클라우드에서 더욱 중요한! 작업 스케줄링(Job Scheduling)은 무엇인가?
- 2022-09-30
- 작성자 이창주


작업 스케줄러(Job Scheduler)는 클라우드 내에서 여러 개의 작업(job)이 요청되었을 때 한정된 자원을 효율적으로 배분하여 사용자의 작업이 원활히 수행되도록 도와주는 역할을 합니다. 삼성SDS는 Gang Scheduler, Bin-Packing Scheduler, FIFO Scheduler, Multi-Queue Scheduler 등 다양하고 효율적인 스케줄러 기술을 확보하여 사용자들에게 제공하고 있습니다. 뿐만 아니라 ML/DL 작업 시간을 예측하여 스케줄링 하는 예측 기반 Backfill Scheduler를 연구/개발하고 있습니다. 삼성SDS가 확보한 스케줄러 기술들과 연구/개발한 스케줄러에 대해 살펴보겠습니다.
작업 스케줄러(Job Scheduler)란?
작업 스케줄러(Job Scheduler)는 클라우드 내에서 여러 개의 작업(Job)이 요청되었을 때 그것을 효과적으로 할당해주고 순서를 정해주는 방법입니다. 예를 들어 GPU(Graphic Processing Unit) 4개가 필요한 Job A를 작업할 때, 작업 스케줄러(Job Scheduler)는 효율성을 극대화하기 위해 GPU 4개가 사용 가능한 서버에 Job A를 할당할 것입니다. 만약, GPU 2개만 사용 가능한 서버에 해당 작업을 할당했다면 그 작업은 수행되지 않을뿐더러 GPU 2개를 점유했기 때문에 오히려 효율성이 떨어지게 됩니다. 반대의 경우도 마찬가지입니다. GPU 4개가 필요한 작업을 GPU 8개의 서버에 할당하면 GPU 4개는 유휴 자원이 되므로 이 역시 효율성이 떨어지게 됩니다. 이와 같이 작업 스케줄러(Job Scheduler)는 클라우드에서 사용자의 원활한 작업을 지원하고 한정된 자원의 효율적 배분을 가능하게 해 줍니다.
[여기서 잠깐!] 작업 스케줄링(Job Scheduling) 이란?
작업 스케줄링은 시스템의 전반적인 효율성과 효과적인 운영을 최적화하기 위해 작업 또는 작업을 사용 가능한 자원에 할당하는 과정입니다. 컴퓨터 과학에서 작업 스케줄링은 CPU 시간, 메모리 및 디스크 공간과 같은 시스템 리소스를 경쟁하는 다른 프로세스 또는 응용 프로그램에 할당하는 데 일반적으로 사용됩니다.
딥 러닝 작업 스케줄링(Deep Learning Job Scheduling)이란?
딥 러닝 작업 스케줄링은 사용자의 작업 요청을 적절하게 할당함으로써 GPU의 사용률을 향상시키고 한정된 자원으로 효율적인 서비스를 제공하는 기술입니다.
AI 기술의 활용도가 높아짐에 따라 GPU 자원의 사용량도 증가하고 있습니다. 하지만 한정된 GPU 자원을 효율적으로 사용하기 위해서는 적절한 스케줄링 기법이 필요합니다.
이에 따라 삼성SDS는 Gang Scheduler, Bin-Packing Scheduler, FIFO Scheduler, Multi-Queue Scheduler 등 다양하고 효율적인 스케줄러 기술을 확보하였고 이를 사용자, 특히 연구원 및 데이터 사이언티스트들에게 제공하고 있습니다. 뿐만 아니라, ML/DL(Machine Learning/Deep Learning) 작업 시간을 예측하여 스케줄링 하는 예측 기반 Backfill Scheduler를 연구/개발하고 있습니다. 먼저, 삼성SDS에서 확보한 기술들을 간략하게 살펴보겠습니다.
삼성SDS에서 확보한 작업 스케줄러기술의 종류
1) Gang Scheduler
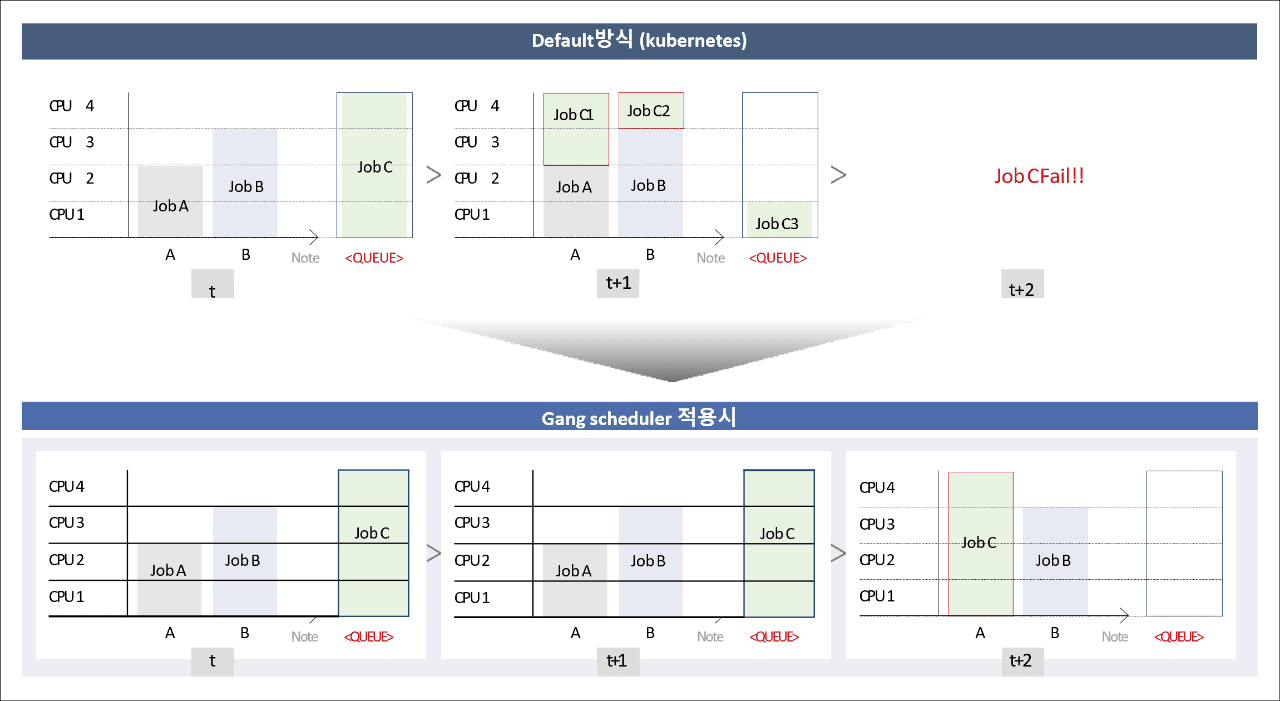
Scheduler는 작업을 수행할 수 있는 곳에 작업을 할당하는 것이 핵심입니다. 이때 중요한 기술 중의 하나가 Gang Scheduler 입니다. 이 기술은 단일 ML/DL 작업 수행에 필요한 리소스인 GPU, CPU, Memory 등이 모두 확보되었을 때 스케줄링을 통해 GPU의 효율성을 높여줍니다. 도표로 쉽게 설명하자면 아래와 같습니다. 기존 Scheduler는 Job C가 대기열에 있을 때, 얼만큼의 리소스가 필요한지 고려하지 않고 작업을 나누어 수행합니다. 그 결과 작업 수행이 실패하게 되는데, Gang Scheduler의 경우 빈 GPU가 있더라도 수행 가능 여부를 먼저 판단하고 수행 가능한 리소스 확보를 확인한 후 들어가기 때문에 작업을 성공적으로 수행할 수 있습니다.
2) Bin-Packing Scheduler
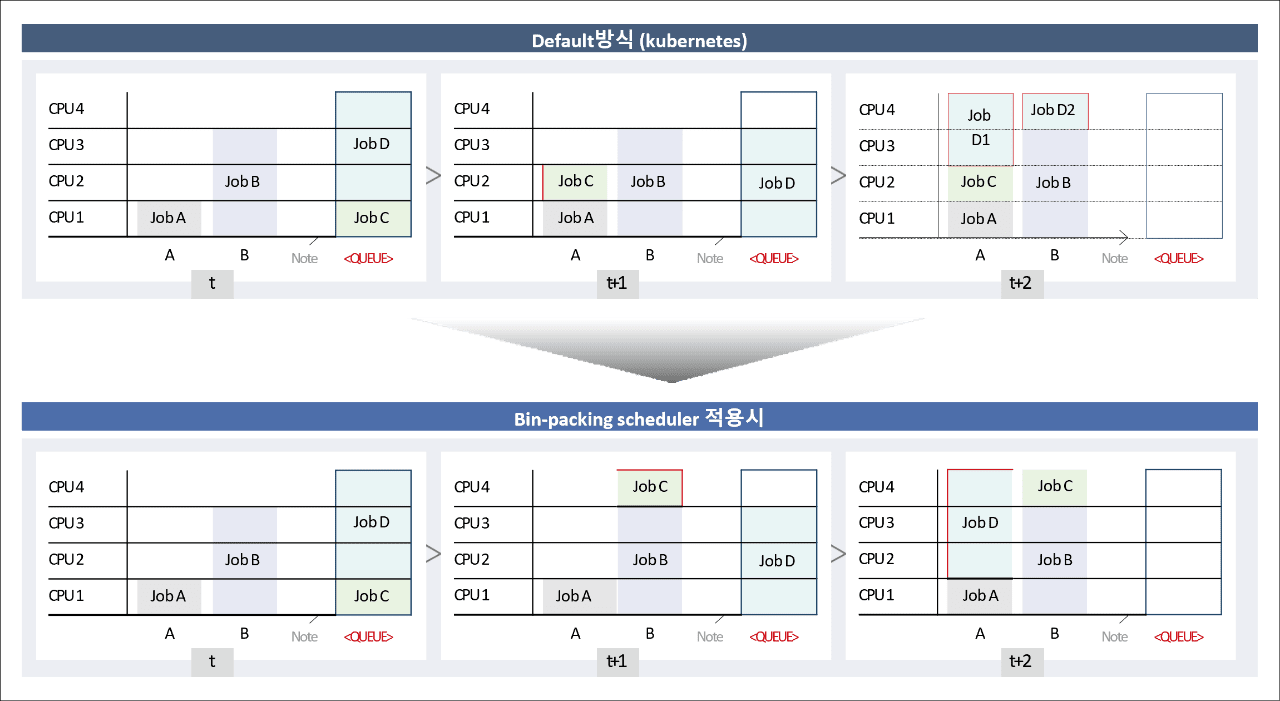
Bin-Packing Scheduler는 GPU 사용률에 긍정적인 기여를 할 수 있습니다. 분산 학습 작업의 경우, 여러 대의 GPU를 활용해 작업을 수행하는 경우가 많기 때문입니다. 또한, 사용하는 GPU를 최대한 한곳에 몰아 작업함으로써 작업 성공률도 높이고, 네트워크 속도로 인한 지연도 최소화하는 스케줄링 방법이라 할 수 있습니다.
위 도표에 따르면, 기존 Scheduler의 경우 한 곳에 배정하는 것을 고려하지 않기 때문에 Job D가 2개의 노드로 나뉘어 실행되는 것을 볼 수 있습니다. 이는 데이터를 양쪽으로 주고받아야 하기 때문에 작업 수행 속도가 떨어지고 오랜 시간 동안 GPU를 사용하여 효율성이 크게 떨어집니다. 반면, 아래 Bin-Packing Scheduler를 보면, 한 곳으로 작업 배정이 고려되기 때문에, Job D가 모두 한 곳에서 작업 수행이 되어 수행 시간을 줄이는 효과를 볼 수 있습니다. 같은 시간 동안 더 많은 작업을 실행할 수 있으므로 GPU 사용률 또한 향상시킬 수 있습니다.
-
Default방식 (Kubernetes) t 표 CPU 4 job C CPU 3 job B CPU 2 job A CPU 1 A B Note <QUEUE> -
Default방식 (Kubernetes) t+1 표 CPU 4 job C1 job C2 CPU 3 job B CPU 2 job A CPU 1 job C3 A B Note <QUEUE> -
Job CFail!!
t+2
-
Gang scheduler 적용시 t 표 CPU 4 job C CPU 3 job B CPU 2 job A CPU 1 A B Note <QUEUE> -
Gang scheduler 적용시 t+1 표 CPU 4 job C CPU 3 job B CPU 2 job A CPU 1 A B Note <QUEUE> -
Gang scheduler 적용시 t+2 표 CPU 4 job A CPU 3 job B CPU 2 CPU 1 A B Note <QUEUE>
-
Default방식 (Kubernetes) t 표 CPU 4 job D CPU 3 job B CPU 2 CPU 1 job A job C A B Note <QUEUE> -
Default방식 (Kubernetes) t+1 표 CPU 4 CPU 3 job B job D CPU 2 job C CPU 1 job A A B Note <QUEUE> -
Default방식 (Kubernetes) t+2 표 CPU 4 jab D1 job D2 CPU 3 job B CPU 2 job C CPU 1 job A job A B Note <QUEUE>
-
Bin-packing scheduler 적용시 t 표 CPU 4 job D CPU 3 job B CPU 2 CPU 1 job A job C A B Note <QUEUE> -
Bin-packing scheduler 적용시 t+1 표 CPU 4 job C CPU 3 job B job D CPU 2 CPU 1 job A A B Note <QUEUE> -
Bin-packing scheduler 적용시 t+2 표 CPU 4 job D job C CPU 3 job B CPU 2 CPU 1 job A A B Note <QUEUE>
3) FIFO(First In First Out) Scheduler
FIFO Scheduler는 사용자의 요청 순서대로 작업을 처리해주는 스케줄러입니다. 이 스케줄러는 요청 순서에 따라 자원 배정이 되기 때문에 GPU의 효율성은 떨어지지만 작업 순서를 보장함으로써 공정성 측면에서의 만족도가 매우 높습니다. FIFO Scheduler의 사용 빈도가 높은 이유입니다. 도표를 참고하면, FIFO Scheduler는 작업이 요청된 순서대로 자원을 배정해 주지만 많은 GPU가 유휴자원이 되는 것을 볼 수 있습니다. 특히, Job 2와 Job 4의 경우 요청한 GPU의 수가 많기 때문에 Queue에 병목 현상이 발생하고 유휴 GPU 개수는 많아집니다.
현재 삼성SDS는 유휴 GPU를 줄이기 위한 방법으로 Multi-Queue Scheduler를 확보하여 사용하고 있습니다. 또한 수행 시간 예측 기반 Backfill Scheduler의 연구를 통해 작업 수행시간을 예측하고 유휴 자원과 맞는 작업을 배정하는 스케줄링을 준비하고 있습니다.
4) Multi-Queue Scheduler
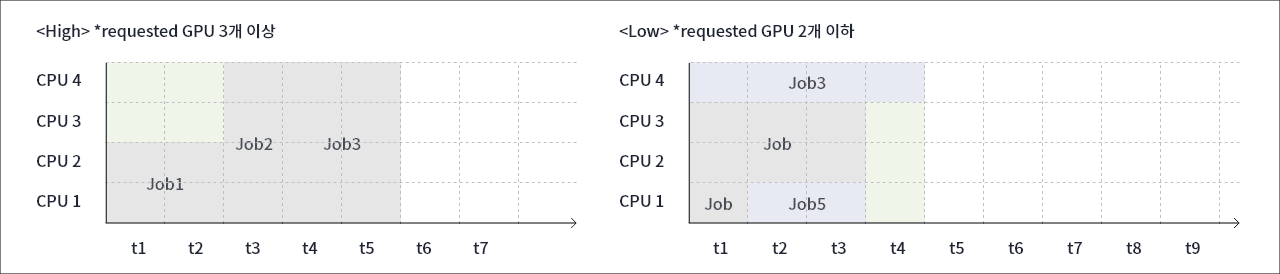
Multi-Queue Scheduler는 GPU 요청량이 많은 작업과 적은 작업을 분류하여 스케줄링 하는 방법입니다. 이 방법은 요청 자원이 많은 작업이 발생시키는 병목 현상을 줄일 수 있게 구성되어 유휴 GPU 개수가 줄고 이로 인해 GPU 효율성을 높입니다. 도표와 같이 요청된 GPU가 3개 이상일 때의 'High' Queue와 2개 이하일 때의 'Low' Queue를 따로 만들어 운영하므로 유휴 GPU의 개수를 줄일 수 있습니다.
Multi-Queue Scheduler의 또 다른 장점은 대기 중인 작업의 특성을 파악하는 것입니다. 자원 요청량이 많은 작업이 몰릴 경우 'High' Queue로 더 많은 GPU를 배정하여 GPU의 효율성을 높여줍니다.
실제 Multi-Queue를 적용한 결과 기존의 FIFO Scheduler 대비 작업 평균 대기시간이 32.3시간에서 5.77시간으로 줄었고 GPU 사용 효율성 역시 20% 향상되었습니다. GPU 사용 효율성은 100개의 GPU가 100시간 운영되었다고 생각할 때, 얼마나 많은 시간 유휴 GPU가 생겼는지 보는 수치입니다. 100개의 GPU가 100시간 모두 운영되었다면 100%, 총 40개의 GPU가 50시간 동안 유휴 자원이 되었다고 하면 80% 입니다.

- Running
- Waiting
- Unused
| CPU 4 | job 2 | job 4 | |||||||||||||
| CPU 3 | job |
job | job 1 | ||||||||||||
| CPU 2 | |||||||||||||||
| CPU 1 | job 3 | job5 | |||||||||||||
| t1 | t2 | t3 | t4 | t5 | t6 | t7 | t8 | t9 | t10 | t11 | t12 | t13 | t14 | t15 | |
-
hight : requested GPU 3개 이상 CPU 4 job 2 job 3 CPU 3 CPU 2 job 1 CPU 1 t1 t2 t3 t4 t5 t6 t7 -
Low : requested GPU 2개 이하 CPU 4 job 3 CPU 3 job job CPU 2 CPU 1 job 5 t1 t2 t3 t4 t5 t6 t7 t8 t9

| CPU 4 | job 2 | job 6 | job 10 | ||||||||||||
| CPU 3 | job |
job | job 8 | ||||||||||||
| CPU 2 | job 9 | job 11 | job 1 | job 2 | |||||||||||
| CPU 1 | job 7 | job 12 | |||||||||||||
| t1 | t2 | t3 | t4 | t5 | t6 | t7 | t8 | t9 | t10 | t11 | t12 | t13 | t14 | t15 | |

| CPU 4 | job 8 | job 2 | job 12 | job 4 | job 6 | ||||||||||
| CPU 3 | job |
job | job 1 | job 10 | job 5 | ||||||||||
| CPU 2 | job 3 | ||||||||||||||
| CPU 1 | job 9 | ||||||||||||||
| t1 | t2 | t3 | t4 | t5 | t6 | t7 | t8 | t9 | t10 | t11 | t12 | t13 | t14 | t15 | |
삼성SDS에 확보된 스케줄러, 스토리지, 데브옵스(DevOps) 등의 기술들은 복잡한 ML/DL의 편리를 최대로 높이는 동시에 가격 부담은 줄여줄 것입니다.
삼성SDS 연구소에서 연구, 개발한 스케줄러(Scheduler) 소개
ML/DL(Machine Learning/Deep Learning)의 작업 수행 시간 예측
현재 삼성SDS에서는 ML/DL의 작업 수행 시간을 예측하기 위해 각 작업의 계산량을 구하여 합하는 연산량 기반의 예측 모델을 확보 하였습니다. 또한, 각각의 케이스 별 수행 시간을 측정하여 데이터를 축적한 후 이를 기반으로 예측하는 데이터 기반의 예측 모델을 확보하여 연구/개발 하고 있습니다. 연산이 복잡하고 사용하는 GPU의 기종, 개수, 네트워크 환경 등에 따라 같은 연산량이더라도 수행 시간이 다를 수 있습니다. 때문에 연산량 기반의 모델과 데이터 기반의 모델을 취합하여 수행 시간의 예측 정확도를 높이는 연구 역시 진행하고 있습니다.
수행 시간 예측 기반 Backfill Scheduler
수행 시간 예측 기반 Backfill Scheduler는 ML/DL 작업 수행 시간을 예측하여 이를 기반으로 유휴 자원을 활용하는 스케줄링 방법입니다. 기존의 FIFO Scheduler의 문제점이었던 유휴 GPU를 활용할 수 있다는 장점이 있습니다. 따라서 GPU의 사용 효율성과 사용자의 공정성을 모두 확보할 수 있습니다. 이때, ML/DL 작업의 수행 시간 예측이 매우 중요합니다. 시간을 고려하지 않고 현재 시점의 유휴 자원만 고려하여 스케줄링 할 경우 요청 자원이 적은 작업만 우선적으로 처리되고 요청 자원이 큰 작업의 대기 시간은 늘어나기 때문입니다. 이에, 삼성SDS는 수행 시간 예측 기반 Backfill Scheduler를 연구/개발하여 사용자의 편의성과 GPU 효율성을 높이도록 노력하고 있습니다.
Backfill Scheduler의 자원 배정 및 수행 시간 예측 기반 방법 비교
첫 번째 도표는 기존의 Backfill Scheduler의 자원 배정 방법이고, 두 번째 도표는 수행 시간 예측 기반 Backfill Scheduler의 자원 배정 방법입니다. 기존의 Scheduler의 경우 가용 자원이 발생할 때마다 GPU 1개를 요청한 작업을 수행시켜 자원 요청량이 적은 Job 6, Job, Job 8, Job 9, Job 10, Job 11, Job 12 등이 수행되고 먼저 요청되었던 Job 1, Job 2 등의 작업 수행 시작 시간은 연기된 것을 볼 수 있습니다. 반면, 수행 시간 예측 기반 Backfill Scheduler는 기존의 FIFO 스케줄링 방식에서 발생되는 유휴 자원과 시간을 고려하여, 해당 상황에 알맞은 작업만을 배정합니다. 즉, 기존의 Job 1, Job 2, 등의 작업 시간 시작에는 영향을 주지 않았다는 의미입니다. 이렇게 수행 시간 예측 기반 Backfill Scheduler는 사용자의 작업 순서를 보장하면서도, 그 사이에 발생하는 유휴 자원을 활용하기 때문에 사용자의 만족도와 GPU 효율성 증가라는 두 마리 토끼를 모두 잡을 수 있는 기회를 만듭니다.
ML/DL에 최적화 서비스를 제공하는 삼성SDS
현재 삼성SDS는 A.I. 시대에 맞춰 ML/DL(Machine Learning/Deep Learning)에 최적화된 클라우드 서비스를 제공하고 있습니다. 삼성SDS에 확보된 Scheduler, Storage, DevOps 등의 기술들은 복잡한 ML/DL의 편리를 최대로 높이는 동시에 가격 부담은 줄여줄 것입니다. 거기에, 스케줄러 기술은 클라우드 환경에서 한정된 GPU 개수로 최대의 효율성을 발휘하여 사용자의 대기 시간을 줄이면서도 공정성을 확보할 것입니다. 사용자의 만족도를 높여주는 삼성SDS의 기술, 지금 준비되어 있습니다.
기업을 위한 진정한 클라우드 서비스, 삼성 클라우드 플랫폼 (Samsung Cloud Platform, SCP)에서 AI서비스에 대해 더 알아볼까요?
삼성 클라우드 플랫폼 (Samsung Cloud Platform, SCP) 바로가기 >
삼성 클라우드 플랫폼 (Samsung Cloud Platform)에서 AI/ML 상품을 만나보세요.
-
AI/ML
쉽고 편리하게 ML/DL 모델 개발 및 학습 환경을 구축할 수 있는 AI 서비스
- 이창주 프로 / 삼성SDS
- 금융 시계열 데이터 모델링, 블록체인 플랫폼 설계 등의 경험을 바탕으로 연구소에서 데이터 기반 딥러닝 모델링을 활용하여 효율적이고 사용하기 편한 스케줄러 개발을 위한 연구를 하고 있습니다.