
오늘은 딥페이크(Deepfake)에 대해 좀 더 깊게 알아보겠습니다.
딥페이크(Deepfake) 명칭은 2017년 미국 온라인 커뮤니티 Reddit에 합성 이미지를 등록한 user의 nickname에서 유래한 것으로 알려졌지만, 관련 기술은 그보다 앞선 2014년 이름부터 ‘멋진 친구'인 Ian Goodfellow(1)가 발표한 논문(2)에서 처음 언급되었습니다.
(1) 스탠포드대 시절 발표. 이후 Google, OpenAI 등 거친 뒤 Apple 재직 중(2019~)
(2) ‘Generative Adversarial Nets’, NIPS 2014(연재일 기준 42,332회 인용)
AI 분야에서 자세한 설명이 필요 없을 정도로 알려진 그의 GAN(Generative Adversarial Networks)은 인공지능, 즉 컴퓨터를 통해 세상에 존재하지 않는 이미지를 생성합니다. 이후 다른 연구진에 의해 발전된 다양한 GAN 기술은 보다 그럴듯하고 정교한 수준으로 가상의 이미지를 만들어 내고 있습니다.

2. Unsupervised Representation Learning with Deep Convolutional GAN(ICLR 2016)
3. Progressive Growing of GANs for Improved Quality, Stability, and Variation(ICLR 2018)
4. Analyzing and Improving the Image Quality of StyleGAN(CVPR_2020)
인공지능의 출발점을 Machine Learning(ML, 이하 머신 러닝)이라 정해보면, 컴퓨터가 주어진 데이터를 학습하고 스스로 그 특징을 찾아 적정한 작업을 수행하는 것으로 설명할 수 있는데요.
인공지능 학습법에 대해 잠시 알아보면, 기존 컴퓨터와 다르게 인공지능은 여러 가지 경험을 통해 패턴을 얻어내고 이를 기반으로 다음 행동에 영향을 주는 것이 바로 학습입니다. 예를 들면 ‘커피를 많이 마시면 잠을 설칠 수 있으니 줄여야겠다’와 같은 학습을 머신 러닝을 통해 수행하게 된 거죠.
흥미로운 점은, 많은 문제의 다양한 난이도와 해결 방법에 따라서 머신 러닝의 방식이 각각 다르다는 점입니다.
예를 들면, 문제에 따라 기계 즉 AI가 인간 선생님의 지도를 받아 학습을 할 수도 있고, 스스로 자율 학습을 할 수도 있게 되었습니다. 즉 문제의 성격에 따라 적용하는 머신 러닝 방법이 크게 지도 학습, 비지도 학습, 강화 학습으로 나누어집니다.
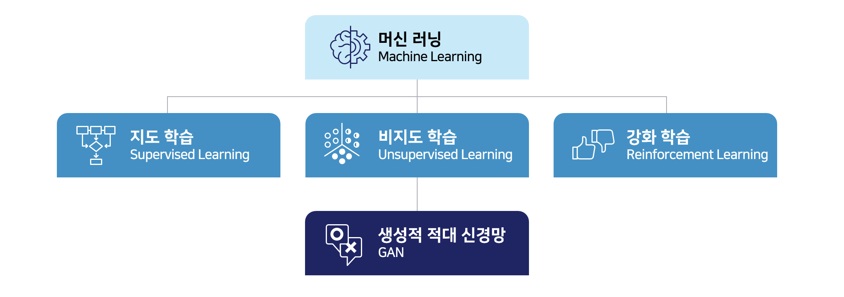
가장 먼저 알아볼 내용은 지도학습입니다. 지도학습은 정답이 주어진 상태에서 학습하는 알고리즘을 의미하죠. 예를 들어, 여러 장의 고양이와 기린 사진을 주고 각 사진이 고양이인지 기린인지 하나하나 정답을 알려줍니다. 그다음 어떤 사진을 주었을 때 고양이인지 기린인지 알아맞힐 수 있도록 하는 것이죠.
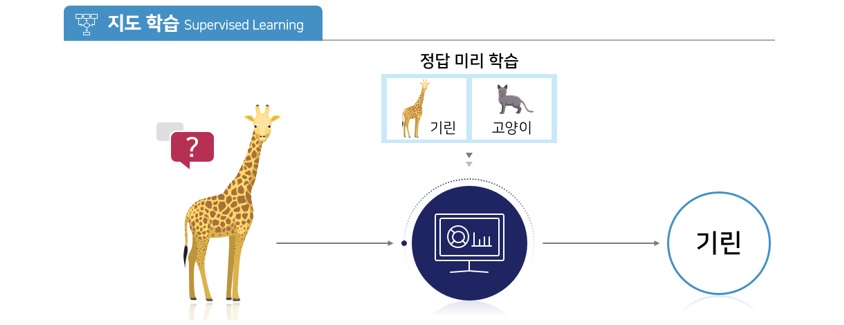
이번에는 비지도 학습에 대해 알아볼게요. 동물을 잘 모르는 사람에게 고양이와 기린으로 구성된 동물 사진들을 보여준다고 가정해 볼까요? 이때, 어떤 사진이 고양이고 어떤 사진이 기린인지 알려주지 않아도 사람들은 노랗고 얼룩무늬가 있고 목이 긴 동물과 그렇지 않은 동물로 구분할 수 있을 것입니다. 이렇게 하나하나 정답을 가르쳐주지 않아도 데이터의 특성, 즉 패턴을 파악해서 분류하는 것을 비지도 학습으로 분류하는데요. 이러한 비지도 학습의 가장 대표적 기술이 GAN입니다.
처음 GAN을 제안한 Ian Goodfellow는 GAN을 경찰과 위조지폐범 사이의 게임에 비유(3) 했습니다.
(3) Generative Adversarial Nets(Google Chrome, Microsoft Edge 브라우저 실행)
위조지폐범은 최대한 진짜 같은 화폐를 만들어(생성) 경찰을 속이기 위해 노력하고, 경찰은 진짜 화폐와 가짜 화폐를 완벽히 판별(분류)하여 위조지폐범을 검거하는 일을 목표로 세웁니다. 이렇게 경쟁적인 학습이 지속되다 보면 어느 순간 위조지폐범은 진짜 같은 위조지폐를 만들 수 있게 되고 경찰은 위폐와 실제 화폐를 구분할 수 없는 수준에 이르게 되겠죠?
여기서 경찰은 분류 모델, 위조지폐범은 생성 모델을 의미하며, GAN에는 최대한 진짜 같은 데이터를 생성하려는 생성 모델과 진짜와 가짜를 판별하려는 분류 모델이 각각 존재하여 서로 적대적으로 학습합니다. 이와 같은 학습과정을 반복하면 분류 Vs. 생성 모델이 서로를 적대적 경쟁자로 인식하여 모두 발전하게 되는데요. 결과적으로, 생성 모델은 진짜 데이터와 완벽히 유사한 가짜 데이터를 만들 수 있게 되고 이에 따라 분류 모델은 진짜 데이터와 가짜 데이터를 구분할 수 없게 됩니다. 즉, GAN은 생성 모델이 분류에 성공할 확률을 낮추려 하고, 분류 모델은 분류에 성공할 확률을 높이려고 노력하면서, 서로가 서로를 경쟁적으로 발전시켜 그 데이터 품질이 비약적으로 발전하는 구조를 이루고 있습니다.

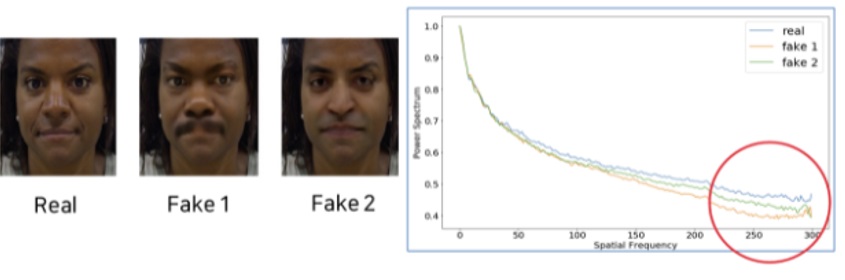
다음은 딥페이크 탐지 기법입니다. 현재까지 잘 알려진 딥페이크 탐지는 크게 3가지 기법이 있는데요, 첫째는 이미지 기반 탐지(Image based detection)입니다. 아래 아주머니 얼굴 머릿 부분, 자동차 앞 유리와 지붕 부분에 보이는 반점이 아티팩트(인공생성물)입니다.

두 번째는 신체 특징 기반 탐지(Physiological Features detection)입니다. 딥페이크 대상 중 사람 얼굴에서 관찰되는 혈색 변화, 눈 깜박임, 얼굴 그림자 등을 찾아내는 것인데요. 아래 맨 왼쪽 실제 사람의 사진과, 그 외 딥페이크에서 관찰되는 혈류 현상(Photoplethysmography, PPG)의 차이를 찾아내는 것입니다.

세 번째는 주파수 기반 탐지(Frequency based detection)입니다. 사진을 2차원 도메인이라고 보고, 이를 퓨리에 변환(Fourier Transform)을 통해 주파수 도메인으로 바꿉니다. 이후 그 사진을 다시 1차원 스펙트럼(Power Spectrum)으로 바꾸고 실제 사진과 딥페이크의 차이를 관찰하는 것입니다. 참고로 여기서 도메인은 인터넷 주소가 아닌 ‘특정 영역, 범위’라는 의미로 사용되었습니다.
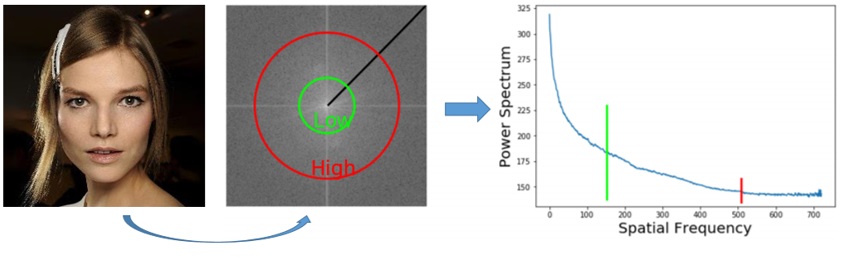
이제 실제 얼굴과 딥페이크의 스펙트럼을 보면, 고주파수 영역에서 명확하게 구분되는 차이가 나타나게 됩니다.
다음 시간에는 딥페이크(Deepfake)와 비슷하면서도 다른 칩페이크(Cheapfake)에 대해서 알아보겠습니다.
*본 연재 내용은 작성일 기준 공개된 객관적 연구 결과와 사실에 근거하여 작성되었지만, 회사의 방향과 다를 수 있음을 알려 드립니다.
+ AI를 활용한 멀티미디어 위변조에 대응하는 삼성SDS 사내벤처 팀나인

![]()