

데이터 웨어하우스(Data Warehouse, 이하 DW)는 기업 데이터를 통합하고 데이터 기반 의사결정을 지원하는 시스템입니다. 최근 들어 데이터 유형이 다양해지고 실시간에 준하는 데이터 제공이 지속적으로 요구되고 있습니다. 또한 클라우드 기반으로 시스템이 전환되는 사례가 증가하면서 이에 맞는 데이터 관리 방안과 처리 방법의 필요성이 증가하고 있습니다. 하지만 이러한 변화를 기존 DW로 지원하기에는 현실적으로 여러 제약사항이 존재합니다. 이런 이유로 아마존 Redshift, 구글 BigQuery 등 다양한 클라우드 기반 DW 서비스들이 출시되고 있으며, 2022년 DW 클라우드 시장의 경우 전년 대비 20.62% 성장을 예상하고 있습니다. (북미, 유럽, APAC, MEA 및 남미)1
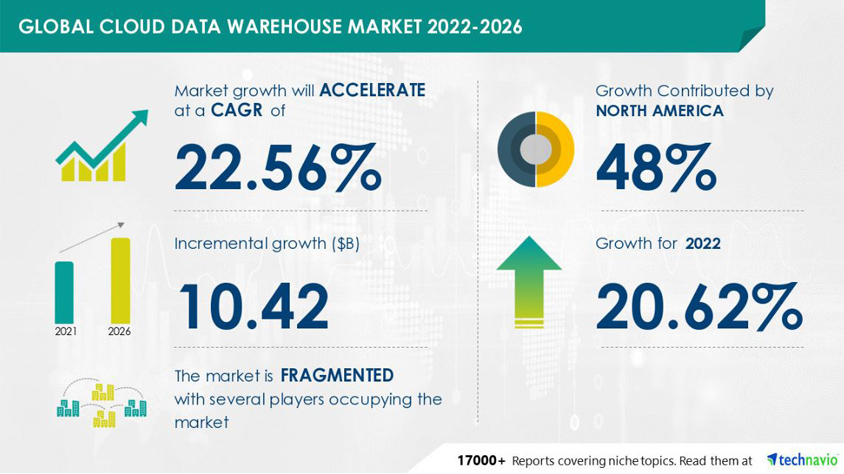
- market growth will ACCELERATE at a CAGR of - 22.56%
- Growth contributed by NORTH AMERICA - 48%
- Incremental growth ($B)- 10.42
- Growth for 2022 - 20.62%
- The market is FRAGMENTED with several players occupying the market
클라우드 기반 DW는 기존 온프레미스(On-premise) 기반 DW와 무엇이 다를까요? 또 도입 시 어떤 부분을 고려해야 할까요?
효율적인 자원 활용
클라우드 기반 DW는 필요한 자원을 필요 시점에만 사용할 수 있다는 장점이 있습니다.
컴퓨팅 스케일링
DW는 대량의 데이터를 처리하기 위한 고성능 컴퓨팅 자원이 필요하지만, 사용 시간이 특정 시간대에 몰려있고 비정기적인 작업도 미리 조율해 진행하기 때문에 컴퓨팅 자원이 필요한 시점을 예측할 수 있습니다. 예를 들어, 대부분의 ETL 작업들은 새벽에 집중적으로 일어나며, 대규모 작업의 경우 일정 협의 후 진행함으로써 고성능 자원이 필요한 시점을 계획할 수 있습니다.
하지만 온프레미스 기반 DW의 경우 시스템 자원의 축소/확장이 유연하지 않아 부득이 최대 시스템 사용량을 감안해 구성해야 했고, 이로 인해 고성능 컴퓨팅 자원이 필요하지 않은 시간대에도 그 자원을 계속 유지해야만 했습니다.
이에 반해 클라우드 기반 DW는 컴퓨팅과 스토리지를 분리하고 스케일링할 수 있도록 구성되어 있어 필요 시점에만 자원을 할당해 사용할 수 있습니다.

- Batch loading ->
- Streaming ingestion ->
- replicated, distributed storage
- - distributed memory shuffle ->
- petabit network
- highly available compute cluster
짧은 기간 대규모의 데이터 처리가 필요한 경우라면 Amazon EC2 스팟 인스턴스3 요금제를 활용해 90% 할인된 가격으로 고성능 컴퓨팅 자원을 필요한 만큼만 사용하고 반납하여 비용을 절감할 수 있습니다.
병렬 처리
이렇게 스케일링된 자원들은 작업을 병렬로 수행해 빠른 데이터 처리가 가능해집니다. 예를 들어, 아마존 Redshift의 경우 Leader node가 작업을 분배해 Compute node에 전달하면 각 분산된 Compute node는 할당된 작업을 다시 쪼개서(Slices) 대용량의 데이터를 병렬로 빠르게 처리합니다.
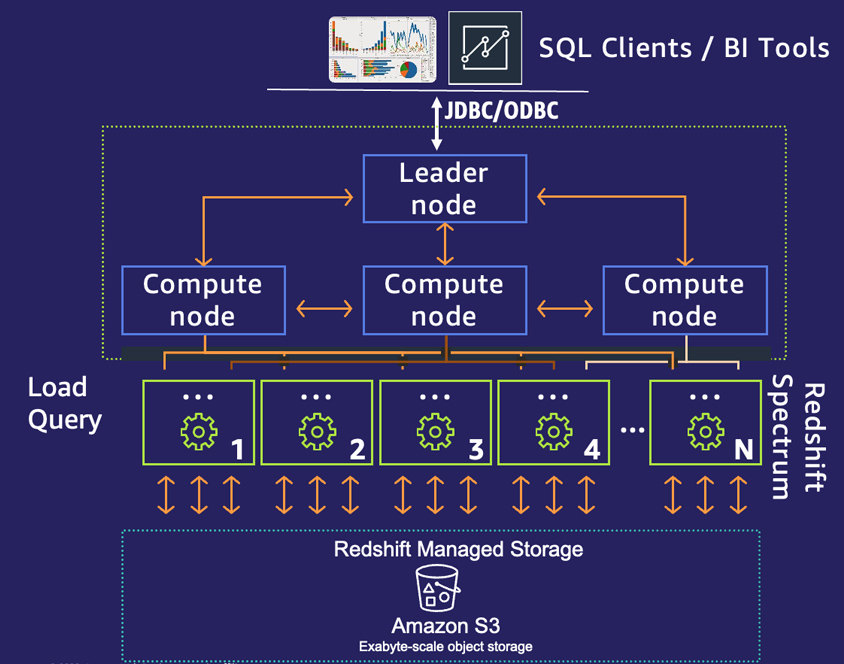
- leader node
- compute node / compute node / compute
- 1/2/3/4/.../n
- redshift managed storage
- Amazon S3, exabyte-scale object storage
스토리지 스케일링
유입되는 데이터가 누적됨에 따라 DW에는 더 많은 스토리지가 필요하게 됩니다.
온프레미스 기반 DW의 경우 스토리지 확장은 매우 큰 작업입니다. 별도 스토리지 노드를 추가하려면 당장 필요하지 않더라도 몇 년 후 데이터 증가분을 미리 예측해 대용량 스토리지를 설치해야 하고, 이에 따른 영향도 검토를 진행하는 등 많은 시간과 비용이 소요됩니다.
하지만 클라우드 기반 DW는 스토리지 스케일링 작업을 단순화함으로써 추후 데이터 증가를 예측할 필요 없이 현재 필요한 데이터 용량만 유지하면 됩니다.
서버리스 기반 스케일링 및 도구 지원
클라우드 기반 DW는 운영자가 스케일링을 직접 제어할 수 있는 방법도 제공함은 물론 운영자의 개입 없이 스케일링을 자동으로 관리해 주는 서버리스(serverless) 방식도 지원합니다. 또한 구글 Cloud DataFlow5와 같이 작업량에 따라 스케일링된 리소스들을 자동으로 프로비저닝하고 관리하는 도구들도 지원하고 있으며, 스토리지 간의 고성능 네트워크(petabit network)를 구성해 스케일링된 노드 간 전송 딜레이를 최소화하는 등 스케일링으로 복잡해진 시스템 구조를 단순화하고 쉽게 관리할 수 있는 방법들을 제공하고 있습니다.
다양한 서비스와의 유연한 연계 제공
DW는 기업 데이터의 라이프 사이클 속에서 유기적으로 연계되어 활용되어야 합니다. 하지만 온프레미스 기반 DW 환경에서는 서로 다른 기술을 기반으로 하는 시스템들과의 연계가 어려울 뿐 아니라, 이를 수행할 기술을 가진 인력을 보유하기도 쉽지 않습니다. 또한 새로운 솔루션을 도입하기 위해서는 복잡한 절차를 거처야 하고, 도입하더라도 활용성이 낮은 경우 적지 않은 매몰 비용으로 인해 부득이 유지하고 있는 경우도 발생합니다.
클라우드 기반 DW는 데이터 수집부터 BI/머신러닝까지 일관된 서비스 연계를 지원합니다. 이를 통해 운영 조직 내 특별한 기술 역량이 없이도 쉽게 서비스 간 연계가 가능하며, 필요할 때만 서비스를 사용하고 반납함으로써 솔루션 도입에 따른 시행착오와 위험을 줄일 수 있습니다.
데이터 웨어하우스 + 데이터 레이크 = 데이터 레이크하우스(Data Lakehouse)
최근 원시 데이터를 공통 저장소에 집합시키는 데이터 레이크(Data Lake)와 정제된 데이터를 관리하는 데이터 웨어하우스(DW)를 결합시킨 데이터 아키텍처로 데이터 레이크하우스(Data Lakehouse)가 제안되고 있습니다.6 또한 구글에서는 데이터 레이크와 데이터 웨어하우스(DW)를 통합한 스토리지 엔진인 빅레이크(BigLake) 서비스를 출시하기도 하였습니다.7
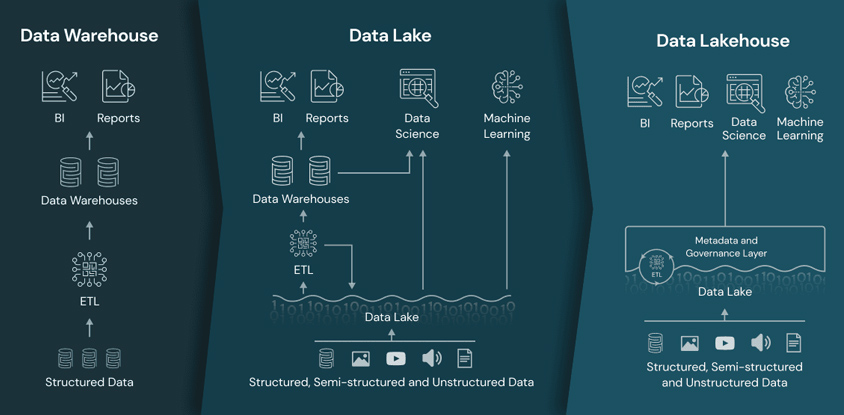
- BI / Reports
- data warehouse
- ETL
- structured data
- BI / Reports data science machine learning
- data warehouses
- ETL
- data lake
- structured, semi-structured and unstructured data
- metadata and governance layer
- data lake
- structured, semi-structured and unstructured data
실제 원활한 데이터의 활용을 위해서는 데이터 레이크와 데이터 웨어하우스와의 연계가 필요하지만 온프레미스 기반 DW는 연계를 위한 별도 환경이 필요할 뿐 아니라 데이터 이중 관리 등의 문제가 발생하게 됩니다. 이에 반해 클라우드 기반 DW는 다른 데이터 시스템들과 통합할 수 있는 서비스들을 제공하고 있어 외부 시스템과의 유연한 연계가 가능해집니다.
아마존의 경우 AWS Glue 서비스를 통해 비정형 데이터들을 카탈로그화 시킨 후 Redshift Spectrum을 통해 DW에 별도 적재 없이 직접 활용할 수 있도록 지원하고 있으며, 구글 Bigquery도 Parquet, CSV, ORC 등의 데이터 형식을 DW와 연계해 사용할 수 있도록 Federation Query를 제공합니다. 이를 통해 시스템 간 별도 데이터 이동 없이 일관된 데이터 활용이 가능해집니다.
데이터 분석 에코시스템
클라우드 기반 DW에 집중된 데이터는 AI, 대시보드, 시각화 등 다양한 서비스들과 연계됨으로써 기업 내 데이터 활용을 극대화할 수 있습니다. 또한 이러한 서비스들은 사용 신청만으로 쉽게 연계 가능합니다.
구글은 데이터 처리, 데이터 레이크, DW 간 연계뿐 아니라 자체 개발한 번역 기능, 다양한 AI 예측 모델과도 연계할 수 있도록 지원함으로써 데이터 활용성을 더욱 높였습니다.
아마존의 경우 데이터를 대시보드화(Amazon Quicksight)하고 데이터 사이언스 업무에 연계될 수 있도록 지원(SAGEMAKER)할 뿐 아니라 간단한 머신러닝의 경우 쿼리 형식으로 DW에서 바로 수행할 수 있는 기능도 제공하고 있습니다.
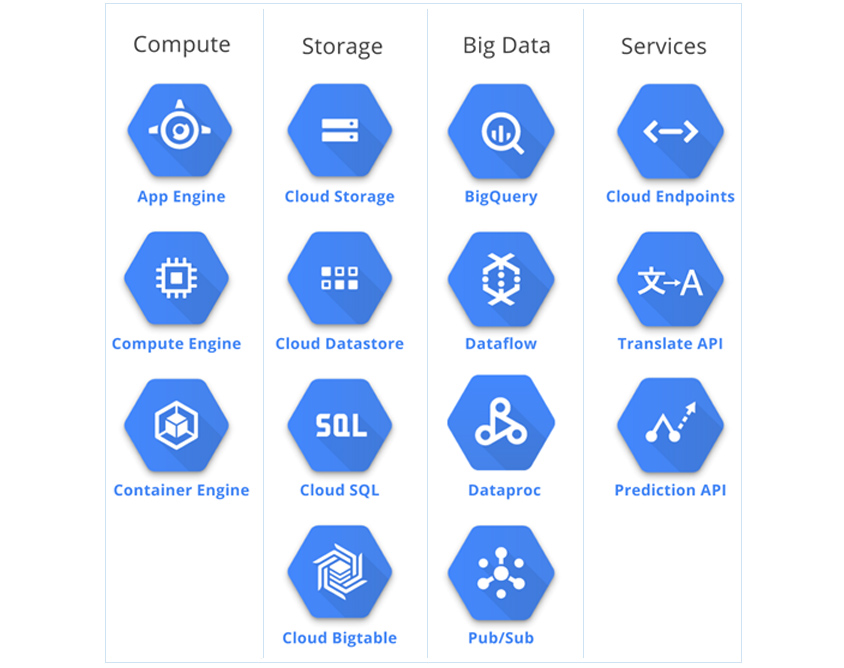
- app engine
- compute engine
- container engine
- cloud storage
- cloud datastore
- cloud SQL
- cloud bigtable
- bigquery
- dataflow
- dataproc
- pub/sub
- cloud endpoints
- translate API
- prediction API
마이크로소프트도 일관된 데이터 활용 경험을 제공하기 위해 빅데이터 Spark, DW, Power BI, Azure ML과 같은 서비스들이 통합된 Azure Synapse 서비스를 제공합니다.
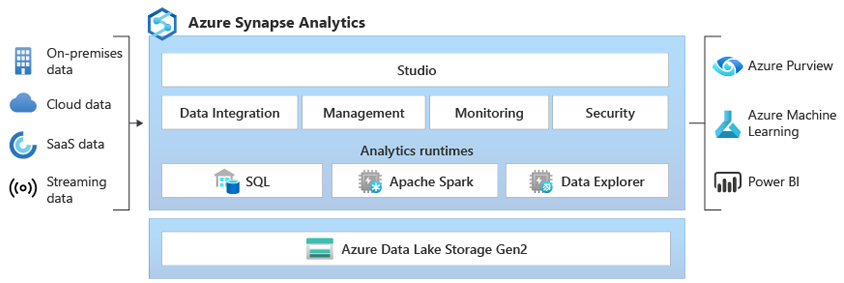
- on-premises data
- cloud data
- SaaS data
- streaming data
- studio
- data intrgration / management / monitoring / security
- analytics runtimes
- SQL / Apache Spark / Data Explor
- Azure Data Lake Storage Gen2
- Azure purview
- Azure machine learning
- power BI
또한 Azure Synapse Studio를 통해 이러한 서비스들을 연계해 데이터 엔지니어링부터 데이터 분석, DW 관리까지 one-stop-shop 방식으로 사용할 수 있습니다.
 Azure Synapse Studio (출처: 마이크로소프트)10
Azure Synapse Studio (출처: 마이크로소프트)10
쉬워진 데이터 공유
리전(Regions)은 전 세계에 분산된 데이터 센터들을 지리적으로 묶은 개념으로 이를 통해 클라우드 사용자들은 별도 네트워크망 구축 없이 쉽게 전 세계 리전 간 연계가 가능합니다.
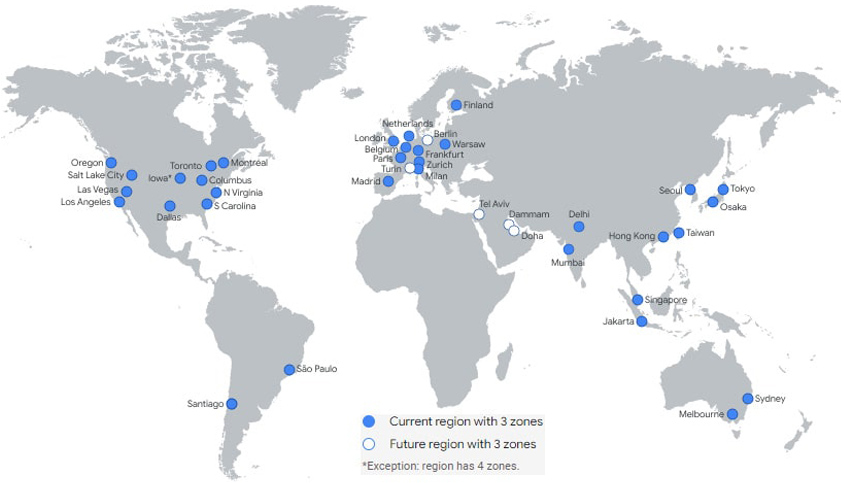 2022년 구글 리전 현황(출처: Dgtl Infra)11
2022년 구글 리전 현황(출처: Dgtl Infra)11
글로벌 서비스를 제공해야 하거나 해외 법인 등 제공할 대상이 세계에 분산되어 있는 경우 별도 네트워크 구성없이 제공할 데이터를 가장 가까운 리전에 배치함으로써 성능 이슈 없이 데이터에 접근할 수 있는 기반을 마련할 수 있습니다.
클라우드상에 공개 데이터 세트를 구성하고 연계도 가능합니다. 이를 통해 기업은 내부 데이터와 외부 데이터를 연결해 새로운 인사이트를 도출할 수 있습니다. 예를 들어, 구글의 경우 마켓 플레이스를 통해 제공하는 COVID-19, 비트코인 등의 공개 데이터 세트를 DW 클라우드 서비스(Bigquery)에서 내부 데이터처럼 활용할 수 있습니다. 또한 기업 내 데이터를 가공 후 마켓 플레이스에 등록해 외부 공개도 가능합니다.
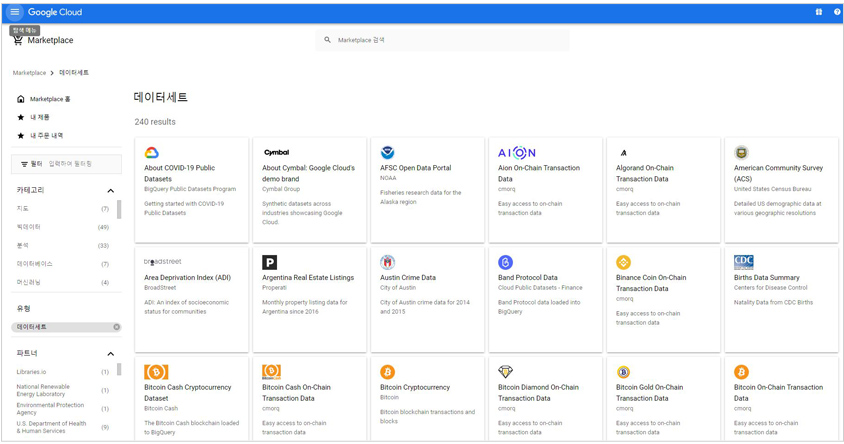 구글 마켓플레이스 데이터 세트 (출처: 구글)12
구글 마켓플레이스 데이터 세트 (출처: 구글)12
그 밖에 구글 BigQuery API와 같이 REST API 기반으로 DW 데이터를 처리하고 제공할 수 있어 다른 애플리케이션과의 통합을 용이하게 합니다.13
도입 시 고려 사항
다음은 클라우드 기반 DW 도입 시 고려해야 할 사항에 대해 살펴보겠습니다.
보안
클라우드 기반 DW의 경우 데이터가 기업 외부에 저장되기 때문에 다양한 데이터 보안 기능을 제공하고 있지만 적용하고자 하는 비즈니스의 보안 요건을 충족하는지에 대한 사전 검토는 매우 중요합니다.
클라우드 기반 DW는 데이터 보호를 위해 보관된 데이터를 암호화하고, 전송 간 네트워크 보안, 위험 탐지 기능 등을 제공하고 있으며 데이터 암호에 필요한 KEY를 고객이 직접 관리할 수도 있습니다. 더불어 데이터베이스의 이벤트들은 추적 관리될 수 있도록 Audit 로깅을 지원하고, Role을 기반으로 데이터의 행 레벨까지 접근 제어가 가능합니다.
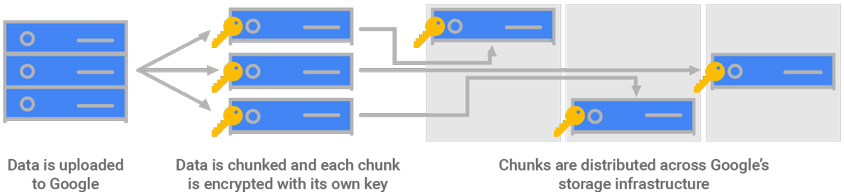
- Data is uploaded to Google ->
- sData is chunked and each chunk is encrypted with its own key ->
- Chunks are distributed across Google's storages infrastructure
예를 들어, 구글 BigQuery는 데이터 저장 단위별로 암호 키를 다르게 해 암호화 후 저장을 하며, Microsoft Synapse Analytics의 경우 기본적으로 AES 256 방식으로 모든 데이터를 자동으로 암호화합니다. 또한 Microsoft Defender for SQL을 통해 잠재적 위험을 감지하고 취약점을 사전에 예방할 수 있습니다.15 최근 아마존은 한국인터넷 진흥원(KISA)의 정보보호 및 개인정보보호 관리체계 인증(ISMS-P) 기준에 맞춰 AWS 서비스의 컴플라이언스 상태를 진단하고 관리할 수 있는 AWS Config 규정준수 팩을 출시하기도 하였습니다.16
거버넌스
기업 내 구축되는 온프레미스 기반 DW는 기업의 IT 거버넌스 기준에 맞춰 구축하기 용이하지만, 클라우드 기반 DW의 경우 이미 구성된 범용 서비스 위에 구축되기 때문에 기업 내 기 구축된 IT 체계와 통합이 어려울 수 있습니다. 물론 하나의 클라우드 플랫폼 위에 전체 시스템이 모두 구성이 된다면 클라우드에서 제공하는 거버넌스 서비스를 활용해 전체 IT 아키텍처에 대한 관리가 이루어질 수 있습니다.
하지만 현실적으로 기업 내 온프레미스 시스템이 클라우드 시스템과 같이 운영하는 경우가 많고, 2곳 이상의 클라우드 벤더 서비스를 사용하는 멀티 클라우드 체계로 운영될 수도 있기 때문에 클라우드 기반 DW 도입 전 기업 내 ITSM, 배치 플랫폼, 메타 시스템과의 연계 등 효과적으로 DW를 관리하기 위한 방안에 대한 검토가 필요합니다.
개발 방식의 변화
클라우드 기반 DW도 SQL 기반으로 구성되기 때문에 개발 언어상으로는 큰 차이가 없습니다. 하지만 노드의 확장, 병렬 처리 등 클라우드 기반 DW의 장점을 활용하기 위해서는 기존과 같이 하나의 SQL에 모든 로직을 넣어 작업 분리가 불가능한 개발 방식은 적합하지 않습니다. 독립적으로 병렬 처리할 수 있는 작업 단위로 데이터 처리 프로세스를 나누고 ETL 파이프라인을 구성해 분산된 컴퓨팅 자원을 효과적으로 활용할 수 있도록 구성해야 합니다.17
더불어 클라우드 기반 DW를 최적화하기 위해 클라우드 서비스가 제공하는 데이터 구조에 맞게 재구성해야 하는 경우도 생깁니다. 예를 들어 구글 BigQuery의 경우 DW 데이터 특징인 비정규성을 유지하는 대신 효율적인 데이터 관리를 위해 Nested and Repeated Columns을 지정할 수도 있고, Wildcard table을 활용해 하나의 쿼리로 여러 테이블을 조회할 수도 있습니다.18 19 또한 리전에 따라 사용할 수 있는 기능과 제약사항이 있기 때문에 리전별로 구현 방법이 달라질 수도 있습니다.
운영 방식의 변화
사용한 만큼 비용이 부과되는 클라우드 특성상 클라우드 서비스 비용 체계는 DW 운영 방식에 많은 영향을 미칩니다.
| 구분 | 스토리지 | 데이터 처리 |
|---|---|---|
| 구글 BigQuery | $20 per TB per month | $5 per TB |
| 아마존 Redshift | $306 per TB per month | 무료 |
예를 들어, 구글 BigQuery가 데이터 처리 위주로 비용이 설계되었다면, 아마존 Redshift는 스토리지 위주로 비용이 설계되어 있습니다.20 때문에 Redshift 기반 DW를 운영한다면 스토리지 효율화에 좀 더 집중해야 하는 반면, BigQuery는 데이터를 스캔하는 데 드는 비용을 줄이기 위해 최적의 파티션, 클러스터를 구성해야 합니다. 또한 쿼리 비용이 큰 보고서나 사용자들을 모니터링하고 지속적으로 개선해 나가야 합니다.
크로스 클라우드 (Cross-Cloud)
클라우드 서비스의 종속성에 대한 고려도 필요합니다. 예를 들어, 특정 클라우드 서비스에만 존재하는 기능을 활용한다면 최적화된 성능을 얻는 대신 다른 클라우드 서비스로 전환 시 어려움을 겪을 수도 있습니다. 때문에 클라우드 기반 DW를 고려한다면 추후 서비스 이전에 대한 고민도 같이 이루어져야 합니다.
이러한 고민들을 보완하기 위해 클라우드 업계에서도 변화가 일어나고 있습니다. 2020년 구글은 아마존, 애저 같은 다른 클라우드 서비스에서도 사용 가능한 BigQuery Omni를 발표하였습니다.21 또한 스노우플레이크(Snowflake), 데이터브릭스(Databricks)는 클라우드 서비스와 독립적으로 사용할 수 있는 클라우드 기반 DW 상품을 제공합니다. VMware는 클라우드 서비스와 독립적으로 관리, 보안 등의 시스템을 표준화하는 크로스 클라우드(Cross Cloud)를 제안하기도 하였습니다. 이와 같이 특정 클라우드 서비스의 종속성을 해소하기 위한 노력은 계속 진행될 것으로 보입니다.

마치며
지금까지 클라우드 기반 DW의 장점과 고려 사항을 살펴보았습니다. 클라우드 서비스가 모든 문제를 해결할 수는 없습니다. 하지만 클라우드 서비스를 통해 기존 DW의 한계를 넘어설 수 있다면, 기업의 데이터 가치는 더욱 향상될 것이며 이를 통해 비즈니스 혁신은 가속화될 것입니다.
References
1. Cloud Data Warehouse Market to grow by USD 10.42 bn | Technavio
(https://www.prnewswire.com/news-releases/cloud-data-warehouse-market-to-grow-by-usd-10-42-bn--technavio-301483850.html)
2. BigQuery 스토리지 개요 (https://cloud.google.com/bigquery/docs/storage_overview)
3. Amazon EC2 스팟 인스턴스 (https://aws.amazon.com/ko/ec2/spot/)
4. Use Amazon Redshift RA3 with managed storage in your modern data architecture
(https://aws.amazon.com/ko/blogs/big-data/use-amazon-redshift-ra3-with-managed-storage-in-your-modern-data-architecture/)
5. Dataflow (https://cloud.google.com/dataflow)
6. Data Lakehouse | databricks (https://databricks.com/glossary/data-lakehouse)
7. BigLake – What You Should Know About the GCP’s New Cross-Cloud Data Lake
(https://adswerve.com/blog/biglake-what-you-should-know-about-the-gcps-new-cross-cloud-data-lake/)
8. BigQuery for Big data engineers - Master Big Query Internals (https://www.udemy.com/course/bigquery/)
9. What is Azure Synapse Analytics? (https://docs.microsoft.com/en-us/azure/synapse-analytics/overview-what-is)
10. Explore Azure Synapse Studio (https://docs.microsoft.com/en-us/learn/modules/explore-azure-synapse-studio/)
11. Top 10 Cloud Service Providers Globally in 2022 (https://dgtlinfra.com/top-10-cloud-service-providers-2022/)
12. Cloud Marketplace 공개 데이터 세트 (https://console.cloud.google.com/marketplace/browse?filter=solution-type:dataset&_ga=2.29503355.510562023.1658617957-853571580.1654420949)
13. BigQuery API (https://cloud.google.com/bigquery/docs/reference/rest)
14. BigQuery 데이터 보안 및 거버넌스 개요 (https://cloud.google.com/bigquery/docs/data-governance)
15. Azure Synapse Analytics security white paper: Introduction (https://docs.microsoft.com/en-us/azure/synapse-analytics/guidance/security-white-paper-introduction)
16. ISMS-P 를 위한 AWS Config 규정 준수 팩 사용하기 (https://aws.amazon.com/ko/blogs/korea/aws-conformance-pack-for-k-isms-p-compliance/)
17. ETL PIPELINE – snowflake (https://www.snowflake.com/guides/etl-pipeline#:~:text=An%20ETL%20pipeline%20is%20the,and%20move%20it%20to%20another)
18. Specify nested and repeated columns in table schemas (https://cloud.google.com/bigquery/docs/nested-repeated)
19. Query multiple tables using a wildcard table (https://cloud.google.com/bigquery/docs/querying-wildcard-tables)
20. Redshift vs BigQuery - /integrate.io (https://www.integrate.io/blog/redshift-vs-bigquery-comprehensive-guide/#:~:text=BigQuery%20costs%20%2420%20per%20TB,unlimited%20processing%20on%20that%20storage)
21. [테크인사이드]구글 클라우드 승부수? 빅쿼리 독립을 주목하는 이유 (http://www.digitaltoday.co.kr/news/articleView.html?idxno=242145)
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에게 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의 없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
![]()

삼성SDS 클라우드서비스사업부 경영CI그룹
금융 데이터 분석 및 온톨로지 분야에 많은 관심을 가지고 있습니다.