

유비쿼터스(Ubiquitous) AI 서비스의 시대. 아이들이 가지고 노는 장난감도 AI 기술을 통해 스스로 학습하여 동작하고 대화할 수 있게 되었다. 한 장난감 제조사에 일하는 천재적인 AI 개발자 젬마는 사고로 부모를 여윈 조카 케이디를 위해 회사가 출시 준비 중인 AI 로봇 M3GAN(Model 3 Generative Android)을 곁에 두고 돌보게 한다. 윤리적 가치판단을 할 수 없는 M3GAN은 아이 돌봄이라는 목적과 기능에만 편향된 학습을 진행하고 스스로의 의사결정과 행동에 대한 통제권을 행사하며 급기야 끔찍한 사고를 저지르게 된다.
생성형 AI(Generative AI)에 대한 관심과 우려가 고조되는 상황에서 예상 밖의 호평을 받은 M3GAN이라는 영화에 대한 짧은 줄거리입니다. 이 영화는 2023년 1월에 개봉하여 때마침 ChatGPT가 공개되어 전 세계로 관심이 확산되던 시점에서 우리에게 AI의 윤리와 신뢰성에 대해 깊은 성찰의 필요성을 제기하고 있습니다. 영화의 제목부터 생성형 AI를 상징하는 G(Generative의 약어)를 포함하고 있다는 점도 의미심장합니다.
가까운 미래에 일하는 방식과 일반인의 생활 방식에 혁신적 변화를 가져올 것으로 주목받고 있는 기술로 생성형 AI와 초거대 언어 모델(LLM: Large Language Model)이 각광을 받으면서 실제로 영화에서와 같은 일이 현실에서도 발생하지 않을까 염려하는 세간의 우려도 있습니다. 반면에, 과도한 기우를 중단하고 AI 기술에 대한 투자와 장려를 통해 국가적 경쟁력에 집중해야 한다는 의견도 만만치 않습니다.
개인의 기본 권리 행사나 안전과 관련된 AI 서비스(M3GAN과 같이) 또는 중요한 산업설비에 관여하는 AI 시스템이라면 작동의 오류로 인한 위험의 파급효과는 치명적일 수 있습니다. 따라서, 개발자 입장에서는 AI 시스템의 결과에 대한 예측이 가능하고 최종 소비자에게 전달되기 전까지 개입을 통해 통제할 수 있어야 하고, 사용자 입장에서는 예상한 성능이 유지되면서 그 결과가 다른 사용자와 차별을 하지 않으면서 설명이 가능해야 신뢰할 수 있는 AI라고 할 수 있습니다[1].
 [그림 1] 영화 M3GAN 스틸컷
[그림 1] 영화 M3GAN 스틸컷
AI 기술의 핵심은 AI 알고리즘입니다. 하나 또는 복수의 알고리즘은 데이터 학습을 통해 최적의 모델로 탄생하고 AI 시스템의 일부분으로 작동하면서 제품에 장착되거나 서비스를 제공하게 됩니다. 모든 컴퓨팅 시스템은 입력(Input)과 출력(Output)의 인과관계가 투명하고 오류가 발생하는 경우 그 이유를 추적하거나 설명할 수 있어야 신뢰할 수 있습니다. AI 시스템도 마찬가지입니다[2]. 그러나 새롭게 등장하는 AI 알고리즘은 점점 더 많은 데이터를 학습하고 최종 모델의 구조가 더욱 복잡해지면서 그 원리를 설명하고 이해하는 것이 갈수록 어려워 보입니다.
AI가 설명 가능해야 한다는 것이 실상 새로운 이슈이거나 규제는 아닙니다. 미 연방거래위원회(FTC: Federal Trade Commission)의 FCRA(Fair Credit Reporting Act)[3]는 대출신청자의 신용평가에 사용되는 AI 모델에 대해서 신청자에게 설명하도록 1970년도부터 규제해 왔습니다. 또한 비교적 최근에 제정된 EU의 GDPR(General Data Protection Regulation)은 일정한 경우 AI의 의사결정에 대한 정보 주체의 설명요구권을 보장하고 있습니다[4]. 가트너의 조사 결과에 따르면 2025년까지 AI 기반의 디지털 제품의 30%가 신뢰할 수 있는 AI 프레임워크를 요구하게 되며 86%의 사용자가 AI 윤리 원칙을 수립한 기업에 신뢰와 충성도를 보일 것이라고 전망했습니다[5].
이렇게 AI에 대한 신뢰성의 요구가 전통적인 규제산업이던 금융업뿐 아니라 전 산업에 확대되면서 설명의 필요성과 의무는 증가하고 있음에 반해, 1,750억 개의 파라미터를 사용하는 GPT-3와 같이 AI 모델의 복잡성은 날로 증대되면서 설명도 어려워지는 것이 현실입니다. 이러한 상황에서 AI를 보다 설명 가능하게 하는 접근방법으로 무엇이 있으며 향후에 어떻게 전개될 것인지 함께 살펴보려고 합니다.
설명 가능한 AI(XAI: eXplainable AI)를 위한 기술
최근 AI 기술은 다양한 곳에서 컴퓨팅 시스템(또는 정보시스템, 디지털시스템)을 통해 사람이 해오던 의사결정을 대체하고 있습니다. 전통적인 컴퓨팅 시스템의 의사결정의 과정은 프로그램 소스코드로 투명하게 표현될 수 있었음에 반해, AI 알고리즘은 뛰어난 판단 능력을 보여주지만, 세부적인 로직을 기존 소스코드처럼 명시하거나 해석하기 어려워 통상 블랙박스에 비유되고 있습니다. 이러한 블랙박스의 구조와 개별적인 결정의 인과관계를 보다 투명하고 신뢰할 수 있도록 하려는 활동이나 노력 또는 트렌드를 XAI(eXplainable AI)라고 합니다[6].
XAI의 가장 좋은 방법은 모델의 학습 단계에서부터 설명 가능한 모델을 만드는 것입니다. 이를 위해 선형회귀(Linear Regression)나 의사결정 트리(Decision Tree) 같이 사람이 동작원리와 학습과정을 이해할 수 있는 알고리즘을 사용한다면 모델 자체(Intrinsic)로 설명이 가능하게 될 것입니다. 그러나 이와 같은 제한된 알고리즘은 학습할 수 있는 데이터도 한정되어 있고, 복잡한 문제 해결에 대해 정확도(Accuracy)도 떨어지는 단점이 있습니다. 반면, 최근에 각광받는 AI 모델은 대량의 데이터로 학습이 가능하지만 동작원리와 학습과정을 명확히 설명하기 어려운 신경망 알고리즘을 사용하는 경우가 대부분입니다. 따라서, 현재 XAI에 대한 대부분의 논의는 모델이 만들어지고 난 이후에 설명(Post-hoc)하는 방법을 대상으로 하고 있습니다.
모델에 대해서 사후 설명해야 한다는 과정상의 특징으로 볼 때 학습에 사용된 알고리즘에 구애받지 않을 (Model-agnostic) XAI 방법이 필요할 것입니다. 또 모델에 대한 전반적인 동작 방식을 설명할 것인지 혹은 개별 사건에 대한 의사결정의 인과관계에 대해서 설명하는 것이 필요한지가 경우에 따라서 다를 것입니다. 전자는 전역 설명(Global Explanations) 방법이라고 하고 후자는 국소 설명(Local Explanations) 방법이라고 합니다.
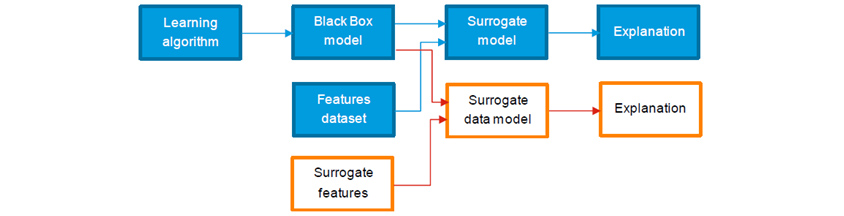
이와 같이 XAI를 바라보는 여러 관점이 있을 수 있는데, 이 글에서는 실무적으로 많이 활용하고 있는 대리모델(Surrogate Model)을 중심으로 XAI의 실제적인 개념과 활용 방법에 대한 이해를 돕고자 합니다. Surrogate Model은 전역 설명을 위해 사용되기도 하고(Global Surrogate Model) 국소 설명을 위해 사용되기도 하는데(Local Surrogate Model), 원본모델을 설명하기 용이한 대리모델을 만들기 때문에 개념상으로 둘 다 Surrogate Model이라고 통칭하기도 합니다. 국소 설명을 위해 활용되는 Surrogate Model로는 LIME, SHAP가 있습니다. 한편, 최근에는 LLM 기반의 생성형 AI가 주목받으면서 XAI는 새로운 도전을 맞이하고 있습니다. 이에 대해서도 간략히 배경과 대응 방안을 소개하였습니다. 그럼 아래에서 각각의 사례와 방법의 특징에 대해 알아보도록 하겠습니다.
[Surrogate Model]
Surrogate Model은 복잡하고 거대한 원본모델을 해석 가능하고 설명 가능할 수 있도록 모방된 모델입니다. 원본모델의 특성에 대해 최대한 해석 가능하면서 또한 설명 가능하도록 하기 위해서는 원본모델이 학습한 데이터를 사용하고, Linear Regression이나 Decision Tree 등과 같은 그 자체로 설명이 용이한 알고리즘을 사용하여 대리모델을 생성합니다. 또한, 모델의 예측 결과에 대해서 영향을 주는 변수(Feature)를 설명해야 하기 때문에 원본모델에서 산출된 예측 결과값을 가지고 근사한 결과가 산출되도록 모델을 학습하는 과정을 거치게 됩니다. 실제 응용사례를 살펴보도록 하겠습니다.
2023년에 국제통화기금(IMF)에서 공개한 연구내용은 전통적 Surrogate Model 개발 절차에서 대리모델 자체를 간명하게 생성하는 것은 일부 양보하더라도 학습 데이터가 가지는 복잡성을 간소화함으로써 모델의 작동 방식에 대한 해석 가능성을 높이고자 한 사례입니다. IMF는 COVID19 팬데믹이 아프리카 국가들의 정부 부채에 어떤 영향을 주었는지 이해하고 필요한 정책적 대응을 연구하기 위해 각 국가들로부터 경제, 금융, 인구 통계학, 행정 데이터를 수집하여 대규모 머신러닝 모델을 제작하였습니다. 그런데, GDP, 총국가부채와 원유가격 등 200개 이상의 변수(Features)를 학습하다 보니 모델의 작동 방식을 이해하기 어려워서 정책 결정에 활용하는데 한계가 있어서 Surrogate Model로 설명 가능성을 높이기로 했습니다.
- learning/→block box model/→surrogate model/→explaintion
- /→block box model/→surrogate data model/→explaintion
- /features dataset/→surrogate model/→explaintion
- /→surrogate features/→surrogate data model/→explaintion
연구자들은 경제 이론과 연구자들의 직관, 최종 모델사용자의 활용 방법, 주기적인 경제지표의 변화 등을 고려하여 총 20여 개 변수를 선택하여 전역 설명이 가능한 Surrogate Model을 제작하고 이를 SDM(Surrogate Data Model)이라고 명명했습니다. 원본모델과 비교 연구 결과, 대리모델은 몇 가지 예외적인 사건을 제외하고 원본모델이 포착한 경제위기의 움직임을 잘 근사하였습니다. 이 방법은 Surrogate Model이 원본모델의 복잡성을 줄이고, 모델의 출력을 이해하는 데 도움을 주며, 모델의 결과를 정책결정자들이 익숙한 경제 도메인의 언어로 이해하고 시뮬레이션을 위해 활용하는 데 유용하다는 결론을 얻을 수 있었던 사례입니다.
이와 같이 Surrogate Model은 원본모델의 로직을 동일하게 설명하지는 않지만, 예측 결과에 근사한 대리모델의 알고리즘을 통해 원본모델의 작동 경향을 정량적으로 이해할 수 있다는 장점이 있어 모델의 사용자나 금융기관에서 소비자에게 설명이 필요한 업무에서 활용되고 있습니다.
[LIME: Local Interpretable Model-agnostic Explanations]
LIME은 국소 설명을 위해 활용되는 대표적인 XAI 중 하나입니다. 원본모델 학습에 사용된 원본 데이터를 근사하게 변형하여 학습했을 때 어떤 현상이 발생하는지를 조사하여 해당 모델의 특정 예측 결과를 설명합니다. 이를 위해 특정한 사건의 예측에 대해 유사한 데이터 값을 발생시키고 원본모델과 유사한 모델을 생성함으로써 원본모델이 특정 예측에 이르게 된 이유를 이해할 수 있도록 도와줄 수 있습니다.
[그림 3]은 LIME을 사용하여 XGBoost Regression 모델의 결과를 분석한 예시입니다. 모델의 개별 예측 결과에 대해 설명하면서 음의 영향을 주는 변수는 파란색, 양의 영향을 주는 변수는 주황색으로 표현되었습니다. 이를 통해, 분석가는 모델이 어떻게 특정 예측에 도달했는지를 이해하고 그 과정을 설명할 수 있습니다.

- 1.68 : 0.44<whole weight...
- 0.43 : 0.13<shell weight<=...
- 0.24 : sex F<=0.00
- 0.12 : sex I<=0.00
- 0.06<diameterI<=0.42
- 0.77 : 0.19<shucked weight...
- 0.28 : 0.45<length<=0.55
- 0.09 : <height <=0.12
- 0.05 : 0.09<viscera weight...
- 0.02 : 0.00<sex M<=1.00
- whole weight : 0.51
- shucked weight : 0.22
- shell weight : 0.15
- length : 0.46
- sex F : 0.00
- sex I : 0.00
- height : 0.10
- diameter : 0.36;
- viscera weight : 0.10
- sex M : 1.00
LIME은 다음에 소개될 SHAP처럼 원본모델의 종류와 관계없이 개별 예측을 결과를 설명하기 위해서 사용할 수 있는 방법으로 테이블 데이터, 텍스트 데이터, 이미지 데이터 등 학습 데이터의 유형도 구애받지 않습니다. 하지만 특정 원본 데이터의 변형 데이터 생성 시 변수 간 상관관계를 고려하지 않으며 정규분포에서 샘플링하는 문제가 있고, 샘플링이 어떻게 되느냐에 따라 설명이 크게 달라지게 되는 일관성 유지의 문제가 있다고 지적받고 있습니다[9].
[SHAP: SHapley Additive exPlanations]
SHAP는 선형 회귀, 로지스틱 회귀, 트리 기반 모델, 이미지 분류, 그리고 감정 분석, 번역, 텍스트 요약 등 다양한 NLP(Natural Language Processing) 모델까지 원본모델의 종류에 구애받지 않으면서 예측 결과를 설명하는 데 사용될 수 있는 XAI 방법입니다.
SHAP는 예측 결과를 산출하는 데 각 Feature가 얼마나 공헌했는지를 게임이론에서 각 플레이어의 기여도를 산출하는 기법을 응용하여 Shapley Value로 표현할 수 있습니다. 즉, 단순히 개별 Feature의 유무에 따른 영향도가 아니라 다른 Feature와의 관계까지 고려하고 있는 것이 이 방법의 장점입니다.
[그림 4]는 NLP 모델에 SHAP를 적용하고 결과를 시각화한 사례입니다. 사용한 데이터는 Twitter에서 수집된 텍스트 데이터이며, NLP 모델은 각 텍스트를 ‘sadness’, ‘joy’, ‘love’, ‘anger’, ‘fear’, ‘surprise’ 6개의 감정으로 분류합니다. 이 그림에서 상단의 output에 파란색으로 배경처리 된 단어가 예측하고자 하는 감정이고, 그 아래 차트에서 함수 값은 해당 감정을 예측하는 결과 값입니다. 막대기로 표시된 도형에 기입된 단어는 예측하는 감정에 영향을 주는 SHAP값을 의미하는데 길이는 값의 크기를, 빨간색은 +영향을 파란색은 –영향을 의미합니다.

- -4~-1.78088:base value:feeling
- 2 전 후: hopeless
- 5.35388~:f(input): opef
- I can go from feeling so hopeless to so damned hopeful just from being around someone who cares and is awake
- -8~-6.73137:f(input) :hopeful
- -6.73137 ~ -1.38449:base value: hopeless
- -1.38449:base value~: feeling
- I can go from feeling so hopeless to so damned hopeful just from being around someone who cares and is awake
본 예제에서는 Transformer 모델 중 하나인 BERT(NLP 모델)를 이용하여 학습한 감성 분석 모델에 SHAP를 적용하였습니다. 먼저 주어진 문장에 대해 사용자의 감성을 분석하고 다음으로 SHAP 방법을 활용하여 텍스트에 사용된 단어들의 Feature를 이용하여 발생 가능한 모든 순열구조를 만든 후, 각 Feature의 가감을 통해 예측 값을 계산하면서 그 평균적인 영향을 Shapley Value로 표현했습니다. 끝으로 SHAP 라이브러리가 제공하는 시각화하는 기능을 사용하여 모델의 설명을 보다 가시화했습니다.
차트 아래에 있는 텍스트에서 빨간색으로 보여지는 단어는 분류된 감정의 +영향을 파란색으로 보여지는 단어들은 -영향을 끼쳤다는 것을 색상의 농도로 직관적으로 이해할 수 있습니다.
SHAP는 게임이론을 바탕으로 모델의 특징을 일관성을 가지고 설명할 수 있다는 장점이 있습니다. 하지만, 각 Feature의 기여도를 계산하는 방식이 Feature 수의 지수만큼 계산량이 증가하는 특정이 있어 변수가 10~20개 수준을 넘어가는 모델의 설명 방법으로는 추천하지 않습니다[11].
XAI 적용을 위한 고려사항
설명 가능한 AI 기술에 대한 연구가 비교적 최근 들어 활발하게 진행되었고 최근 몇 년 동안은 연구 논문도 비약적으로 증가하면서 활용할 수 있는 오픈소스도 다수가 공개되고 있습니다. 그러나, 해석 가능성과 유지보수성이 중요한 AI 모델의 개발자 입장과 인과관계에 대한 직관적 판단이 중요한 최종사용자의 입장에 있어서 양쪽 모두의 요구사항을 만족하고 있는지, 아직은 넘어야 할 한계점이 있어 보입니다.
Global Surrogate Model의 경우, 기존 모델의 예측 결과를 가능한 한 잘 반영하면서 보다 간단한 대리모델을 제공하는 것이므로 모델의 복잡성과 학습한 Feature의 규모에 따라 대리모델의 결과가 원본모델과 비교하여 차이가 커질 수 있습니다. SHAP는 모든 가능한 Feature의 조합에 대해 각 Feature가 예측 결과에 얼마나 기여하는지를 계산하게 되므로 계산량이 기하급수적으로 증가하는 특징이 있었습니다. 따라서, Feature의 수가 많고 학습하거나 추론해야 하는 데이터의 크기가 큰 경우나 실시간으로 고객에게 설명이 필요한 AI 서비스를 위해서는 적용하기 어렵습니다. LIME은 설명하고 싶은 특정 예측값에 대해 그 설명 변수가 되는 입력값의 주변 값을 생성해서 대리모델을 만드는 방식이므로 전체 모델의 동작을 설명하기는 어렵습니다. 또한, 주어진 입력값 주변의 데이터를 샘플링하고, 이 샘플들에 대한 모델의 예측을 사용하여 설명하기 때문에 어떤 값을 샘플에 반영하는지에 따라 설명이 일관되지 않을 수 있습니다.
| (Global) Surrogate Model | SHAP | LIME | |
|---|---|---|---|
| 특징 | 복잡한 모델의 예측을 근사한 모델 생성을 통해 간소화 | 개별 예측에 대해 Feature의 모델 결과 기여도를 상호관계를 고려하여 측정 | 개별 예측에 대해 원본 데이터에 근사한 데이터를 샘플링하여 유사 모델을 생성 |
| 장점 | 복잡한 모델의 전역적인 해석을 제공 | 전역적인 Feature의 상대적 기여도를 국소적인 기어도의 평균을 통해 계량화 | 개별 예측에서의 Feature의 영향도를 가중치로 계산 |
| 단점 | 원본모델이 복잡해질 수록 근사한 모델 생성이 어려움, 개별 예측에 대한 설명이 제한적 | 계산량이 많아 Feature의 수가 많은 대용량 데이터, 또는 실시간 설명 용도로 활용이 어려움 | 샘플링으로 인한 설명의 불안정 발생 |
| 활용 | 신용평가모형, 거시경제분석모형 등에서 동작 원리를 설명하거나 예측 시뮬레이션에 활용 | 질병발생 여부, 고객이탈 원인 등 비교적 시급성이 덜한 예측에서 Feature의 영향을 확인 | 신용점수 산출, 카드부정사용 판별 등 개별 예측에서 Feature 기여도를 이해 |
생성형 AI의 설명을 위한 접근 방법
최근 전례 없는 엄청난 양의 데이터를 학습한 LLM 기반 생성형 AI의 등장으로 고객 커뮤니케이션 서비스의 질을 높이고 업무의 비약적인 혁신을 도모하려는 시도가 급격히 증가하고 있습니다. 특히, 2022년 말부터 전 세계적으로 관심을 끌고 있는 ChatGPT 경우 사용자와 대화를 수행하며, 사용자의 질문에 대한 응답을 생성하는데 미증유의 성능을 보여주면서 이러한 기대를 부풀리고 있습니다. 사람에게만 고유한 영역으로 여겨졌던 창의성이 있는 것처럼 대화하는 기능은 ChatGPT를 사람과 같은 지능을 가진 존재로 오해하게 만들기도 합니다. 그럴수록 ChatGPT가 답변하는 과정이 무엇인지, 어떤 데이터를 학습하였는지, 결과는 신뢰할 만한지에 대해서 더 궁금해 할 수 밖에 없습니다.
GPT-3의 경우 1,750억 개의 파라미터들이 갖고 있는 가중치와, 토큰으로 분해되어 들어간 사용자 입력이 복잡하게 상호작용하여 응답이 생성됩니다. 이와 같이, 생성형 AI는 수백만에서 수천억 개의 파라미터를 사용하여 복잡한 패턴을 학습한 모델을 통해 사용자의 요청에 대한 응답을 생성하거나 선택하는 데 활용하므로 실제 모델이 어떤 과정으로 의사결정을 내리는 것인지 파악하기가 다른 AI 모델보다 훨씬 더 난해합니다.
생성형 AI 모델의 동작 원리를 설명하기 위한 접근법 중의 하나로, 딥마인드의 연구자들은 언어 모델에게 질문하는 행위인 Prompting에 ‘Chain of Thought’라는 기법을 적용함으로써 모델의 동작 방식에 대한 투명성을 높일 수 있다고 주장했습니다. 앞서 설명한 Surrogate Model과 같은 XAI는 기존의 AI 모델의 의사결정을 설명하기 위해 또 다른 AI 모델을 생성하는 추가 투자가 필요한 방법입니다. 그런데 Chain of Thought는 Prompting을 어떻게 하느냐에 따라 LLM이 자신의 의사결정에 대해서 스스로 설명하게 만듭니다. 이러한 결과는 추론 방식을(Thought) 유추할 수 있도록 여러 단계로 Prompting를 분해해서(Chain) 수행함으로써 LLM도 이에 따라 어떻게 문제를 해결하는지 절차적으로(Chain) 답하게(Thought) 함으로써 가능합니다.
[그림 5]는 Chain of Thought Prompting을 통해 언어 모델에게 문제를 여러 단계로 분해하고, 각 단계를 순차적으로 처리하도록 지시하는 과정을 보여줍니다. 좌측의 표준적인 Prompting(Input)은 언어 모델에게 간단한 덧셈 질문과 단답형의 답 예시를 제공한 뒤, 추가적인 덧셈 질문을 했을 때 단답형의 틀린 결과를 돌려주었습니다. 그러나 우측은 Chain of Thought Prompting를 통해 추론 과정을 LLM에게 알려줌으로써, 추가적인 질문에 대해 추론 과정과 함께 답변하도록 하였습니다. 결과적으로 우측의 Chain of Thought Prompting은 답변의 정확도를 높임과 동시에 추론 과정을 스스로 설명하게 함으로써 XAI를 실현하고 있습니다.

- input
- Q:roger has 5 tennis ball. he buys 2 more cans of tennis balls. each can has 3 tennis balls. how many tennis balls does he have now?
- A:the answer is 11.
- Q:thw cafeteria had 23 apples. if they used 20 to make lunch and bought 6 more, how many apples do they have?
- model output
- A:the answer is 27. X
- input
- Q:roger has 5 tennis ball. he buys 2 more cans of tennis balls. each can has 3 tennis balls. how many tennis balls does he have now?
- A:roger starded with 5 balls. 2 cans of 3 tennis balls each is 6 tennis balls. 5+6=11. the answer is 11.
- Q:the cafeteria had 23 apples. if they used 20 to make lunch and bought 6 more, how many apples do they have?
- model output
- A:the cafeteria had 23 apples originally. they used 20 to make lunch. so they had 23 -20 =3. they bought 6 more apples, so they have 3 + 6 = 9.the answer is 9. √
생성형 AI는 AI 개발자가 일일이 답을 알려주지 않아도 이미 학습된 초거대 데이터를 기반으로 기대하는 결과에 근접한 산출물을 스스로 만들어 냅니다. 앞 절에서 소개해 드린 기존의 XAI 방법들이 결국에는 AI 개발자가 추가로 개발해야 하는 방법이었다면 Chain of Thought과 같은 방법은 이미 AI가 자체로 가지고 있는 기능을 끌어내서 활용하는 방식으로 사용자 중심의 활용 방식이라 할 수 있습니다. 앞으로는 이러한 방식의 XAI가 더욱 많이 시도될 것이라고 기대합니다.
XAI, 전망과 시사점
AI 기술의 활용 범위가 비약적으로 확대되며 산업 및 개개인의 삶에 큰 영향을 끼치고 있습니다. 이에 따라 AI 기술이 포함된 제품과 서비스의 안전과 신뢰성에 대한 관심도 증가하고 있습니다. 안전하고 신뢰할 수 있는 디지털시스템에 대하여 그 작동 과정의 투명성을 요구하는 것과 마찬가지로 사용자가 신뢰할 수 있는 AI를 위해 설명 가능성은 필수조건입니다. 미국과 유럽을 포함한 많은 국가에서 안전하고 신뢰를 받을 수 있는 AI 도입을 촉진하기 위해 이런 조건을 법제화하고 있는 것을 확인할 수 있습니다.
본문에서는 우리는 설명 가능한 AI 기술 중에 대표적인 사례 몇 가지를 살펴보았습니다. 여기서 소개된 방법들 외에도 다양한 XAI 방법들이 존재하고 있습니다. 이런 방법들은 설명하려는 대상과 목적에 따라, 학습 데이터의 규모와 Feature의 종류에 따라 무엇을 사용해야 하는지 달라질 수 있습니다. 또한, 모델의 동작을 정확하게 이해하고 개선할 책임이 있는 모델 개발자에게는 설명의 내용이 상세하고 모델의 내부 구조를 해석하는 것이 중요하겠지만, 일반 소비자한테는 모델의 개별 의사결정에 대해서 상식만 가지고도 직관적으로 이해할 수 있는 것이 필요할 것입니다. 이런 면에서는 하나의 AI 모델을 위해서 다양한 XAI 방법을 복합적으로 사용하는 경우도 있겠습니다.
예를 들면, 대출 심사에 사용되는 인공지능 신용평가모형의 설명 가능성을 제공하기 위해 만들어진 Surrogate Model은 금융소비자에게 신용평가모형의 결정에 대한 직관적인 설명을 제공하면서, 동시에 모델 개발자는 신용평가모형이 실시간으로 서비스되고 있는 인프라 환경에서 해당 모형에 사용된 주요 변수들의 SHAP값이 시간이 지나도 일정하게 유지되고 있는지 계속 모니터링 하면서 모델의 신뢰성을 확보하기 위해 노력할 수 있습니다.
최근에는 주요 빅테크 기업과 학계 그리고 규제기관에서 XAI 기술에 투자와 연구를 장려하면서 규제에 대응하고 사용자를 안전하게 보호하려고 노력하고 있습니다. 이러한 노력은 AI가 사회에 미치는 부정적 영향과 잠재적인 위험을 최소화하는 데 도움이 될 것입니다. 특히, 의료와 자율주행 등 사람의 안전에 심각한 영향을 끼칠 수 있는 AI 기술에 대해서는 더 높은 정확도를 가지고 의사결정의 과정을 설명할 수 있어야 할 것입니다. 생성형 AI 모델의 경우, 기존의 머신러닝 모델과 비교하기 어려운 만큼의 복잡도를 가지고 있으나 아직 설명 가능성에 대한 연구는 시작 단계입니다. Chain of Thought와 같은 대안적 방법을 통해 생성형 AI 모델의 의사결정 과정을 이해하려는 시도가 지속될 전망입니다.
ChatGPT가 촉발시킨 생성형 AI의 열풍은 AI의 투명성과 신뢰성에 대한 관심을 환기시키는 데 중요한 계기를 제공하였으며, 과거에 금융산업을 중심으로 논의되던 소비자에 설명 요구권도 다른 산업으로 확산되고 있습니다. 이에 따라 설명 가능한 AI 기술의 적용을 통해 안전하고 신뢰받을 수 있는 AI 서비스를 제공하는 기업에 대해서 소비자의 충성도가 높아질 수밖에 없기에 소비자와 기업 모두에게 혜택을 제공하는 방향으로 AI는 계속 발전해 나갈 것입니다.
References
[1] Mittelstadt, B., Russell, C., & Wachter, S. (2019, January). Explaining explanations in AI. In Proceedings of the conference on fairness, accountability, and transparency (pp. 279-288).
[2] Wing, J. M. (2021). Trustworthy ai. Communications of the ACM, 64(10), 64-71.
[3] https://www.ftc.gov/legal-library/browse/statutes/fair-credit-reporting-act
[4] https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:32016R0679#d1e2513-1-1
[5] Kaur, D., Uslu, S., Rittichier, K. J., & Durresi, A. (2022). Trustworthy artificial intelligence: a review. ACM Computing Surveys (CSUR), 55(2), 1-38.
[6] Adadi, A., & Berrada, M. (2018). Peeking inside the black-box: a survey on explainable artificial intelligence (XAI). IEEE access, 6, 52138-52160.
[7] Chan-Lau, J. A., Hu, R., Ivanyna, M., Qu, R., & Zhong, C. (2023). Surrogate Data Models: Interpreting Large-scale Machine Learning Crisis Prediction Models.
[8] https://towardsdatascience.com/squeezing-more-out-of-lime-with-python-28f46f74ca8e
[9] Ribeiro, M. T., Singh, S., & Guestrin, C. (2016, August). "Why should I trust you?" Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining (pp. 1135-1144).
[10] https://shap.readthedocs.io/en/latest/text_examples.html
[11] 오오쓰보 나오키 외, 『XAI, 설명 가능한 AI: 주요 파이썬 라이브러리를 활용한 개별 기술 학습과 실습까지』, 비제이퍼블릭, 2022, p. 49
[12] Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q. & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35, 24824-24837
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에게 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의 없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
![]()

조남용 | 삼성 SDS 금융컨설팅팀
기업 고객 대상으로 AI, Data 기반 Digital Transformation 컨설팅을 담당하고 있습니다. 신뢰할 수 있는 AI가 AI 서비스 기획의 가장 기본이 될 것이며, 기업들이 클라우드 서비스 파트너와 협업을 통해 AI 거버넌스를 수립하고 지속적 통제가 가능한 AI 플랫폼을 도입하는 것이 필요하다고 봅니다.
안동욱 | 삼성 SDS 금융컨설팅팀
생성형 AI가 촉발시킨 초거대 AI 비즈니스 열풍은 이 세상을 더 나은 방향으로 변화시킬 것이라 믿습니다. 다양한 잠재력을 보여주고 있는 AI 기술을 활용하는 동시에 법적, 윤리적 쟁점을 완화시킬 신뢰가능한 AI 에 관심을 두며, 많은 기업들과 협업하고 소통하기를 기대하고 있습니다.