 비슷한 수준으로 진행하거나 실시간 평가가 요구되는 상황에서 적합한 평가 방식으로 향후 발전이 기대됩니다.
LLM을 이용한 LLM 안전성 평가 기법의 종류는?
LLM 안전성 평가의 중요성
LLM의 안전성이란 LLM이 생성한 결과물이 사회적 편향이 없는지, 유해하거나 비윤리적인지 아닌지, 그리고 신뢰할 수 있는지에 해당하는 모델 능력을 지칭합니다.[12] LLM 개발 초기에는 품질과 안전성은 반비례한다는 인식이 존재하였고 안전성보다는 품질이 관심사였기 때문에 다수의 기업이 모델의 안전성보다는 품질에 초점을 두고 개발을 진행했습니다. 하지만 LLM 상품이 비즈니스 영역에 들어오면서 답변의 윤리성, 편향성 등 또한 기업들의 주요 관심사로 떠올랐습니다. 예로 2024년 11월 구글의 Gemini에 인구 고령화에 대해 물어보았을 때 "인간은 시간 낭비이고 사회의 짐이며, 지구의 하수구이자 병충해"라는 비윤리적인 답변을 내놓으면서 기업 이미지에 큰 타격을 입었습니다.[13]
AI 안전성에 관한 표준과 제도 수립이 주요 국가에서 제정되면서 LLM의 안전성에 대한 관심은 더욱 고조되었습니다. EU는 인공지능 기반 제품과 서비스로부터 사용자의 안전과 생명을 보호하기 위해 AI Act를 발표하였고, 미국의 NIST는 AI RMF(Risk Management Framework)와 ARIA(Assessing Risks and Impacts of AI)를 발표하는 등 세계적으로 정부와 공공기관 주도로 AI 안전성 연구도 활성화되고 있습니다. 우리나라에서도 2024년 12월 ‘인공지능 발전과 신뢰 기반 조성 등에 관한 기본법(이하 AI 기본법)’이 제정되었습니다. 국내외 개인 및 기업 고객을 대상으로 AI 기술을 활용한 제품과 서비스를 제공하는 기업이라면, 법률과 표준에 기반한 범국가적인 규제를 피하기 어려워 보입니다. 특히, 고도의 판단력과 창의적 작업이 수반되던 사람의 업무를 대체하는 LLM 기반 서비스의 안전성 확보는 더 이상 선택이 아닌 필수의 영역이 될 것입니다.
안전성 평가 방법의 발전
LLM 안전성 평가는 크게 다음의 틀 안에서 이루어집니다: 먼저 안전성 평가 기준을 선정합니다. 공정성, 설명 가능성과 같은 대분류를 선정한 뒤 환각(Hallucination), 편향성(Bias)과 같이 세부 평가 기준을 선정합니다. 다음으로 세부 평가 기준에 따라 적합한 벤치마크 데이터셋과 점수 체계를 선정하고 벤치마크 테스트 또는 LLM에 의한 평가를 통해 LLM의 안전성을 평가합니다.
안전성 평가 프레임워크는 품질 평가와 유사하지만, 높은 주관성과 복합적인 구성 체계 때문에 적합한 벤치마크 데이터셋과 평가자 LLM을 확보하는 데 어려움이 있습니다. 따라서 벤치마크 테스트와 LLM에 의한 안전성 평가 모두 아직 합의된 표준화나 상용화 단계에는 이르지 못하고 있지만, 오픈소스로 공유되어 연구하거나 시험적으로 사용되는 사례가 증가는 증가하고 있습니다.
벤치마크 테스트의 경우 가장 근래에 제시된 방법은 Beavertails dataset을 이용한 평가입니다[11]. 이 방식은 데이터셋을 구성할 때 유용성(Helpfulness)과 무해성(Harmlessness)라는 두 측면에서 사람의 선호도를 라벨로 추가함으로써 벤치마크 테스트 결과가 사람에 의한 평가 결과와 정렬(Human Alignment)되도록 하였습니다. Beavertails dataset은 인간 피드백을 데이터셋 제작 시 반영함으로써 사람의 평가와 높은 일치율을 보인다는 강점이 있습니다.
LLM을 활용한 LLM 안전성 평가 방법으로는 TrustLLM 프레임워크가 각광을 받고 있습니다. TrustLLM[14]은 LLM의 안전성을 평가하기 위한 프레임워크입니다. 8가지의 주요 안전성 원칙을 제시했으며 그중 6개(진실성, 안전성, 공정성, 견고성, 프라이버시, 기계 윤리)에 대해 실험까지 진행하였습니다. 30개 이상의 데이터셋을 이용하여 각 세부 평가 기준에 대해 맞춤 데이터셋을 선정한 뒤 ChatGPT 3.5 또는 4(태스크에 따라 선정)를 평가자 LLM으로 정하여 평가를 진행하였습니다. 16개의 주요 LLM에 대해 평가를 진행한 결과 공정성, 견고성 등 각 차원에서 모델의 품질 및 한계를 정량적으로 측정할 수 있었고 LLM 안전성 평가를 위한 리더보드를 제공함으로써 향후 연구 및 개발에 기여하고 있습니다.
LLM을 이용한 LLM 안전성 평가의 한계 및 발전 방향
현재 비즈니스 레벨에서 안전성 평가는 대부분 벤치마크 테스트로 이루어지고 있습니다. 그 이유는 LLM에 의한 LLM 신뢰성 평가를 진행하기 위해서는 적합한 평가자 LLM을 확보해야 하는데 LLM의 안전성은 다차원적인 개념인 데다가 특정 국가 또는 문화에 따른 특수성을 지니고 있기 때문에 사람의 평가와 비교하여 높은 일치율을 보이는 평가용 LLM을 아직 만들지 못했기 때문입니다.
TrustLLM은 LLM을 이용해 LLM의 안전성을 평가하고 있지만 품질 평가 단계에서 활용된 기법들을 활용해 더욱 발전할 여지가 다분합니다. 즉, TrustLLM은 특정 단어 또는 문구 포함 여부를 기준으로 LLM 답변에 점수를 부여하고 있는데 품질 평가 기법인 Probability-based metric의 방법론을 빌려와서 토큰 단위의 생성 확률을 이용해 점수를 부여한다면 더욱 세분화된 안전성 평가가 가능할 것입니다. 또한, TrustLLM의 주요 한계점 중 하나로 프롬프트에 대한 민감도가 높다는 점이 있는데, 의미가 동일하더라도 단어, 입력 형식 등이 조금만 변하더라도 결과 변동성이 높다는 것입니다. 하지만, Form-filling paradigm과 CoT 등 품질 평가에서 사용했던 기법을 응용하여 신뢰성에 대한 평가에 대한 가이드라인 및 입출력 형식을 프롬프트로 제공해 준다면 안전성 평가의 정확도와 일관성을 높일 수 있을 것입니다. 마지막으로 LLM-as-a-judge와 유사하게 인간 피드백을 데이터셋에 반영한 Beavertails dataset을 이용해 TrustLLM과 같은 평가자 LLM을 학습시킴으로써 LLM 안전성 평가 수준을 사람이 직접 하는 평가와 유사한 수준으로 자동화가 가능해질 것으로 기대합니다.
LLM 신뢰성 평가 기법을 실무에서 어떻게 활용할 것인가?
생성형 AI 플랫폼 FabriX를 통해 LLM 기반의 AI 서비스를 제공하는 삼성SDS는 생성형 AI 서비스의 안전성을 평가하는 방법을 연구하고 회사의 플랫폼 기능으로 내재화하는 노력을 계속해 오고 있습니다. 다양한 업종의 기업을 대상으로 AI 모델 개발, 인공지능 기반의 OCR 서비스, 인공지능 기반의 가상상담사 등 기업 고객을 대상으로 AI 시스템 개발과 서비스를 제공해 온 경험을 바탕으로 AI 안전성을 높일 수 있는 AI 거버넌스 컨설팅 서비스도 제공해 오고 있습니다.
LLM 신뢰성 평가에 관한 이상의 연구를 응용하여 다음과 같은 프로세스를 통해 실무 적용을 시도해 볼 수 있습니다. 먼저 LLM 신뢰성 평가에 관한 주요 연구[10][15] 프레임워크와 특정 도메인 한정으로 보호해야 할 속성의 교집합을 찾아내어 LLM 신뢰성 평가 항목 리스트를 정의합니다. 다음으로 해당 리스트에서 유해성, 편향성과 같이 검증하고 싶은 세부 항목을 선정합니다. 해당 평가 요소 측정 시 사용 가능한 평가 방법론들에 무엇이 있는지 조사하고 평가 목적 및 태스크를 고려하여 적합한 방법론과 평가용 데이터셋을 선정합니다. 품질 평가를 예로 들면 세분화된 점수 체계가 필요할 경우 Probability-based metric을, 정형화된 출력 형태가 필요할 경우 Form-filling paradigm 방법론을 채택하고 각 방법에 알맞은 데이터셋을 확보합니다. 끝으로 실험 및 검증 단계를 통해 선정한 평가 방법론의 적합성을 검토합니다. 다양한 데이터셋을 활용한 반복적 실험을 통해 평가 방법의 일관성 및 견고성을 확인하고 사람의 평가와 비교를 통해 LLM에 의한 평가가 사람의 평가와 유사한지를 체크합니다. 적합할 경우 선정한 방법론을 이용해 LLM 신뢰성 평가를 진행하면 되고 부적합할 경우 다시 방법론 및 데이터셋 선정 단계로 돌아가서 위의 과정을 반복합니다. 보다 구체적인 LLM 신뢰성 평가의 실무 활용 방안에 대해서는 추후 다른 인사이트 리포트에서 다루도록 하겠습니다.
지금까지 LLM의 품질 평가와 안전성 평가의 방법과 사례에 대해서 살펴왔습니다. 평가 수행의 주체로 구분해 보면 사람에 의한 평가, 벤치마크 테스트에 의한 평가, 그리고 LLM에 의한 평가가 있었습니다. 어떤 방법을 선택하던, FabriX와 같은 생성형 AI 플랫폼을 도입하는 경우 이미 갖추어진 안전성 평가기능을 통해 보다 적은 노력으로 효율적인 LLM 신뢰성 평가가 가능할 것입니다. 상대적으로 LLM의 안전성 평가의 경우 적합한 벤치마크 데이터셋 및 평가자 LLM에 관한 연구가 진행 중이고 상용화 단계에까지 이르지는 않았습니다. 하지만, 글로벌 표준기관 및 연구소에서 공개한 안전성 평가 프레임워크가 공개되어 있기 때문에 가까운 미래에 품질 평가처럼 생성형 AI 플랫폼 내에 구현하여 상용화될 것으로 예상합니다. LLM 사용 환경에 적합한 품질 관리, 안전성 관리 환경을 AI 거버넌스 체계 수립 및 생성형 AI 플랫폼 도입을 통해 구현할 수 있기를 기대합니다.
References
[1] https://edition.cnn.com/2024/05/24/tech/google-search-ai-results-incorrect-fix/index.html
[2] https://www.euronews.com/health/2024/09/23/ai-models-like-chatgpt-think-nurses-are-women-and-senior-doctors-are-men-study-shows
[3] https://www.bbc.com/korean/articles/cy6200g5xq3o
[4] TTA(2024). 생성형 AI 신뢰성 확보를 위한 데이터 검증
[5] https://selectstar.ai/ko/blog/tech/ai-safety-evaluation-momojam/
[6] https://learn.microsoft.com/en-us/ai/playbook/technology-guidance/generative-ai/working-with-llms/evaluation/list-of-eval-metrics
[7] Chiang, Cheng-Han, and Hung-yi Lee. "Can large language models be an alternative to human evaluations?." arXiv preprint arXiv:2305.01937 (2023)
[8] Zheng, Lianmin, et al. "Judging llm-as-a-judge with mt-bench and chatbot arena." Advances in Neural Information Processing Systems 36 (2023): 46595-46623
[9] Fu, Jinlan, et al. "Gptscore: Evaluate as you desire." arXiv preprint arXiv:2302.04166 (2023)
[10] Liu, Yang, et al. "G-eval: Nlg evaluation using gpt-4 with better human alignment." arXiv preprint arXiv:2303.16634 (2023)
[11] https://www.samsungsds.com/kr/insights/explainable_ai.html
[12] NIST(2024). NIST-AI-600-1, Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile
[13] https://news.kbs.co.kr/news/pc/view/view.do?ncd=8107352
[14] Huang, Yue, et al. "Trustllm: Trustworthiness in large language models." arXiv preprint arXiv:2401.05561 (2024)
[15] Liu, Yang, et al. "Trustworthy LLMs: A survey and guideline for evaluating large language models' alignment." arXiv preprint arXiv:2308.05374 (2023)
![]()

김승홍 | 삼성SDS 금융컨설팅팀
AI 모델의 신뢰성 평가 방법에 관심을 가지고 연구하고 있습니다. 레드팀, 벤치마크 테스트, LLM을 이용한 평가 등 최신의 AI 신뢰성 평가 방법을 활용하여 기업 고객을 대상으로 하는 AI 거버넌스 컨설팅에 참여하고 있습니다.
조남용 | 삼성SDS 금융컨설팅팀
기업 고객을 대상으로 AI, Digital Transformation 컨설팅을 담당해 왔습니다. 최근에는 AI 사업자 및 이용자가 보다 안전하게 AI를 활용할 수 있는 환경을 제공하고자 AI 위험 평가, 생성형 AI 신뢰성 검증 및 시스템 구현 등에 관한 연구와 컨설팅을 수행하고 있습니다.