

최근 OpenAI의 ChatGPT와 Google의 Gemini 등 생성형 AI가 연일 뉴스를 도배하며 화제가 되고 있습니다. 생성형 AI는 현재 인류가 경험해 보지 못한 많은 일들을 자동화하고 있습니다. 가령 글쓰기, 그림 그리기, 프로그래밍 등 인간의 영역이라고만 생각했던 창작의 세계에 발을 들여놓게 되었으며 인공지능 혁명의 최전선에 선 기술입니다. 이러한 생성형 AI 학습에는 엄청난 양의 데이터와 이를 학습할 강력한 하드웨어인 GPU가 필수적입니다. 이번 글에서는 생성형 AI 학습에 필수적인 GPU의 아키텍처에 대해 다루어 보겠습니다. 특히 최근 출시된 NVIDIA H100을 기준으로 중요하다고 생각되는 부분에 대해 한번 이야기해 보려고 합니다.
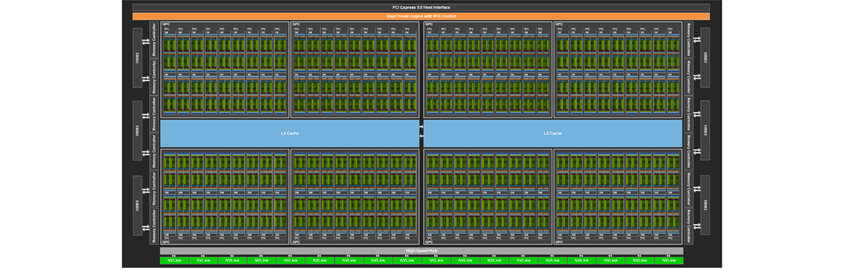 [그림 1] 144개의 Streaming Multiprocessor를 가진 NVIDIA H100 GPU
[그림 1] 144개의 Streaming Multiprocessor를 가진 NVIDIA H100 GPU
위 그림은 한 장의 GPU 구조를 보여줍니다. 데이터센터 서버 기준 보통 8장의 GPU가 한 서버에 들어가며 각 GPU는 NVLink를 통해 직접 GPU끼리 통신하게 됩니다.
다음으로 SM(Streaming Multiprocessor)에 대해 이야기해 보겠습니다. SM이란 NVIDIA GPU에서 연산 단위로 한 장의 GPU는 여러 개의 SM으로 구성되어 있으며 가장 최신 GPU인 H100은 144개의 SM으로 구성되어 있습니다. SM은 각각 고유 메모리, 캐시, 컴퓨팅 코어를 가지고 있으며, 병렬적으로 처리할 수 있는 작업을 할당받아 수행합니다. SM의 구조는 다음 그림과 같습니다.
 [그림 2] Streaming Multiprocessor
[그림 2] Streaming Multiprocessor
SM 내에 있는 컴퓨팅 코어 및 메모리 아키텍처에 대해 살펴보겠습니다.
텐서코어(Tensor Core)
텐서코어는 행렬의 곱셈과 덧셈 연산을 한 번에 수행(Matrix Multiply and Accumulation)하는 컴퓨팅 코어로 컨볼루션 연산과 같은 AI 연산에 특화되어 혼합 정밀도를 지원하여 정확도를 유지하면서 계산량을 높일 수 있습니다. 그림에서와 같이 크기가 4x4인 A, B, C, D 행렬이 있다고 해봅시다.
 [그림 3] 텐서코어 4x4x4 Matrix Multiply and Accumulation
[그림 3] 텐서코어 4x4x4 Matrix Multiply and Accumulation
A와 B 행렬은 FP16으로 곱셈 연산을 하고, 그 결과를 FP32로 더하기 연산을 수행합니다. 이 경우 곱하기 연산 시 FP16을 사용하여 계산 속도를 높이며 동시에 더하기에서는 FP32 연산을 수행하여 정확도를 유지하는 방법으로 혼합 정밀도를 지원합니다.
L1 데이터 캐시(L1 Data Cache)와 공유 메모리(Shared Memory)의 통합
L1 데이터 캐시와 공유 메모리를 하나의 메모리 블록으로 합침으로써 두 메모리 모두 성능이 향상되었습니다. 이것은 동적으로 L1 데이터 캐시와 공유 메모리의 크기를 조절함으로써 L1 데이터 캐시가 많이 필요할 경우 공유 메모리의 크기를 희생하거나 그 반대로 메모리 크기를 조정함으로써 전체적으로 캐시의 크기를 더 큰 것처럼 사용할 수 있게 하여 연산 성능을 높일 수 있습니다. 또한 이는 데이터 캐시가 워프의 스레드에서 요청한 데이터를 수집하는 병합 버퍼 역할을 하므로 메모리 접근에 대한 대역폭과 대기시간을 향상시키게 됩니다.
스레드 블록 클러스터(Thread Block Clusters)
고성능 병렬 프로그램을 수행하기 위해서 중요한 두 가지는 데이터 지역성과 비동기적 수행입니다. 데이터를 수행하고자 하는 수행 유닛 근처에 놓아서 작은 지연시간과 더 큰 대역폭을 달성하는 방법입니다. 그리고 비동기적인 수행으로 각각의 독립적인 작업이 메모리와의 데이터의 전송과 실제 계산 시간을 겹치도록 하여 GPU 사용률을 최대한 높일 수 있습니다. 스레드 블록 클러스터는 이러한 목적을 달성하기 위한 것입니다.
스레드 블록 클러스터는 스레드 블록의 집합으로 되어 있으며 스레드 블록은 스레드의 집합으로 구성되어 있습니다. 이 클러스터는 SM 그룹에서 동시에 수행되도록 보장된 스레드 블록의 모음입니다. 이렇게 함으로써 여러 SM 간의 스레드들이 작업 수행 시와 같이 수행되어 효과적으로 협력하도록 합니다. 이 스레드 블록 클러스터는 메모리 접근을 위한 협업 기능도 가지고 있습니다.
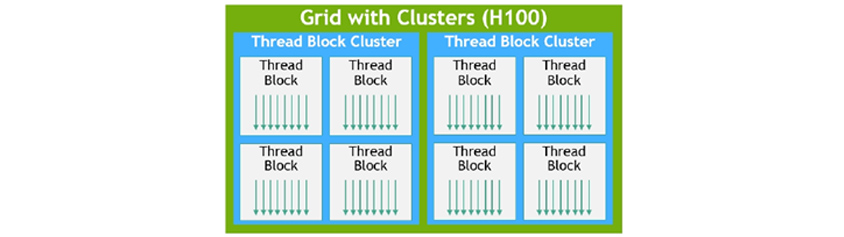 [그림 4] 스레드, 스레드 블록, 스레드 블록 클러스터, 그리드
[그림 4] 스레드, 스레드 블록, 스레드 블록 클러스터, 그리드
클러스터는 단일 SM 보다 GPU의 더 많은 부분을 직접 제어할 수 있도록 하여 성능을 향상시킵니다.
분산 공유 메모리(Distributed Shared Memory)
클러스터를 사용하여 모든 스레드들이 로드, 저장 및 원자성 연산을 통해 다른 SM의 공유 메모리에 직접 접근할 수 있습니다. 공유 메모리의 가상 주소 공간이 클러스터의 모든 블록에 대해 논리적으로 분산되기 때문에 이러한 기능을 분산 공유 메모리라고 합니다. 분산 공유 메모리를 이용하면 전역 메모리에 데이터를 읽고 쓸 필요가 없기 때문에 SM 간의 데이터 교환 시 더 효과적이며 SM 전용 네트워크를 통해 더 빠르고 낮은 지연시간을 보장합니다.
 [그림 5] 스레드 블록 간 데이터 교환
[그림 5] 스레드 블록 간 데이터 교환
클러스터는 단일 스레드 블록으로 가능한 것보다 더 큰 공유 메모리 풀에 접근이 가능하여 더 많은 수의 스레드로 협력 실행을 가능하게 합니다.
비동기적 수행(Asynchronous Execution)
GPU는 비동기적으로 여러 명령을 수행하여 GPU 효율을 최대한 끌어내도록 설계되었습니다.
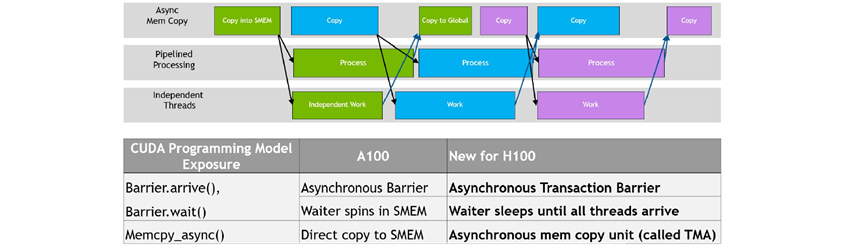 [그림 6] 비동기적 실행 동시성 예
[그림 6] 비동기적 실행 동시성 예
데이터 이동과 계산, 그리고 동기화가 중첩된 모습으로 비동기적 동시성 만족하며 동기화를 최소화하는 과정이 성능 향상의 핵심입니다. 여기서 비동기적 메모리 복사로 불리는 텐서메모리 가속기와 비동기적 트랜잭션 장벽을 이어서 설명하겠습니다.
텐서메모리 가속기(Tensor Memory Accelerator)
H100에 새로 탑재된 기능으로 텐서코어 연산에 데이터를 공급하기 위해 전역 메모리와 공유 메모리 사이의 데이터 이동을 가속하는 역할을 합니다. TMA(Tensor Memory Accelerator) 연산은 Copy Descriptor를 사용하여 수행되며 Tensor Dimension과 Block Coordinate을 사용하여 데이터를 전송합니다. TMA 연산은 Addressing 오버헤드를 줄이고 다양한 Tensor Layout(1D-5D 텐서)과 다양한 메모리 접근 모드를 이용하여 데이터 전송 효율을 증가시킵니다. TMA는 Copy Descriptor를 생성하여 주소를 생성하며 데이터를 복사하는 과정을 하드웨어에서 처리합니다. 이는 프로그래밍을 더 간단하게 합니다.
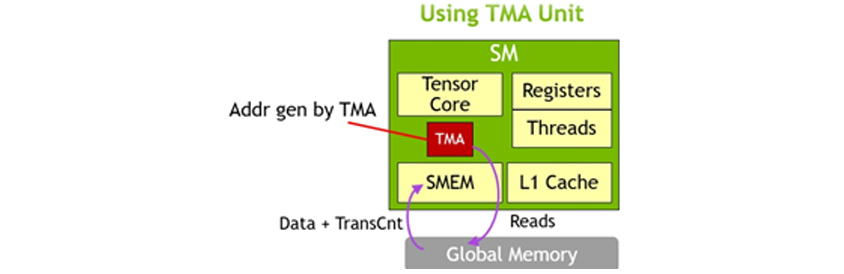 [그림 7] TMA를 이용한 비동기적 메모리 복사
[그림 7] TMA를 이용한 비동기적 메모리 복사
비동기적 트랜잭션 장벽(Asynchronous Transaction Barrier)
공유 데이터의 생성이 일부 완료되면 스레드가 도착 신호를 보내고 이때 도착 신호에 의해 스레드는 다른 독립적인 작업을 할 수 있습니다. 스레드는 다른 모든 스레드에 의해 생성된 데이터가 필요하고 이 시점에서 모든 스레드가 도착 신호를 보낼 때까지 대기를 해야 하는데 이를 비동기적 장벽이라고 합니다. 장점은 일찍 도착한 스레드가 기다리는 동안 독립적인 작업을 수행할 수 있다는 것입니다. 이러한 작업 실행의 중복성으로 인해 성능을 높일 수 있습니다.
이 개념을 확장한 비동기적 트랜잭션 장벽은 스레드의 도착만 계산하는 것이 아닌 트랜잭션도 같이 계산합니다. 비동기적 트랜잭션 장벽은 모든 스레드가 도착하고 모든 트랜잭션 수의 합계가 예상값에 도달할 때까지 대기 명령에서 스레드의 수행을 차단합니다. 이는 비동기적 메모리 복사와 데이터 교환을 위해 강력한 기능입니다. 클러스터는 묵시적 동기화를 통해 데이터 통신을 하게 되는데 이때 스레드 블록 간 통신을 수행하며 이 기능은 비동기적 트랜잭션 장벽 위에 구축됩니다.
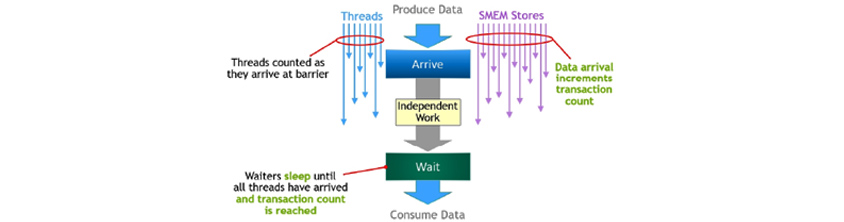 [그림 8] 비동기적 트랜잭션 장벽
[그림 8] 비동기적 트랜잭션 장벽
GPU 중 AI 학습에 가장 많이 사용되는 NVIDIA GPU에 대해 살펴보았으며 그중 가장 최신 제품인 H100의 아키텍처에 대해 살펴보았습니다. 전작인 A100과 비교 시 H100은 텐서메모리 가속기(Tensor Memory Accelerator)가 추가되었고 스레드 블록 클러스터(Thread Block Cluster)라는 개념이 등장하였으며 비동기적 장벽(Asynchronous Barrier)이 비동기적 트랜잭션 장벽(Asynchronous Transaction Barrier)이라는 기능으로 발전하여 성능이 더욱 개선되었습니다. 차기작에서 어떤 아키텍처가 더 발전하여 성능이 개선될지 기대가 됩니다.
References
[1] https://resources.nvidia.com/en-us-tensor-core
[2] https://www.nvidia.com/en-us/data-center/nvlink
[3] https://developer.nvidia.com/blog/inside-volta
[4] https://docs.nvidia.com/cuda/ampere-tuning-guide/index.html
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에게 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의 없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
![]()

삼성SDS 고성능컴퓨팅연구Lab
슈퍼컴퓨터를 이용한 수치해석 분야를 연구하여 박사학위를 취득하였습니다. LLM 추론 및 HPC 시뮬레이션 가속을 연구하고 있으며 양자 컴퓨팅 등 미래 컴퓨팅 기술에 관심이 많습니다.
