

데이터 관리 트렌드
나날이 증가하는 방대한 데이터와 새로운 포맷의 데이터들을 수집하고 축적/활용하려는 요구는 계속 증가하고 있습니다. 하지만 전통적인 ETL/DW 방식의 데이터 관리로 이를 해결하는 데에는 한계가 있습니다.
때문에 최근 업계는 정형 데이터로 구성된 전통적인 소스 외에 수많은 비정형 데이터들(소셜 텍스트, 센서 데이터, 이미지, 동영상 등)을 실시간으로 수집, 정제, 통합하여 활용하기 위한 방안으로, 빅데이터 수용이 가능한 Data Lake를 구축하여 원천 데이터 및 분석/서비스 데이터를 준비하는 새로운 방식의 Data Lake 관리 플랫폼에 주목하고 있습니다.

Data Lake 관리 플랫폼
Data Lake란, ‘다양한 형태의 원형(raw) 데이터들을 모은 저장소의 집합’으로, 숙련된 데이터 사용자들(데이터 엔지니어, 데이터 사이언티스트, 데이터 분석가, 개발자 등)이 이를 통해 원형 데이터들을 관찰하고 다양하게 가공/분석하여 인사이트를 찾을 수 있습니다.
하지만 사용자가 Data Lake에서 빅데이터를 분석해 인사이트를 얻거나 의사결정 지원을 위한 리포팅/서비스 애플리케이션을 만들고자 할 경우, 데이터 준비(수집/정제/변환) 과정에만 작업시간의 대부분(80%)이 소요됩니다.
유용한 것으로 바꾸는 데 드는 시간이
데이터를 분석하는 나머지 시간을 합한 것보다 많다.”
- Pete Warden, Google Data Engineer
“Algorithms are easy to copy. Data is a defensible barrier.”
- Andrew Ng
‘Data Lake 관리 플랫폼’은 많은 시간과 노력이 소비되는 데이터 준비 과정을 시스템화하여 데이터 엔지니어가 효과적으로 데이터를 처리/관리할 수 있도록 돕고, 데이터 사이언티스트에게 데이터를 Provisioning 해주어 분석에 집중할 수 있는 환경을 제공합니다. 빅데이터의 활용과 분산컴퓨팅 기술이 발전하면서 이러한 Data Lake 관리 플랫폼이 데이터 솔루션 시장에서 많은 관심을 받기 시작했죠.
Data Lake 관리 플랫폼은 다음과 같은 기술 요소들을 제공할 수 있어야 합니다.
Bulk Data Movement / Dynamic Data Movement
데이터 수집 기술로 배치, 스트림 등 다양한 실시간 서비스(Hard/Near/Soft-Real Time)를 보장하는 소스데이터의 수집이 가능하고, 다양한 구조(비정형/반정형/정형)의 데이터에 대한 수집 파이프라인 생성과 실행 및 흐름 관리도 가능해야 합니다. 특히 수집 파이프라인은 빠르고, 신뢰할 수 있으며, 유연해야 하죠.
Data Access Infrastructure
쉽고 빠른 데이터 수집을 위해 데이터 사용자, Data Lake 관리 플랫폼, 데이터 소스 간에 어떠한 하드코딩 없이 연결돼야 합니다. 또, ODBC, JDBC Driver뿐만 아니라 다양한 데이터 소스에 대해 Built-In된 연결 어댑터들을 갖고 있어야 하며, 필요한 경우 연결 어댑터에 대한 사용자 정의가 가능해야 합니다.
Composite Data Framework
다양한 이기종 데이터 소스(RDB와 HDFS, NoSQL 등)로부터 연결 어댑터 및 각 데이터 소스의 메타정보를 이용해 하나의 저장소에 존재하는 것처럼 접근하고, 데이터 스키마 정보를 이용해 데이터를 미리 수집하지 않고 Join/Merge하여 새로운 데이터세트를 생성할 수 있습니다. 이는 데이터 가상화 기술로 데이터 저장공간 효율화 및 원하는 데이터세트의 빠른 Prototyping을 위해 사용될 수 있습니다.
Data Quality
중요한 데이터는 품질 관리 기술을 통해 수집 데이터에 대한 품질 모니터링 및 프로파일링 정보(데이터 분포, 통계정보, 샘플 등)를 제공할 수 있어야 하며, 데이터 검증(ex. 이메일, IP 주소, 전화번호 등 지정된 데이터 포맷에 대한 Rule 체크) 및 중복 데이터 제거가 가능해야 합니다. 또한 개인 정보 비식별화, 데이터 표준화(특정 데이터 포맷으로 자동 변환 등), 결측치 보정, 이상치 탐지 등의 데이터 정제 작업도 이에 해당합니다.
Metadata Management
데이터 수집 이후, 데이터 준비 및 분석을 위해 Data Lake에 저장된 데이터를 이해하는 과정은 매우 중요합니다. 메타데이터는 ‘데이터에 대한 데이터’로, 데이터의 정의와 언제, 어떻게, 누구에 의해 작성되고 최종 수정되었는지 등의 정보를 포함합니다. 메타데이터에 Tagging을 해두면, 사용자가 검색을 통해 손쉽게 데이터 사용방법을 결정할 수 있어 많은 도움이 됩니다. 더불어 Data Lineage(계보)를 이용해 어떻게 이 데이터가 만들어졌는지 추적이 가능하죠. 이러한 메타데이터 관리 기술은 데이터에 대해 엄격히 규제된 산업일수록 매우 유용하게 사용될 수 있으며, 메타데이터에 대한 사용자/그룹별 접근제어도 필요해 Data Governance와 밀접한 관련이 있습니다.
Master Data Definition and Control
마스터 데이터를 유지하고 무결성을 보장하기 위해 마스터 데이터의 관계와 속성, 계층구조, 처리규칙 등의 메타데이터를 관리합니다. 주요 기능에는 데이터 모델링과 데이터 가져오기/내보내기, 버전 관리, 동기화 등이 포함됩니다. 또한 사용자/그룹별 마스터 데이터 및 처리에 대한 접근제어가 가능해야 하며 Data Governance와 밀접한 관계를 갖고 있습니다.
Self-Service Data Preparation
현재 Data Lake 관리 플랫폼의 구성요소 중 가장 트렌디한 기술입니다. 머신 러닝/딥 러닝을 기반으로 데이터 정제/변환/탐색을 자동화해서 사용자가 쉽고 빠르게 원하는 데이터를 준비할 수 있게 해주죠. 데이터세트를 자동으로 분류, 표준화하고 서로 유사한 데이터세트를 찾아주며, 데이터 변환 시 다양한 함수를 추천하는 기능도 갖고 있습니다. 특히 데이터 엔지니어, 데이터 사이언티스트뿐만 아니라 숙련되지 않은 비즈니스 분석 실무자도 IT 기술 없이 데이터를 준비할 수 있어야 한다는 요구를 해결할 수 있어 최근 데이터 솔루션 시장에서 각광받고 있습니다.
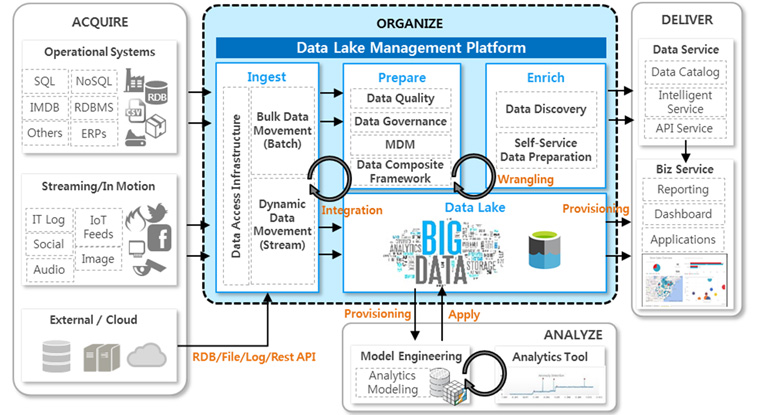 [그림1] Data Lake 관리 플랫폼 아키텍처 기반의 빅데이터 처리 과정
[그림1] Data Lake 관리 플랫폼 아키텍처 기반의 빅데이터 처리 과정
위의 Data Lake 관리 플랫폼의 기술 요소들을 통해 사용자들은 데이터의 크기, 유형(정형/반정형/비정형), 속도가 다양한 빅데이터를 보다 쉽게 통합하고, 원하는 형태로 데이터를 준비하고 분석할 수 있습니다. 특히 배치, 스트림 데이터의 처리를 빠르고 유연하게 수행하여 데이터를 통합하기 때문에, 데이터 사일로(Silo)가 제거되어 저장공간의 효율화, 데이터 관리 및 거버넌스 작업 간소화가 가능합니다.
또한 작업시간의 대부분이 소요되는 데이터 준비 과정에 Self-Service Toolkit을 제공함으로써 데이터 사용자들이 수집한 데이터를 Intelligent하게 가공/탐색하여 원하는 데이터세트를 얻는 시간을 절감하고 데이터 분석에 집중할 수 있게 해줍니다.
아래와 같이, Data Lake, Data Preparation의 중요성은 관련 업계에서 꾸준히 성장하고 있습니다.
데이터 관리 업계 전망
1) The data lakes market
- is estimated to grow from USD 2.53 Billion in 2016 to USD 8.81 Billion by 2021, at a Compound Annual Growth Rate (CAGR) of 28.3%
- The market in APAC is expected to grow at the highest CAGR between 2016 and 2021. The primary driving forces for this growth are increasing technological adoption and huge opportunities across industry verticals in APAC countries, especially India, China, and Japan.
2) The data preparation market
- is estimated to grow from USD 1.46 Billion in 2016 to USD 3.93 Billion by 2021, at a Compound Annual Growth Rate (CAGR) of 25.2% during the forecast period
- The APAC region is in the initial growth phase; however, it is expected to be the fastest growing region for the global data prep market. The key reason for the high growth rate in APAC is the growing demand for cost-effective data prep platforms and tools among small and medium enterprises in this region
전 세계 데이터의 85%가 소셜텍스트, 센서, 머신 로그, 이미지 등과 같은 빅데이터지만, 이들 중 실제로 분석 대상이 되거나 활용되는 데이터는 1%에 지나지 않습니다. 하지만 빅데이터 활용에 대한 요구가 나날이 증가하고 있고, 데이터의 양이 적은 기업도 IoT/Cloud/AI 기반의 빅데이터 세상에서 벗어날 수 없는 시대가 도래했습니다. 또, 소규모의 데이터에 빅데이터를 한 방울만 떨어뜨려도 순식간에 빅데이터화 되기 때문에 Data Lake에 대한 수많은 도전은 이어질 것입니다.
삼성SDS IoT &클라우드 연구팀은 빅데이터/AI가 중심이 되는 이 시대에, 많은 시간과 노력이 소비되는 빅데이터 처리 작업을 시스템화하고, 데이터 엔지니어가 데이터를 보다 효과적으로 서비스하고 관리할 수 있도록 지원하고 있습니다. 또, 데이터 사이언티스트가 데이터를 더 빠르게 준비하여 분석에 집중할 수 있도록 선도하고자 Data Lake 관리 플랫폼 기술을 확보하고 연구하고 있습니다.
- Gartner IT Glossary > Data Lake
- IDC's Worldwide Software Taxonomy, 2017
- Preparing and Architecting for Machine Learning, 2017
- MarketsandMarkets, 2018
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
![]()

삼성SDS 개발실 빅데이터개발팀
IoT플랫폼개발그룹으로서, 빅데이터 처리 및 분석 경험을 바탕으로 IoT 및 Data Lake 플랫폼 연구/개발과 빅데이터 전문가로 활동하고 있습니다.