오픈소스를 활용한 쿠버네티스(Kubernetes) 기반 MLOps 플랫폼 도입
- 2022-06-30
- 작성자 박미경


최근 글로벌 리서치사의 조사에 따르면 많은 글로벌 기업들이 AI를 기업의 핵심 활동에 활용하고 있다고 합니다.
특히, 제품 개발, 서비스 운영 및 마케팅 영역에서의 사용이 활발하다고 하며,
이것은 실제로 많은 기업들이 AI 적용을 통해 업무 성과를 높이고 있다는 의미입니다.
AI에 대한 투자 및 성과 창출은 Tech 기업에 한정되어 있지 않고 전반적인 산업에 확산되어 있습니다.
그렇다면 성공적인 AI 적용을 위해 고려해야 할 점은 무엇인지 살펴 보겠습니다.
글로벌 기업들이 AI적용을 위해 고려해야할 점
기업에 AI 를 도입하는 글로벌 기업은 얼마나 될까?
맥킨지(McKinsey)가 글로벌 기업 대상으로 진행한 ‘The state of AI in 2020’ (20/11/17)에 따르면, 전체 응답자의 50% 이상이 AI를 기업의 핵심 활동에 활용하고 있다고 답하였습니다. 특히, 제품 개발 서비스 운영 및 마케팅 영역에서의 사용이 활발하다는 결과였습니다. 응답자66%는 AI 투자를 통해 기업의 레비뉴(Revenue)가 증가했다고 응답하였고, 22%는 기업 *EBIT에 5% 이상 기여했다고 밝혔습니다. 이것은 실제로 많은 기업들이 AI 적용을 통해 업무 성과를 높이고 있다는 의미입니다. 그 대상 기업들을 살펴보면 AI에 대한 투자 및 성과 창출이 Tech기업으로 한정된 것이 아니라, 전반적인 산업에 확산되어 있음을 알 수 있습니다.
* Earnings Before Interest and Taxes: 영업 및 세전 이익, 영업행위로 발생한 수익에서 비용을 차감한 것
성공적인 AI적용을 위해 고려해야할 것은?
그렇다면 성공적인 AI 적용을 위해 고려해야 할 것은 무엇인지 살펴 보겠습니다. 맥킨지는 AI 활용으로 최고의 성과를 내는 기업은 다른 일반 기업과 달리 AI 도입에 대한 경영진의 적극적인 지원과 기술적인 리더십을 갖추었다고 언급했습니다. 인력과 플랫폼에 대한 공격적인 투자를 바탕으로 개별적인 AI 애플리케이션 구입보다는 자사가 필요로 하는 AI 서비스의 내부적 개발은 물론, 전문 인력 확보와 표준화된 E2E(End-to-End) AI 플랫폼까지 도입하는 경향이 있다고 밝혔습니다. 여기서 AI 플랫폼은 AI 모델을 포함하여 여러 AI 서비스를 실행하는 기술 요소를 한곳으로 통합한 뒤 이를 조합하여 제공하는 플랫폼을 의미합니다.
AI 분야에서 상용 서비스 개발이 어려운 이유는?
현재 AI 분야는 AI 모델에 대한 알고리즘 및 최신 기술에 대한 연구가 빠른 속도로 활발히 진행되고 있습니다. 이런 속도를 효율적으로 반영한 상용 서비스만이 기업의 경쟁력이 될 수 있습니다. 그러나 이것은 그렇게 간단한 문제가 아닙니다. 개발된 AI 모델을 상품화하여 서비스로 운영하는 것이 AI 모델을 개발하는 것보다 더 어렵기 때문입니다. 실제로 개발된 모델의 80%가 버려진다는 조사 결과도 있습니다.※ 출처: https://www.roboticsbusinessreview.com/ai/almost-80-of-ai-and-mlprojects-have-stalled-survey-says/
이러한 결과의 가장 큰 원인은 AI 모델이 데이터 변화에 민감하다는데 있습니다. AI 모델에 대한 알고리즘 연구 당시에는 고정된 범위 내의 정제된 데이터를 사용하는 반면, AI 서비스 운영 시 제공되는 데이터는 외부의 환경적인 요소로 패턴이 변할 수도 있고, 연구 당시에 비해 품질이 떨어질 수도 있기 때문입니다. 따라서, 개발된 AI 모델을 바로 운영 서비스에 반영하기보다 반영 전에 실데이터를 수집하여 AI 모델에 대한 대규모의 훈련 과정과 튜닝이 필요합니다. 또한, 그 성능을 모니터링하고 지속적으로 쌓인 사용자 데이터를 반영한 AI 모델로 개선하는 것이 좋습니다. 방대한 데이터를 다루는 과정에서 발생하는 대규모 컴퓨팅(Computing : CPU/GPU, Memory) 및 스토리지(Storage) 자원 사용은 효율적인 데이터 관리와 인프라 관리가 필수적입니다. 한편, 모델 개발에 사용되는 다양한 ML(Machine Learning) 개발 언어와 툴 역시 지원할 수 있어야 합니다.
AI 서비스 개발 및 운영을 위해 고려해야 할 점은?
성능 좋은 AI 모델을 확보하는 것 이외에도 AI 서비스 개발 및 운영을 위해 고려해야 할 점은 더 있습니다. 빠른 추론 속도나 모델의 설명 가능성(Explainability, 모델이 내린 판단에 대한 설명 및 해석 가능성) 확보 등이 그것입니다. 여기서, 데이터 수집 → 모델 개발 및 실험 → 모델 훈련 및 최적화 → 배포 및 운영 등에 이르는 전 과정의 연결이 매우 중요합니다. 따라서 관련 부서 간의 유기적인 소통과 협업은 필수적인 요건입니다. 그러나 모델 개발을 주도하는 데이터 사이언티스트(Data Scientist)는 인프라 관리나 SW 개발을 잘 알지 못하고, AI 서비스의 IT 운영을 주도하는 ML Engineer는 AI 모델에 대한 이해가 어렵다는 문제가 있습니다.
그 외에도 데이터 엔지니어(Data Engineer)나 현업의 서비스 운영자인 비즈니스 프로덕트 오너(Business Product Owner)와 같은 다양한 부서와의 협업이 필요한데, 현실적으로 서비스의 신규 개발과 출시, 혹은 업데이트 시마다 서로 잘 모르는 영역과 R&R을 논의하는 것이 어려운 실정입니다.
MLOps가 필요한 이유는
이런 문제의 해결을 위해 도입된 기술이 MLOps입니다. MLOps는 파일럿 단계를 지나 AI 서비스를 상품화하는 단계에 필요한 프로덕션 엔지니어링 기술입니다. MLOps는 AI의 본격적인 적용 확산으로 최근 큰 주목을 받고 있습니다. 이 기술은 ML에 DevOps 원칙을 적용한 것으로, ML 시스템 개발(Dev)과 ML 시스템 운영(Ops)을 통합하는 것을 목표로 합니다. 이는 ML 엔지니어링의 문화이자 표준 절차 및 도구와 같은 방식 모두를 포함합니다. MLOps를 도입하면 모델 실험 및 개발을 쉽게 할 수 있습니다. 개발 환경과 컴퓨팅 자원을 제공하고 모델 훈련/최적화, 모델 평가/검증, 모델 배포/운영 및 인프라 관리에 이르기까지 모든 단계를 파이프라인으로 연결, 수행하고 그 과정을 모니터링 할 수 있습니다.
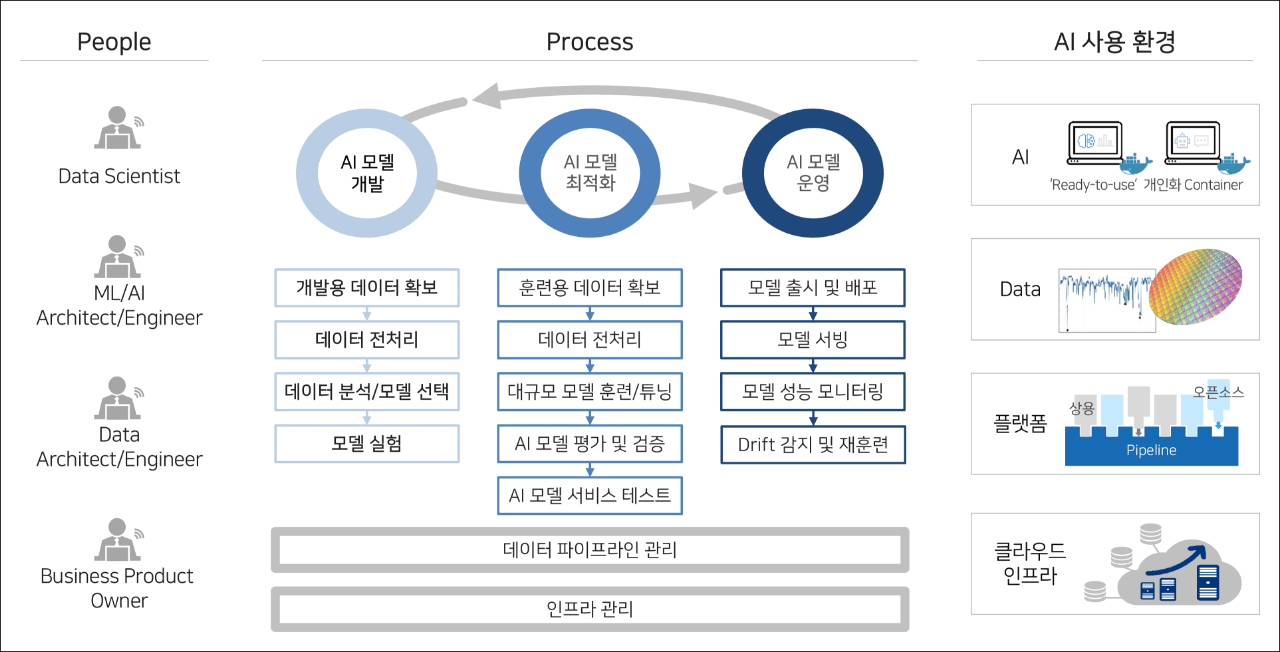
- Data Scientist
- ML/AI Architect/Engineer
- Data Architect/Engineer
- Business Product Owner
AI 모델 개발, AI 모델 최적화, AI 모델 운영 3가지가 순환 되는 그림
- 개발용 데이터 확보
- 데이터 전처리
- 데이터 분석/모델 선택
- 모델 실험
- 훈련용 데이터 확보
- 데이터 전처리
- 대규모 모델 훈련/튜닝
- AI 모델 평가 및 검증
- AI 모델 서비스 테스트
- 모델 출시 및 배포
- 모델 서빙
- 모델 성능 모니터링
- Drift 감지 및 재훈련
데이터 파이프라인 관리
인프라 관리
- AI 'Ready-to-use' 개인화 Container
- Data
- 플랫폼
- 클라우드 인프라
AI 분야에서 MLOps도입이 시급한 이유는
현재 MLOps 도입이 시급한 이유는 AI 분야에서 가장 큰 이슈 중 하나인 전문 인력 부족과 관련이 있습니다. 이는 데이터 사이언티스트(Data Scientist)의 부가적인 업무를 줄여 본연의 업무인 모델 개발에 집중할 수 있는 환경을 제공하기 위함과 동시에 ML Engineer가 운영 모델에 대한 지속적인 성능 관리 및 재학습을 잘 수행할 수 있는 환경을 지원받을 수 있기 때문입니다. 따라서 안정된 인프라와 자동화 시스템의 제공은 MLOps 도입의 주요 목표 중 하나입니다.
※ 출처 : https://cloud.google.com/architecture/mlops-continuous-delivery-andautomation-pipelines-in-machine-learning
가트너(Gartner)는 2025년까지 MLOps 시장 규모를 약 40억 달러로 전망하고 있습니다. 또한 2025년까지 기업의 50%가 AI 플랫폼을 도입할 것으로 예상했습니다. 이 중 50%가 상용 솔루션과 함께 오픈 소스를 활용할 것이라 예측했는데, 본문에서는 MLOps 대표 오픈소스인 쿠버플로우(Kuberflow)를 활용한 MLOps 기반의 AI 플랫폼 구축 및 도입에 대해 논의해 보겠습니다.
쿠버플로우 Kubeflow (Kubernetes + ML flow)란?
쿠버플로우는 구글(Google)이 자사 AI 개발의 노하우를 오픈 소스로 공개한 쿠버네티스 기반의 MLOps 플랫폼입니다. 모델 개발, 훈련, 배포 및 운영 등의 복잡한 ML 워크플로우 실행을 쿠버네티스에서 Simple, Portable, Scalable하게 지원합니다. 2018년 3월, 쿠버플로우 v1.0이 최초 출시된 이후, 3명으로 시작한 오픈 소스 프로젝트는 현재까지 Ant Group, AWS, Baidu, Bloomberg, Canonical, Cisco, Google, IBM/Redhat, Microsoft, Nvidia 등의 글로벌 Top 업체의 200여명이 넘는 개발자가 참여 중입니다. 오픈 소스 생태계는 급속히 확산되고 있습니다. 오픈 소스를 프로덕션 레벨로 사용하기 위해서는 제품의 성숙도 뿐 아니라 해당 오픈 소스의 사용자 커뮤니티 활성도를 고려해야 합니다. 쿠버플로우는 이 두 가지 모두를 충족하고 있습니다. 2021년 4월에 출시된 최종 버전은 v1.3이며, v1.4 출시를 앞두고 있습니다.
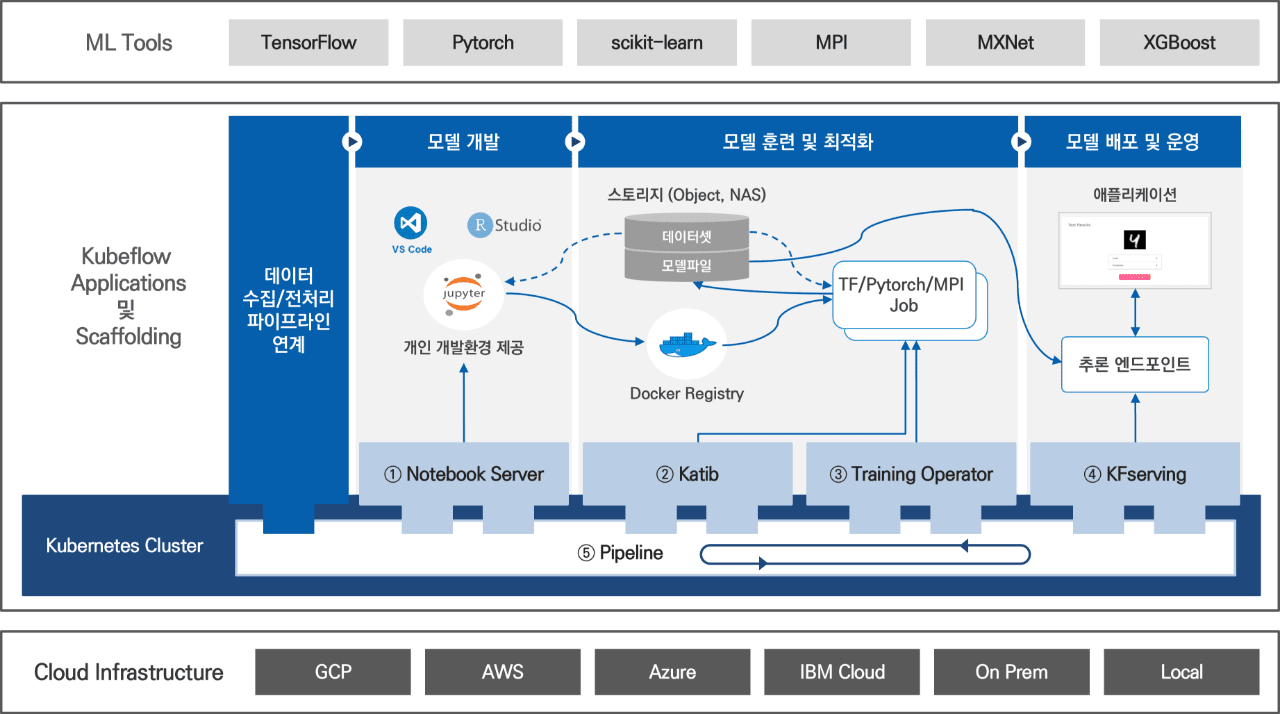
- ML Tools
- TensorFlow
- Pytorch
- scikiy-learn
- MPI
- MXNet
- XGBoost
| Kubeflow Applications 및 Scaffolding | 데이터 수집/전처리 파이프라인 연계 | 모델 개발 | 모델 훈련 및 최적화 | 모델 배포 및 운영 |
|
스토리지(Object, NAS)
Docker Registry TF/Pytorch/MPI Job |
애플리케이션 추론 엔드포인트 |
||
| 1.Notebook Server | 2.Katib, 3Training Operator | 4. KFserving | ||
| Kubernetes Cluster | Pipeline | |||
- Cloud Infrastructure
- GCP
- AWS
- Azure
- IBM Cloud
- On Prem
- Local
쿠버플로우(Kubeflow)의 주요 특징
쿠버플로우는 텐서플로우(Tensorflow), 파이토치(Pytorch) 등 ML 오픈 소스 생태계의 다양한 개발 언어 및 툴을 지원합니다.
쿠버플로우는 다양한 사용자의 요청 사항을 충족하는 ML 영역 별 최적의 오픈 소스 조합을 제공합니다. 대표적으로 텐서플로우, 파이토치 등 ML 오픈 소스 생태계의 다양한 개발 언어 및 툴 지원이 가능합니다. 또한, ML 개발용 Notebook Server, 하이퍼파라미터 튜닝 툴 Katib, 분산 훈련 작업 수행 Training Operator, 추론을 위한 모델 서빙 툴 KFServing 등과 더불어 핵심 ML 워크플로우 수행 툴 역시 제공받으실 수 있습니다. 전체 ML 워크플로우를 연결, 수행하고 모니터링 할 수 있는 강력한 파이프라인 툴은 워크플로우의 자동화와 더불어 생산성을 증대하고 유관 부서간의 협업을 지원합니다. 여기서 파이프라인의 개별 요소는 컨테이너를 기반으로 합니다. 가볍고 효율적이며 조립 가능한(컴포저블, Composable) 특징을 가진 컨테이너는 파이프라인의 개별 요소를 재사용하기 때문에 유연한 파이프라인 구성을 가능하게 합니다. 이러한 파이프라인의 활용은 빅데이터 레이크와 기업 데이터 관리 시스템의 연계, 데이터 수집과 모델 개발, 훈련, 배포 등의 운영까지 구현되기 때문에 E2E AI 플랫폼 구축이 가능합니다.
쿠버플로우는 막대한 연산 수행을 위해 쿠버네티스 기반의 대규모 분산 클러스터 환경을 제공합니다.
또한, 쿠버플로우는 대규모 데이터 처리 및 AI 모델의 막대한 연산 수행을 위해 쿠버네티스 기반의 대규모 분산 클러스터 환경을 제공합니다. 이를 통해 자원 요청 시 컴퓨팅(CPU/GPU) 및 스토리지 자원을 요청한 만큼 동적으로 할당하고, Auto Scaling을 통해 확장성 및 자동 복구 기반의 가용성을 보장합니다. 추가적으로 쿠버플로우는 손쉬운 분산 작업 수행을 위한 Job Operator와 이를 위한 효율적인 자원 관리 및 스케줄링을 제공합니다. 최적화된 개별적 개발 환경과 이식성(Portability)을 우선적으로 확보합니다. 플랫폼에서 동시에 개발 중인 개별 개발 환경은 다른 개발 환경과는 논리적으로 분리되어 있어 AI 개발자가 환경 문제에 신경 쓰지 않고 모델 개발에만 집중할 수 있습니다. 개발 환경은 그대로 운영 환경으로 배포 가능하며, 클라우드 사업자에 대한 종속성 없이 동일한 개발 환경을 사용할 수 있습니다. 그 외에도 자원에 대한 인증 및 권한 관리가 제공되며, 멀티 테넌시(Multi-tenancy)를 지원합니다.
쿠버플로우 기반 AI 플랫폼의 구성 요소는 무엇이 있을까요?
아래 도표와 같이, 쿠버플로우 기반 AI 플랫폼은 3가지 구성 요소로 이루어집니다.
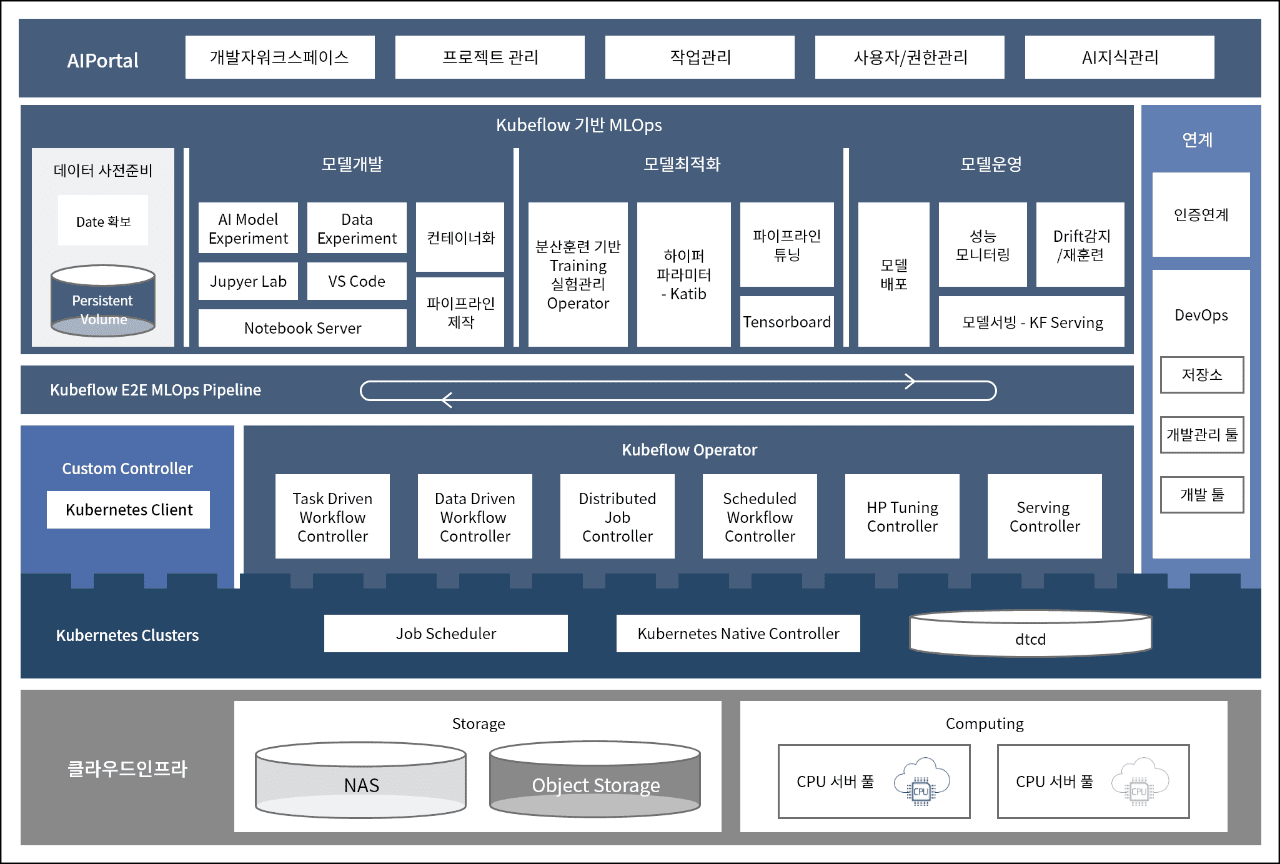
- AIPortal
- 개발자워크스페이스
- 프로젝트 관리
- 작업관리
- 사용자/권한관리
- AI지식관리
| Kubeflow 기반 MLOps |
연계
인증연계
|
|||||||||
|
데이터 사전준비 Date 확보 Perststent Volume |
모델개발 | 모델최적화 | 모델운영 | |||||||
| AI Model Experiment | Data Experiment | 컨테이너화 | 분산훈련 기반 Training 실험관리 Operator | 하이퍼 파라미터 - Katib | 파이프라인 튜닝 | 모델 배포 | 성능 모니터링 | Drift 감지/재훈련 | ||
| Jupyer Lab | VS Code | |||||||||
| Notebook Server | 파이프라인 제작 | Tensorboard | 모델서빙 - KF Serving | |||||||
| Kubeflow E2E MLOps Pipeline | ||||||||||
| Custom Controller | Kubeflow Operator | |||||||||
| Task Driven WorkFlow Controller | Data Driven Workflow Controller | Distributed Job Controller | Scheduled WorkFlow Controller | HP Tuning Controller | Serving Controller | |||||
| Kubernetes Clusters | Job Scheduler | Kubernetes Native Controller | dtcd | |||||||
- 클라우드인프라
-
Storage
- NAS
- Object Storage
-
Computing
- CPU 서버 풀
- CPU 서버 풀
ML Tools
ML 모델을 개발하기 위한 SW로 텐서플로우, 파이토치와 같은 DL(Deep Learning) 모델 전용 개발 툴과 scikit-learn과 같이 전통적인 ML 모델 개발 툴 모두를 지원합니다. 플러그인 형태이기 때문에 현재 지원 중인 툴 외에도 향후 더 많은 ML 툴의 지원이 예상됩니다.
Kubeflow Applications 및 Scaffolding
복잡한 ML 워크플로우를 지원하기 위한 구성입니다. ML 모델 개발과 원활한 운영을 위해 일반 사용자가 직접 사용하는 형태와 쿠버플로우의 핵심 기능이 잘 수행될 수 있도록 지원 하는 로깅, 모니터링, 인증 등의 형태로 구분됩니다.
Notebook Server
쿠버네티스 상에서 실행되는 파이썬(Python) 기반의 Jupyter Notebook/Jupyter Lab을 제공하는 툴로, 데이터 사이언티스트가 노트북으로 데이터 전처리와 모델 개발을 수행할 수 있습니다. v1.3부터는 VSCode 및 RStudio도 추가적으로 지원하고 있습니다.
Katib
Katib은 쿠버네티스 기반의 AutoML 툴로 하이퍼파라미터의 최적화(Hyperparameter Tuning)와 뉴럴 아키텍처 탐색(Neural Architecture Search)으로 나누어집니다. 하이퍼파라미터는 모델 훈련 과정을 제어하는 변수를 사용자가 직접 입력해 주어야 하는데, Katib을 사용하면 최적의 값을 찾아줍니다. 뉴럴 아키텍처 탐색은 인공 신경망을 디자인하기 위해 사용합니다.
Training Operator
모델을 훈련할 때 Training Operator를 사용하면 대규모 분산 훈련을 효율적으로 수행, 모니터링할 수 있습니다. 현재 쿠버플로우는 Tensorflow, Pytorch, MPI, MXNet 및 XGBoost 등을 지원합니다.
KFServing
모델 서빙은 애플리케이션에서 ML 모델을 사용하여 추론을 수행할 수 있도록 모델을 배포하는 것을 의미합니다. 쿠버플로우에서는 KFServing을 기본 서빙 툴로 제공하나, Seldon Core, Tensorflow Servnig, NVidia Triton Inference Server 및 BentoML 등의 다양한 툴도 함께 지원합니다.
Pipeline
쿠버플로우의 핵심 툴로, 컨테이너 기반의 E2E ML 워크플로우인 파이프라인을 만들고 배포할 수 있습니다. 작성된 파이프라인을 실행하면 단계별 필요 자원을 동적으로 할당하여 역할을 수행합니다. Spotify는 2019년 12월 파이프라인 도입을 통해 Data Scientist의 생산성이 700% 향상되었다고 밝힌 바 있습니다.
출처: https://engineering.atspotify.com/2019/12/13/the-winding-road-tobetter-machine-learning-infrastructure-through-tensorflow-extended-andkubeflow
Cloud Infrastructure
ML Workload를 수행하기 위한 컴퓨팅(CPU/GPU), 네트워킹 및 스토리지 자원을 제공하는 구성요소로 쿠버플로우는 쿠버네티스가 실행되는 모든 환경(Public Cloud, On-Prem, Local)에 설치가 가능합니다.

쿠버플로우 구현 사례 및 Lessons-learned
삼성SDS의 AI 개발 플랫폼 구축 현황과 장점은?
삼성SDS는 쿠버플로우 기반의 AI 개발 플랫폼을 모델 개발과 최적화 단계 중심으로 구축하였습니다. 이 플랫폼을 제품의 기능으로 사용 가능한 AI 모델 개발에 사용하고 있습니다. 이 경험으로부터 확보된 자산과 연구 결과를 토대로 현재 SCP(Samsung Cloud Platform)에서 제공하는 AI 플랫폼 구축과 개선을 진행하고 있습니다. 그와 동시에 온 프레미스(On-Premise) 형태로 고객을 위한 AI 플랫폼 구축 프로젝트도 수행하고 있습니다.
AI 모델 개발 단계와 모델 최적화의 단계는 추구하는 목표와 자원 활용 방식이 서로 다릅니다.
모델 개발과 모델 최적화의 단계는 추구하는 목표와 자원 활용 방식이 다릅니다. 때문에 플랫폼 구축 시 고려해야 할 사항도 달라집니다. 모델 개발은 성능 좋은 모델을 확보하기 위한 단계로, 이 과정의 목표는 개별 프로젝트에 소규모의 전용 자원을 할당하고 데이터 사이언티스트(Data Scientest)에게 사용하기 쉬운 환경을 제공하는 것입니다. 반면, 모델 최적화는 모델 개발 후 프로덕션 환경에 적용하기 위한 단계입니다. 이는 대규모 훈련과 튜닝 작업을 수행하기 때문에 대규모 공유 자원에 대한 효율적인 관리 및 스케줄링이 중요합니다.
인프라 구성은 SDS Kubernetes PaaS 기반으로 Nvidia의 최신 GPU인 A100을 도입하여 GPU Cluster를 확보하였습니다. NAS와 Object Storage는 SDS Cloud 제품을 활용했습니다. GPU Driver와 CUDA 버전이 맞지 않으면 GPU 미인식으로 AI 모델 실행이 불가하기 때문에 테스트를 거쳐 A100에 맞는 GPU Driver와 CUDA library 최적의 버전을 조합, GPU Cluster 전 Node에 설치하였습니다. 모델 개발 단계는 쿠버플로우의 Notebook Server 기반으로 구축하였는데, 달라진 점은 Data Scientist가 직접 개발 환경을 구성할 필요 없이 쿠버플로우가 제공하는 Notebook Server를 통해 노트북을 손쉽게 생성할 수 있다는 것입니다. 이때 필요한 만큼 사용할 자원(CPU, GPU, Memory, Storage)을 할당할 수 있습니다. 노트북 생성 시 노트북의 컨테이너 이미지 선택이 가능하기 때문에 전사 표준 개발 환경 및 원하는 개발 언어 등을 컨테이너 이미지로 제공받을 수 있습니다. 거기에 개인별로 특화된 개발 환경 역시 제공이 가능합니다.
삼성SDS AI 플랫폼 구축 시에는 전사 표준 개발 환경 이미지로 텐서플로우와 파이토치에 대해 CPU 및 GPU용 컨테이너 이미지가 각각 제공됩니다. GPU용 컨테이너 이미지의 경우, Single GPU 훈련뿐 아니라 Multi GPU 분산 훈련이 수행되는지 사전 테스트 검증을 마쳤습니다. 이런 과정을 거친 AI 개발 환경은 데이터 사이언티스트에게 시간 단축의 효과를 가져다 줍니다. 기존에 1주일 이상이 걸리는 AI 개발 환경 구축을 2~3분 이내에 마칠 수 있습니다. 삼성SDS 플랫폼은 AI Portal 구축을 통해 Git 연계, Custom 컨테이너 이미지 생성 및 관리 등, 데이터 사이언티스트가 노트북을 사용하여 손쉽게 모델 개발을 할 수 있는 환경을 제공합니다. 쿠버플로우에서는 제공하지 않는 부가 기능을 더해 편의성을 확보한 것입니다. 또한, AI 모델 개발 프로젝트 별로 Quota를 할당하여 Quota 내에서 프로젝트 구성원이 자율적인 자원 활용을 하도록 하였습니다. 최적화 단계에서는 Kubeflow Training Operator 및 Katib을 중심으로 자원 공유 툴을 확보하여 플랫폼을 구축하였습니다. 개발된 모델을 훈련할 때 Training Operator를 사용하면 효율적으로 대규모 분산 훈련을 수행할 수 있고 그 경과를 모니터링할 수 있습니다.
한편, ML 분산 훈련 작업의 경우에는 정교한 자원 관리가 필요합니다. 예를 들어, 분산 훈련의 작업 성공을 위해서는 작업에 속하는 모든 개별 작업이 동시에 실행되어야 하고, 전체 작업 수행에 필요한 자원이 충분히 확보될 때까지 기다려야 합니다. 이런 조건을 위해 Job Scheduler 오픈 소스인 Volcano가 쿠버플로우 v1.3부터 도입되었습니다. 볼케이노 스케쥴러(Volcano Scheduler)는 아래와 같은 성능과 효율을 기대할 수 있습니다.
생성 시간, 우선 순위 Class 등 우선 순위에 따른 작업 실행 순서 결정. (FIFO, priority)
동일 분산 훈련 작업에 속한 개별 작업을 단일 GPU Node에 할당하여 Network 병목 최소화. (Bin-packing)
볼케이노 스케쥴러(Volcano Scheduler)의 효율적인 사용을 위한 노하우는?
볼케이노 스케쥴러(Volcano Scheduler)의 효율적 사용을 위한 특별한 노하우가 있습니다. 바로, Gang, Bin-packing 등 해당 Scheduler가 제공하는 스케줄링 정책과 자원 Queue의 적절한 조합을 찾는 것입니다. 여기서 자원 Queue는 관리하고자 하는 자원의 묶음입니다. Queue는 제 각각 스케줄링 정책을 결정할 수 있으며, 자원 Queue 구성이 플랫폼 전체 자원의 활용과 작업 효율성에 직접적인 영향을 미칩니다. 쿠버플로우의 Training Operator와 Katib 사용을 위해서는 모델 훈련 코드를 컨테이너 이미지로 만들어야 합니다. 쿠버플로우는 Fairing이라는 툴을 통해 이를 지원합니다.
삼성SDS AI 플랫폼의 특별한 기능
삼성SDS 플랫폼은 데이터 사이언티스트의 편의를 위해 사용하던 노트북 이미지 그대로 훈련 작업과 하이퍼파라미터 튜닝 작업을 진행할 수 있는 기능을 추가하였습니다. 데이터 사이언티스트가 노트북으로 모델 개발을 진행할 때 필요한 라이브러리와 툴을 추가적으로 설치하는 것이 일반적이기 때문입니다. 한편, Training Operator를 사용하면 분산 훈련 작업 관리가 다소 용이하지만, 데이터 사이언티스트가 직접 작업을 실행하기에는 여전히 어려운 점이 있습니다. 이를 개선하기 위해 분산 훈련 작업 실행 UI와 Training Operator, Katib, 노트북 등 전체 현황을 모니터링하는 통합 모니터링 UI를 제공하고 있습니다. 이때 관리자가 병목을 일으키는 작업을 찾아서 진행을 임의로 중단할 수 있습니다.
위에서 언급한 내용 외에도 언급할 사항이 많지만, 지면 상의 어려움으로 파이프라인의 중요성을 되짚는 것으로 이 글을 마무리하고자 합니다.
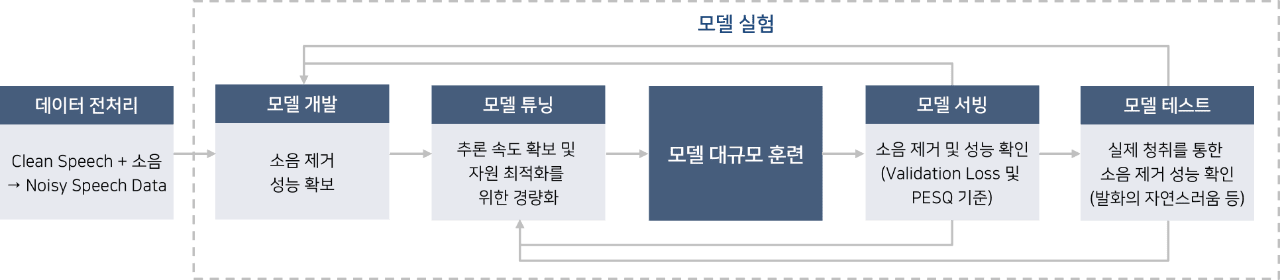
-
데이터 전처리
clean Speech + 소음, Noisy speech Data
-
모델 개발
소음 제거 성능 확보
-
모델 튜닝
추론 속도 확보 및 자원 최적화를 위한 경량화
- 모델 대규모 훈련
-
모델 서빙
소음 제거 및 성능 확인 (Validation Loss 및 PESQ 기준)
-
모델 테스트
실제 청취를 통한 소음 제거 성능 확인 (발화의 자연스러움 등)
쿠버플로우 파이프라인의 중요성
필자는 작년 하반기부터 MLOps 기반 AI 플랫폼 구축 프로젝트 외에 소음 제거를 위한 AI 모델 개발에 참여했습니다. Production 적용을 위한 모델 개발은 무한한 반복 작업입니다. 모델 개발 단계에서는 다수의 소음 제거 알고리즘 후보와 규모, 소리 등의 반향 정도에 따른 데이터셋 조합의 모델 실험을 반복적으로 수행합니다. 그리고 모델 중에서 소음 제거 성능이 가장 좋은 것을 프로덕션에 적용할 후보로 정하게 됩니다. 그런데 소음 제거 모델은 핸드폰이나 PC에 적용할 모델이기 때문에 Production 적용에 맞는 추론 속도와 추론 시 활용할 자원의 사용량이 중요해 집니다. 즉, 모델 성능이 다소 떨어지더라도 추론 속도가 빠르고 자원 사용량이 적은 모델을 선택하게 되는 것입니다. 다양한 모델 경량화 기법을 사용하여 후보 모델을 도출하고, 모델 성능 검증을 통해 최종 모델이 선택됩니다.
이때 모델을 제공하는 입장에서는 *Validation Loss나 *PESQ와 같은 정량적인 수치를 통해 모델 성능을 확인합니다. 그러나 실제 모델을 활용할 때는 청취를 통해 소음 제거로 인한 부작용 즉, 발화의 자연스러운 정도 등의 정량적인 기준으로 모델을 확정하게 됩니다.
이 과정에서 모델 후보, 관련 데이터셋, 테스트 결과 등의 모델 실험 관리를 수동으로 실행하면 생산성이 떨어지는 것은 자명합니다. 쿠버플로우는 파이프라인 툴을 통해 모델 실험을 자동으로 수행하고 모델 실험 내용을 관리해 줍니다. 삼성SDS 구축 사례에서 생산성을 측정하지는 못했지만, 앞서 언급한 바와 같이 Spotify는 Kubeflow Pipeline 도입을 통해 700%라는 엄청난 생산성 향상을 이루어 냈습니다. 국내에서는 당근마켓 등에서 Kubeflow Pipeline을 도입하여 효율적으로 활용하고 있습니다. 다만, Kubeflow Pipeline을 사용하기 위해서는 파이프라인 단계별 사용 요소를 컨테이너 이미지로 준비해야 하고, 단계별로 필요한 자원에 대한 별도의 설정을 해야 하는 등 파이프라인 제작이 사용자에게 다소 어렵기 때문에, 자사에서는 Kubeflow Pipeline을 좀더 편안하게 제작할 수 있도록 기능 향상을 진행하고 있습니다.
* 훈련용 데이터셋이 아니라 별도의 검증용 데이터셋을 활용하여 모델 성능을 평가한 수치
* Perceptual evaluation of speech Quality
삼성SDS 가 ML E2E 워크플로우를 효율적으로 지원하는 방법
이와 같이 삼성SDS에서는 쿠버플로우 기반 MLOps 플랫폼 제공을 통해 모델 개발, 훈련, 배포 및 운영 등 복잡한 ML E2E 워크플로우 실행을 효율적으로 지원하고 있습니다. 그리고 데이터 사이언티스트를 포함한 사용자들에게 친화적이고 Enterprise Level의 AI 개발을 지원할 수 있도록 끊임없이 노력하고 있습니다.
- 박미경 프로 / 삼성SDS
- 유통·서비스, 제조, 공공 업종의 삼성 관계사와 일반 기업 고객을 대상으로 현재 Cloud Native 기반의 MLOps/AI 분야를 리딩하고 있으며 18년간의 신기술 중심 솔루션 개발 및 프로젝트 수행에 대한 경험과 전문성을 보유하고 있습니다.