[IT에 한 걸음 더 다가가기] 연산처리의 성능 한계에 도전하는 병렬컴퓨팅 (2편)

지난 편에서는 컴퓨터 성능 향상의 역사와 병렬 컴퓨팅의 배경 및 의미에 대해서 살펴보았습니다. 이제 본격적으로 여러 개의 연산을 동시에 병렬적으로 처리함으로써 컴퓨터의 성능을 극대화하기 위한 병렬 컴퓨팅, 이에 사용되는 다양한 기법에 대해, 2편과 3편에 나누어 연재하려고 합니다.
컴퓨터 CPU는 연산을 처리하기 위해 ALU, Control Unit 등의 다양한 장치로 이루어져 있으며, 이러한 핵심 부품을 코어라고 합니다. 코어가 하나인 구조를 싱글코어라고 하며 싱글코어를 모아 다수로 구성하면 멀티코어가 됩니다. 이번 편에서는 싱글코어에 적용되는 하드웨어 수준의 병렬 컴퓨팅 기법에 대해 살펴보고, 이후 3편에서는 싱글코어의 여러 한계를 극복하면서 등장하게 된 멀티코어 프로세서의 병렬 컴퓨팅 기법을 알아보도록 하겠습니다.
제 2편 : 병렬 컴퓨팅의 다양한 기법I
제 3편 : 병렬 컴퓨팅의 다양한 기법II
제 4편 : 병렬 컴퓨터
제 5편 : 병렬 프로그래밍
제 6편 : 병렬컴퓨팅의 미래와 전망
싱글코어에서는 하드웨어 수준의 비트나 명령어를 병렬처리함으로써 성능을 향상시켜 왔으며, 멀티코어 시대에서는 이에 더하여 다수의 코어를 이용하는 스레드(thread) 수준의 병렬처리 기법으로 발전하게 됩니다.
컴퓨터의 CPU는 아날로그처럼 연속적인 수를 인식하거나 처리하기가 힘들기 때문에 ‘0’, ‘1’ 두 가지 상태만을 이용하여 자료를 표현해 냅니다. CPU에서는 이러한 2진 데이터를 처리하는 단위를 word라고 하는데, 한 번의 명령으로 얼마나 많은 word를 처리할 수 있느냐가 성능의 중요한 척도가 됩니다. 즉, 한 번에 처리되는 word량을 늘리기 위해 버스의 대역폭을 늘리고 레지스터나 메모리와 같은 장치의 용량을 넓히는 방법을 사용할 수 있는데, 이러한 기법을 비트 수준의 병렬처리라고 합니다.
마이크로 아키텍처의 연산처리 기본단위가 되는 명령어를 대상으로 하며 다수의 명령어들을 동시에 수행하기 위한 기술을 명령어 수준 병렬처리라고 합니다. 여기에서는 파이프라이닝(pipelining), 비순차 실행, 데이터 병렬처리 등을 다루어 보겠습니다.
파이프라이닝(pipelining)은 마이크로 아키텍처의 가장 고전적인 성능 향상 기법으로, 명령어를 단계별로 나누어 한 단계씩 순차적으로 진행함으로써 명령어가 마치 동시에 실행되는 것처럼 하여 처리 성능을 높이는 기법입니다. 파이프라이닝에 대한 예를 말씀드리기 전에, 먼저 CPU의 명령어 처리 과정을 살펴보겠습니다.
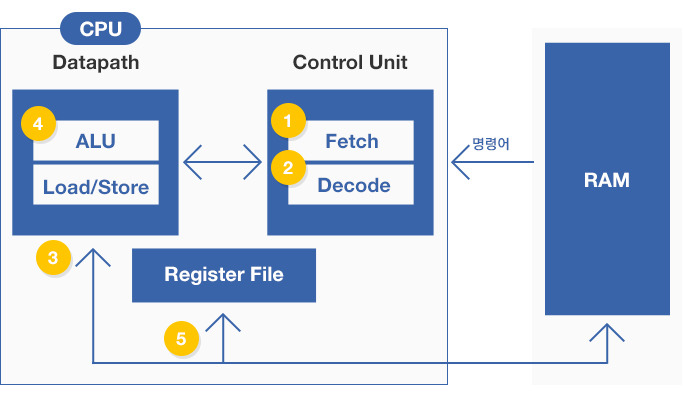
▲ CPU 명령 처리
CPU는 일반적으로 명령어의 실행을 제어하는 Control Unit과 데이터의 연산처리를 담당하는 Data Path로 구성되어 있습니다. Control Unit은 RAM에 적재된 명령어를 하나씩 가져와서 (① Fetch), 어떤 명령어인지 해석하고 (② Decode), 적당한 마이크로 명령어를 찾아 Datapath로 전달합니다.
Datapath는 Control Unit으로부터 명령어를 전달받아, 연산에 필요한 데이터는 RAM이나 Register로부터 적재(③Memory Access) 하고, ALU에서는 실제 연산(④ Execution)을 수행하게 됩니다. 연산을 마치게 되면 연산 결과는 Register에 저장(⑤ Write Back)되고 Store 명령을 통해 최종적으로 메모리에 저장됩니다.
그런데 하나의 명령어가 모두 완료되는 동안 다른 명령어들이 대기하고 있어야 한다면 굉장히 오랜 시간이 걸리겠죠? 그래서 나온 기술이 바로 파이프라이닝입니다.
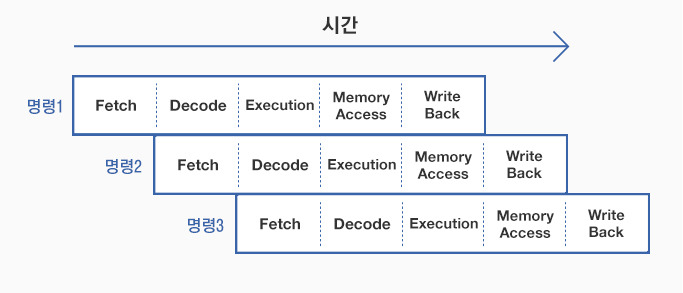
▲ 파이프라이닝
파이프라이닝은 위 그림의 예처럼, 명령어 자체를 단계별로 나누고 각 명령어들을 한 단계씩 늦춰서 순차적으로 실행합니다.그렇게 하면 명령어를 쭉 이어서 실행하여도 단계가 서로 중복되지 않아, 명령어를 처리하는 유닛 간의 간섭을 최대한 피하고 쉬는 시간 또한 줄일 수 있어 명령어의 처리시간을 단축할 수 있게 됩니다.
하지만 명령어 간 동일한 자원을 사용하거나 하나의 명령어가 앞선 명령어의 연산 결과에 종속되는 경우, 혹은 조건 분기에 따른 후속 명령 대기 등의 문제가 발생할 수도 있는데 이러한 문제를 파이프라인 해저드라고 하며 보조적인 장치나 알고리즘을 통해 해결하게 됩니다.
파이프라이닝은 명령어를 단계별로 나누고 코드의 흐름에 따라 순서대로 실행하는 방법을 사용하는 반면, 비순차 실행은 명령어의 순서와 상관없이 빨리 처리할 수 있는 순서대로 재배열 하는 방법을 사용합니다.
예를 들어, 현재 실행되고 있는 명령어와 나중에 실행될 명령어가 서로 간에 의존성이 없다면, 나중에 실행될 명령어의 순서를 앞으로 당겨서 두 명령어를 동시에 실행하는 방식으로 처리 속도를 향상시킵니다.
비순차 실행의 핵심은 바로 이처럼 동시에 실행 가능한 명령어를 최대한 많이 찾아내는 것이라고 볼 수 있는데, 이런 명령어의 성질을 명령어 수준 병렬성이라고 합니다. 이렇게 명령어를 동시에 효과적으로 처리하기 위해서는 일반적으로 슈퍼스칼라라는 기술을 사용합니다. 슈퍼 스칼라는 파이프라인 자체를 여러 개 두어 1 사이클에 더 많은 명령어를 처리하도록 합니다.물론 동시에 수행되는 파이프라인 명령은 서로 의존성이 없는 경우에만 적용될 수 있습니다.
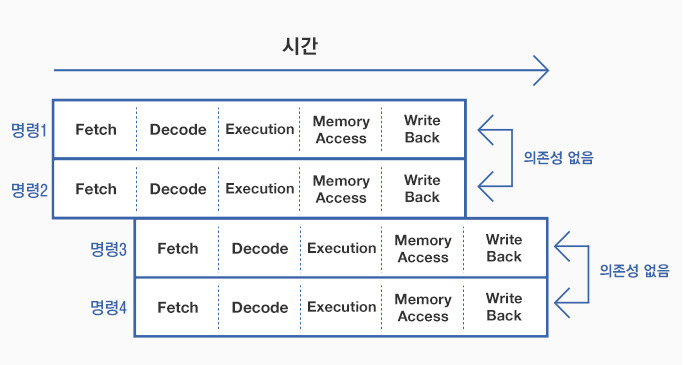
▲ 슈퍼 스칼라
슈퍼 스칼라가 비순차 실행을 마이크로 아키텍처 수준에서 구현하는 기법이라면, 좀 더 상위의 컴파일러 수준에서 비순차 실행을 구현하는 기법도 있습니다.
대표적으로, VLIW (Very Long Instruction Word)라는 기술은 프로그램을 정적으로 컴파일 하는 동안 동시에 실행 가능한 연산들을 찾아 하나의 긴 명령어에 포함시켜 병렬처리를 수행합니다.
지금까지는 하나의 명령어에 대하여 하나의 데이터가 처리되는 구조에서의 병렬처리기법을 말씀드렸습니다. 플린의 컴퓨터 시스템 분류에 따르면 이러한 구조를 SISD (Single Instruction Single Data Stream)라고 부르는데, 일반적인 싱글코어 프로세서가 이러한 구조를 가지고 있습니다.
예를 들어, “a[n] = b[n] + c[n] “라고 하는 n크기의 배열 연산을 처리할 때, SISD 구조에서는 배열의 모든 요소에 대하여 n만큼 연산을 반복해야 하므로 많은 시간을 소요하게 됩니다.
하지만 하나의 명령어에 대하여 다수의 데이터를 처리하는 SIMD (Single Instruction Multiple Data Stream)라고 하는 구조가 있는데, SIMD 구조에서는 “a[n] = b[n] + c[n]”라고 하는 배열 연산을 단 하나의 명령어로 수행합니다. 이러한 SIMD 구조의 핵심은 연속적인 복수의 데이터를 처리하는 전용 레지스터 집합 (Vector Register)과 연산의 병렬처리라고 볼 수 있습니다.
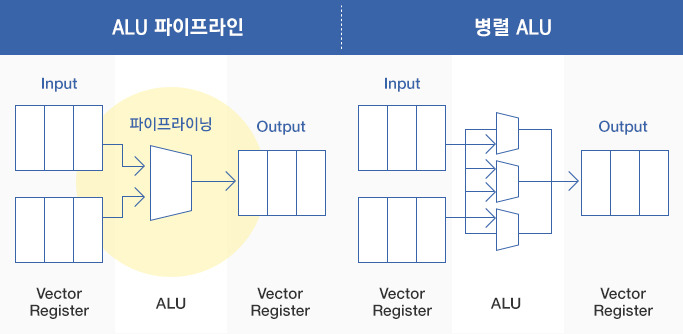
▲ SIMD
많은 슈퍼컴퓨터에서는 이러한 벡터 연산을 위해 벡터 프로세서라는 구조를 갖추고 있으며, 인텔에서도 coprocessor(보조 프로세서) 형태로 SSE(Streaming SIMD Extensions)나 AVX(Advanced Vector eXtensions) 등의 SIMD 아키텍처를 지원하고 있습니다. 대부분의 컴파일러는 SIMD Intrinsic(내장함수)을 통해 프로그래머가 직접 SIMD 명령어에 접근할 수 있게 합니다.
물론, 이후에도 설명드리겠지만 데이터 병렬처리는 멀티코어 프로세서의 멀티스레딩이나 ALU 유닛을 다수 보유하고 있는 가속기(GPU 등)를 이용하는 방법도 있습니다.
지금까지 우리는 싱글코어에서 구현되는 하드웨어적인 병렬처리 기술들을 살펴보았습니다. 싱글코어에서는 클럭 속도를 높이고 비트나 명령어 수준에서 병렬처리를 극대화하는 방법으로 성능을 향상시켜 왔습니다. 하지만 클럭 속도를 계속해서 높이다 보니 전력 소비량이 급격하게 증가하고 발열량도 매우 높아지게 되었죠. 또한 하드웨어의 제약으로 인하여 명령어를 동시에 처리할 수 있는 명령어 수준 병렬성 또한 그 한계성을 드러내게 됩니다.
이렇게 하여 칩 하나에 다수의 프로세서를 결합한 형태의 멀티코어 프로세서가 등장하게 됩니다. 멀티코어는 고클럭을 통한 성능향상이 아닌, 다수의 코어에 의한 병렬처리를 통하여 성능 향상을 꾀하기 때문에 전력소비 및 발열량에 대한 문제를 해소할 수 있었습니다. 또한 다수의 코어를 사용함으로써 처리능력을 극대화하고 쓰레드 수준 병렬성을 제공하여 프로그래밍을 통한 성능 향상이 더욱 유연해 지게 되었습니다.
다음 편에서는 멀티코어 시대에서의 병렬 컴퓨팅 기법을 살펴보도록 하겠습니다.
<참고 자료>
William Stallings (2010). ‘컴퓨터 시스템 구조론’ 진샘미디어
위키백과, http://ko.wikipedia.org
