

지금까지 빅데이터에 대해 알아봤습니다. 이제 마지막 이야기가 남았네요. 이 시리즈의 대미는 ‘인공지능’이 장식하게 되었네요.
튜링 테스트와 인공지능
상대가 절대 보이지 않는 벽을 사이에 두고 대화를 합니다. 가벼운 인사로 시작해서 안부도 묻고, 코로나19 상황에 대해서도 함께 걱정했습니다. 결혼생활에 대한 고민도 털어놨는데 그냥 살라고 합니다. 눈물까지 찔끔 흘리고 고맙다고 포옹이나 한 번 하려고 옆방으로 갔더니 웬 사각형 기계가 앉아 있네요.
역사적인 사건이 일어난 겁니다. 방금 사각형 기계는 ‘튜링 테스트’를 완벽히 통과했고 인공지능으로서 최고 등급 자격을 얻게 되었습니다. 튜링 테스트는 ‘인공지능’이라는 개념을 최초로 생각해 낸 앨런 튜링(Alan Turing)이 고안한 테스트죠. 원리는 간단합니다. 판별자인 인간 C가 기계 A가 하는 답변과 인간 B가 하는 답변을 구별하지 못한다면, 기계 A는 인간의 지능을 가지고 있다는 것이죠. 이 테스트를 처음 이야기할 때는 인공지능이 금방 완성될 줄 알았답니다. 그런데 생각보다 오래 걸렸죠. 아니 오래 걸리고 있죠. 아직 인공지능은 완벽하지 않으니까요. 아직은 정의조차 명확하지 않습니다. 그나마 가장 일반적인 정의는 ‘인공지능’이라는 말을 그대로 풀이한, ‘인공적으로 만들어진 지능’입니다. 조금 허무하죠. 더 허무한 정의도 있습니다. ‘지능의 정의가 명확하지 않으므로 인공지능을 정의할 수 없음’
저는 이 정의가 솔직해 보여서 좋습니다. 정의에서 이야기를 시작하면 독자들을 더 혼란스럽게 만들 것 같아 결과에서 시작해 보겠습니다. 기계가 인간이 하는 물리적인 활동을 돕거나 대체했다면, 인공지능은 그것을 지적인 영역까지 확대하는 것이죠. 어떤 일까지 대체할 수 있고, 그것이 어떤 결과와 부작용을 불러올지는 저는 아직 잘 모르겠습니다.
안 배우는 자와 배우는 자
튜링 테스트로 돌아 가보죠. 이 테스트를 통과하기 위한 기계를 만드는 방법은 누구도 이야기하지 않았습니다. 사람인지, 기계인지, 건넛방에 있는 인간이 구분하지 못하면 되는 것이죠. 그래서 처음에는 모든 상황을 다 고려한 프로그램을 만드는 시도를 했습니다. 처음 5분 정도는 문제가 없었죠. 인사를 하고, 이름을 묻고, 어디 사는지, 무슨 일을 하는지 등등 성공이 눈앞이었죠. 이혼 문제가 나오기 전까지는 말입니다.
이렇게 상대가 어떤 말을 하면 어떻게 답하겠다는 것을 목록이나 규칙으로 정하고, 컴퓨터가 이해할 수 있는 언어로 프로그래밍해서 컴퓨터가 그대로 실행하게 하는 방식을 ‘규칙 기반 프로그램’ 또는 ‘절차적 프로그램’이라고 합니다. 규칙 기반 프로그램으로 문제를 해결하려면 과제 완수에 필요한 모든 단계와 각각의 단계를 어떻게 묘사할지를 이미 알고 있어야 하죠. 그런데 여기 문제가 있었던 겁니다. 이혼 문제는 생각지도 못했을 테니까요. 그런데 이것도 인공지능에 속하냐고요? 네! 속합니다. 인공적으로 만들어졌고, 만약 거의 무한대로 경우의 수를 빠짐없이 고려해서 옆방 사람의 이혼 문제까지 상담하고 새로운 배우자를 소개까지 한다면 ‘인공지능’ 정의에 어긋남이 없으니까요. 그런데 이런 경지에 오르는 것이 거의 불가능합니다. 여기에는 기본적으로 두 가지 한계가 있습니다.
첫째, 무한대의 경우의 수를 현실적으로 반영할 수 없습니다. 한글로 다 했다고 가정해 봅시다. 그럼 다른 언어는 어떨까요?
둘째, 설사 오늘 기준으로 완벽하게 모든 언어를 반영했어도 미래에 나타날 새로운 단어를 알 수는 없습니다. 사전에 안 올라가는 비속어들은? 생각만 해도 머리가 어지럽죠? 그래서 이 방식은 청소기와 세탁기, 냉장고 광고에 적극 활용되다가 서서히 사라졌죠.
그 시절에는 전화번호 열 개만 기억하고 알려주어도 재주 많은 전화기로 칭찬받던 시대였으니까요. 그래서 찾아낸 방법이 사람처럼 스스로 배우게 하는 것이었어요. 마치 아이가 말을 배우듯이 학습을 통해 이해시키는 것이죠. 그러면 문제는 하나만 남습니다. 즉 하나를 가르치면 열을 아는 아이(기계)를 만들면 되는 겁니다. 열을 가르치면 하나도 겨우 기억하는 녀석 말고요.
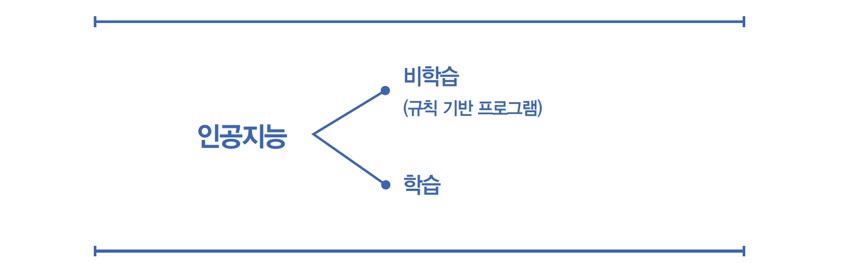
일단 학습으로 방향은 정해졌습니다. 그러면 이제 어떻게 배우게 할 것인지가 문제네요. 인간이 새로운 지식을 얻는 가장 일반적인 방법은 두 가지입니다.
첫째, 일반적인 원리에서 개별적인 사실을 깨닫는 방식
둘째, 개별적 사실에서 일반적 원리를 끌어내는 방식
첫 번째 방식은 ‘연역법’, 두 번째 방식은 ‘귀납법’이라고 합니다. 예를 들어볼게요. 튜링 테스트 중인 그 사람에게 돌아 가보죠. 알고 보니 집에 빨리 들어가기를 무척 싫어하는 40대 한국 남자였습니다. 그래서 40대 한국 남자는 조기 귀가를 거부하는 본능이 있다는 것을 연역법과 귀납법으로 증명해 보기로 합니다.
‘나는 왜 집에 들어가기 싫은가? ’ ― 연역적 증명
모든 40대 한국 남자는 집에 들어가기 싫어한다.
나는 40대 한국 남자다.
그러므로 나는 집에 들어가기 싫어한다.
‘나는 왜 집에 들어가기 싫은가? ’ ― 귀납적 증명
김 부장(40대)은 집에 들어가기 싫어한다.
박 부장(40대)도 집에 들어가기 싫어한다.
윤 부장(40대)도 집에 들어가기 싫어한다.
나는 진짜 집에 들어가기 싫어한다.
따라서 40대 한국 남자는 집에 들어가기 싫어한다.
연역적 방법은 ‘지식 기반 인공지능’ 또는 ‘기호 기반 인공지능’이라고도 부르는 인공지능 구현 방법입니다. 단순히 이야기하면 우리가 아는 모든 지식을 ‘A는 B다’와 같은 형태로 명제를 만들고, 이 명제들 간의 연역적 추론을 통해 새로운 지식이나 사실을 만들어내는 방식이죠. 앞에서 본 예를 살펴보면 바로 한계가 보일 겁니다. 결국 ‘모든 40대 한국 남자는 집에 들어가기 싫어한다.’는 명제가 문제이고, 이것이 반드시 사실이라고 할 수 없죠. 세상의 모든 것을 이런 식으로 명제로 만들어야 합니다. 얼마나 많을지 모를 명제를 다 정의해야 하고, 정의한 명제는 증명 과정을 거쳐야 합니다. 그 전제가 틀리면 인공지능은 잘못된 것을 학습하게 될 테니까요. 매우 복잡하죠? 그래서 이 방법도 거의 포기합니다.
이번에는 주변에 있는 모든 40대 남자에게 물어봅니다. 대답이 한결같습니다. 그래, 이거 완전한 팩트야! 의심의 여지가 없죠. 그런데 어느 날, 일일 아침 드라마 주인공인 40대 꽃중년 아저씨가 이 관념을 깨버립니다. 과감하게 귀가를 서두르는 사람이 있는 겁니다. 이건 가상이라고 아무리 외쳐도 소용없었죠. 여기에 귀납법이 가진 한계가 있습니다.
데이터가 충분하지 않으면 정확한 추론에 실패할 수도 있다는 점이죠. 그래서 이 방법도 깊은 어둠 속에 묻혔습니다. 그런데 디지털 전환 물결이 온 세상을 뒤덮으면서 이 방법이 살아나게 됩니다. 데이터가 엄청 많아졌거든요. 이것을 ‘머신러닝’ 또는 ‘기계학습’이라고 합니다. 지식 기반과 달리 컴퓨터에게 명제를 주는 대신, 데이터를 수없이 반복해서 들려주어 컴퓨터가 자연스럽게 단어가 가진 뜻을 인지하고 구분할 수 있게 만드는 것이죠. 이 방법이 제대로 작용하려면 두 가지 요소가 필요합니다. 즉 충분히 많은 데이터, 그리고 반복적으로 들려주고 수정하는 아주 빠른 컴퓨터입니다. 이 두 가지 요소는 빅데이터와 클라우드가 어느 정도 해결해 줍니다.
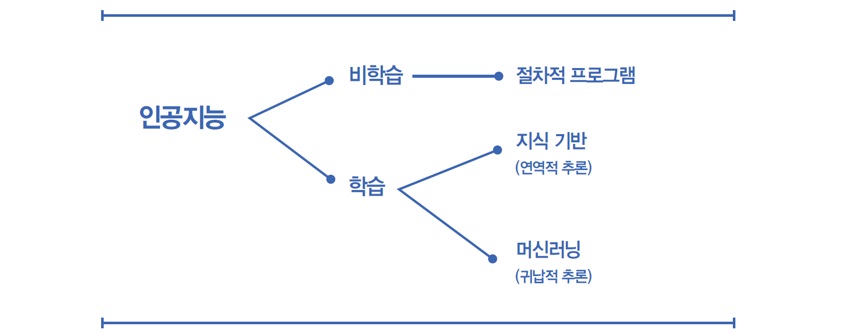
배우려면 깊게 배워야 한다!
머신러닝은 인공지능을 구현하는 방법 중 하나로, 학습을 기반으로 합니다. 그중에서도 데이터 학습 기반이어서 두 가지 조건이 필요합니다. 아주 많은 양질의 데이터, 즉 잘 정리된 빅데이터가 필요하고, 이것을 학습할 수 있는 모델이 필요합니다. 학습할 수 있는 모델도 여러 가지 방법으로 만 수 있겠지만, 이 부분은 이미 승부가 나버렸습니다. 인간의 뇌가 학습하는 방식을 모방한 인공 신경망이 압도적이기 때문입니다. 인간의 뇌는 뉴런으로 구성되어 있고, 뉴런을 수학적으로 모델링 한 것이 인공 뉴런(‘퍼셉트론’이라고도 부름)인데, 아주 단순한 수학 계산 능력을 가지고 있습니다. 이것이 연결되어 네트워크를 이루면 인공 신경망이 됩니다. 인공 신경망이 얼마나 강력한지는 이런 셀들이 서로 어떻게 연결되어 있는지에 달렸습니다. 단순하게는 인공 신경망에 층을 추가하면 더 정교한 알고리즘을 얻을 수 있습니다. 층을 하나 추가할 때마다 앞선 층에서 얻은 통찰을 새롭게 결합할 수 있는 방법이 생깁니다. 층을 많이 추가해서 더 많이 복잡한 학습을 가능하게 하는 접근법을 층이 깊다고 해서 ‘딥러닝(Deep Learning)’이라고 합니다. 층의 두께는 상대적입니다. 예전에는 보통 3층을 넘어가면 깊다고 했지만, 요즘 3층은 오히려 얕은 축에 속해서 ‘쉘로우 러닝(Shallow Learning)’이라고 합니다. 이세돌 9단과 대결한 알파고는 48층이었고, 지금은 200층 가까이 된다고 합니다.
하나의 그림으로 정리하면
이제까지의 설명을 다시 한번 정리해 보겠습니다. 학습 기반 인공지능에는 연역적 추론에 기반한 방법과 귀납적 추론에 기반한 방법이 있습니다. 둘 중 승리자는 귀납적 추론 기반이었고 이것을 ‘머신러닝’이라고 합니다. 머신러닝을 구현하는 방법은 다양하지만, 지금 주류를 이루는 것은 사람 뇌가 작동하는 방식을 모방한 인공 신경망(ANN; Artificial Neural Network)입니다. 이 중에서 층을 많이 가져가서 복잡한 학습이 가능한 것은 ‘딥러닝’입니다.
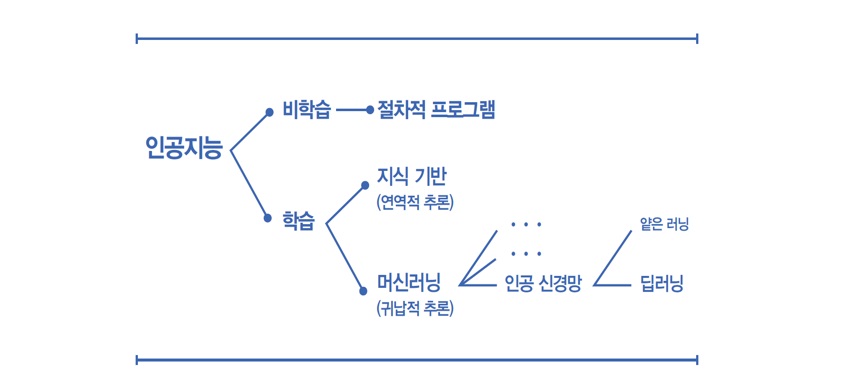
하나의 그림으로 요약한다면 이렇게 되겠네요.
인공지능을 도표 하나로 정리하는 것을 끝으로 디지털 트랜스포메이션 시리즈를 마칠까 합니다. 신기하게도 2021년 마지막에 끝이 나네요. 1년 넘는 기간 동안 잘 읽어주신 여러분께 감사 말씀 드립니다. 행복한 연말 보내시기를 기원합니다.
+ 디지털 트랜스포메이션 1편 : 애인의 유산과 매트릭스
+ 디지털 트랜스포메이션 2편 : 사이퍼의 스테이크
+ 디지털 트랜스포메이션 3편 : DT 사이클
+ 디지털 트랜스포메이션 4편 : 기업의 디지털 트랜스포메이션
+ 디지털 트랜스포메이션 5편 : 요약은 컨설턴트의 숙명
+ 디지털 트랜스포메이션 6편 : 멋쟁이는 옷을 제때 갈아입는다
+ 디지털 트랜스포메이션 7편 : 장인의 연장
+ 디지털 트랜스포메이션 8편 : 빈 비누 케이스를 제거하라
+ 디지털 트랜스포메이션 9편: DT의 핵심기술 클라우드
+ 디지털 트랜스포메이션 10편: DT의 핵심 기술 클라우드(2)
+ 디지털 트랜스포메이션 11편: DT의 핵심 기술 빅데이터(1)
+ 디지털 트랜스포메이션 12편: DT의 핵심 기술 빅데이터(2)
+ 디지털 트랜스포메이션 13편: 데이터를 분석하는 관점과 통찰력, 빅데이터(3)

![]()