머신러닝의 역사
 그림1 - Machine Learning
그림1 - Machine Learning출처 https://www.import.io/post/history-of-deep-learning/
머신러닝은 여러 산업 분야 및 연구에 있어서 매우 중요한 주제 중 하나입니다. 머신러닝은 1949년 Hebb이 Hebbian Learning Theory를 발표하는 것으로 시작되었습니다. 이후 1952년에 IBM에서 근무하던 Arthur Samuel은 최초의 머신러닝 프로그램이라 할 수 있는 체커 프로그램을 개발하였습니다. 경험으로부터 배우는 방법을 사용한 것입니다. 이때 그는 머신러닝을 명확히 프로그램하지 않고도 컴퓨터에 사고하는 능력을 주는 것으로 정의하였습니다.
1950년대부터 조건부 확률을 계산하는 방법의 하나인 Bayes 정리를 기초로 확률 기반의 분류기가 연구되었습니다. 알고리즘은 기본적으로 ‘모든 특성값은 서로 독립임’을 가정합니다. 예를 들어, 특정 과일을 오렌지로 분류하게 하는 특성들(둥글다, 노랗다, 주먹 정도 크기) 등은 특성들 사이에서 연관성이 없음을 가정하고 각각의 특성들이 특정 과일이 오렌지일 확률에 독립적으로 기여하는 것으로 간주합니다. 이는 지도학습에서 매우 효율적으로 훈련될 수 있으며 단순한 디자인과 가정을 가지고도 많은 복잡한 상황에서 잘 작동합니다.
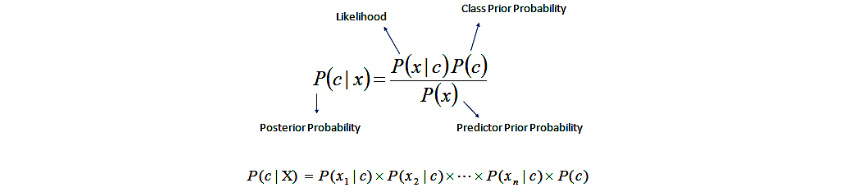 그림2 - Naive Bayes
그림2 - Naive Bayes출처http://uc-r.github.io/naive_bayes
1957년 Frank Rosenblatt는 Perceptron이라는 개념을 발표하였습니다. 이는 초기의 인공신경망으로서 다수의 입력으로부터 하나의 결과를 내는 알고리즘입니다. 실제 뇌를 구성하는 신경세포의 뉴런과 동작 방식이 비슷합니다. 그로부터 3년 뒤, Widrow, Hoff가 Delta Learning Rule을 발표하였고, 이는 Perceptron 훈련을 위한 실용적인 방법으로 사용되었습니다. 이 두 아이디어를 결합하여 더 나은 분류기를 만들었습니다. 하지만 Minsky Marvin은 XOR 문제에 Perceptron이 적합하지 않다고 주장하였고, 이로 인해 Neural Network는 1980년대까지 휴면기를 겪게 되었습니다.
 그림3 - XOR Problem
그림3 - XOR Problem출처 http://www.erogol.com/brief-history-machine-learning/
1981년 P. J. Werbos가 Multilayer Perceptron을 Back Propagation으로 계산하는 방법을 발표하였습니다. Back Propagation 방법은 이미 1970년대에 S. Linnainmaa에 의해 발견되었지만, Multilayer Perceptron의 등장과 더불어 더욱 발전하게 되었습니다. 따라서 Neural Network 연구가 다시 붐을 이루게 되었습니다.
1986년 R. Quinlan이 머신러닝의 주류가 된 Decision Tree라는 알고리즘을 발표하였습니다. 구체적으로 ID3라는 알고리즘을 발표하였고, 이 시기에 Decision Tree의 변종인 ID4, CART 등과 같은 알고리즘도 나오게 되었습니다. Decision Tree는 학습데이터를 가지고 여러 가지 Decision을 통해 이진 트리를 만드는 방법입니다. 이를 위해 여러 가지 방법으로 자료를 분할해야 하는데, 각각의 자료를 이진 분할 시 각 노드의 순도가 가장 높은 방향으로 분할을 하게 됩니다.
분할 방법에 따라 ID3, C4.5, C5.0, CART, CHAID 등 여러 가지가 있습니다. 데이터를 분할하기 전과 후의 변화를 Information Gain이라고 하는데 이 Information Gain이 증가하는 방향으로 분할을 합니다. 분할 후 각 노드의 순도를 계산하기 위해 Gini와 Entropy라는 개념을 사용하는데 이 값이 작을수록 순도가 높아지기 때문에 이 값이 작아지는 방향으로 데이터를 분할합니다.
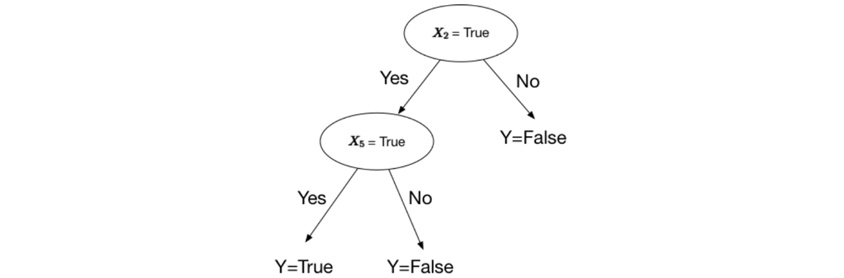 그림4 - Decision Tree
그림4 - Decision Tree출처 https://hackernoon.com/what-is-a-decision-tree-in-machine-learning-15ce51dc445d
이후 1995년에 Vapnik와 Cortes는 머신러닝 역사에서 한 획을 그은 Support Vector Machine(이하 SVM)을 발표하였습니다. SVM은 2개의 범주를 분류하는 이진 분류기로써 주어진 데이터를 바탕으로 새로운 카테고리가 어느 카테고리에 속하는지 판단하는 알고리즘입니다. 평면상에 데이터가 있다고 했을 때 두 카테고리를 가장 잘 분류할 수 있는 선을 찾는 방법으로써 선은 각 카테고리의 여백(Margin)이 최대화되도록 찾습니다. 이러한 선은 종종 찾기 힘들 때가 많기 때문에 데이터를 고차원 평면상으로 이동시켜서 초평면(이차원일 때는 선)을 찾는 것입니다. 이때 고차원으로 데이터를 이동시키기 위해 커널 함수를 사용합니다. 커널 함수를 사용한 SVM은 2000년에 발표되었습니다.
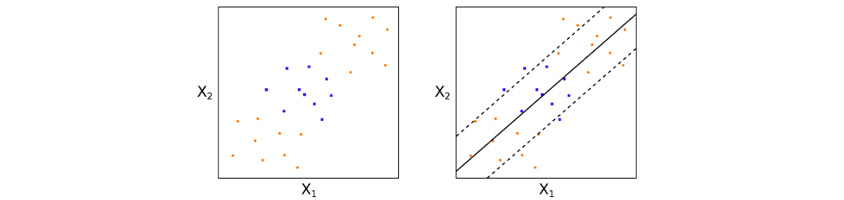 그림5 - SVM
그림5 - SVM출처 https://www.quantstart.com/articles/Support-Vector-Machines-A-Guide-for-Beginners
커널화한 SVM이 나오기 조금 전인 1997년에 Freund와 Schapire는 부스팅 앙상블 기법을 사용한 AdaBoost라는 알고리즘을 발표하였습니다. 앙상블 기법이란 여러 번의 반복된 분류기를 만들어 이를 종합하여 결론을 내리는 알고리즘을 말합니다. 이는 단일 분류기의 성능을 높이는 방법의 하나입니다. 부스팅 방법은 잘못 분류된 데이터에 대해 가중치를 주고 다시 분류기를 만들어내는 기법을 의미하는데, 이 방법으로 만들어진 알고리즘이 AdaBoost입니다.
1997년에 Leo Breiman은 Gradient Boosting이란 개념을 제안하였습니다. 부스팅이란 Cost Function에 Optimization 알고리즘을 적용한 것으로 해석할 수 있다고 하였습니다. 그리고 Jerome H. Friedman에 의해 Gradient Boosting 알고리즘이 더욱 발전하게 되었습니다. 이 알고리즘은 Tabular 포맷의 데이터에 대해 엄청난 성능을 보여주고 머신러닝 알고리즘 중에서도 가장 성능이 높다고 알려져 있습니다. Gradient Boosting은 여러 분류기의 합으로 되어 있고 이를 이용하여 손실함수(Loss Function)를 만들고, 이 손실함수를 최소화하는 파라미터를 찾기 위해 경사강하법(Gradient Descent) 방법을 이용하는 것을 말합니다.
이와 비슷한 시기인 1995년 IBM에서 근무하던 Tin Kam Ho가 일반적인 방법의 Random Decision Forests라는 개념을 최초로 발표하였으며, 2001년에 Leo Breiman이 이를 더욱 발전시킨 Random Forest라는 알고리즘을 발표하였습니다. 이는 앙상블 기법을 이용한 여러 개의 Decision Tree를 이용한 알고리즘으로 각각의 Decision Tree 생성 시 Feature와 테스트 데이터를 무작위로 뽑는 기법입니다. Random Forest 또한 경험적으로 과적합을 피할 수 있다는 것이 밝혀졌습니다. AdaBoost가 과적합과 이상치가 있는 데이터에 대해 약점을 보였지만, Random Forest는 이에 대해 뛰어난 성능을 보여주었습니다.
 그림6
그림6출처 http://www.thefactmachine.com/random-forests/
인공지능 발전사에서 가장 기본이 되는 머신러닝의 역사에 대해 각 알고리즘의 기본개념과 함께 살펴보았습니다. 많이 사용되는 알고리즘을 설명해 드린 것이고 분석에 관심 있으신 분들에게 도움이 되었으면 좋겠습니다.
참조
http://www.erogol.com/brief-history-machine-learning/
https://developer.ibm.com/articles/cc-beginner-guide-machine-learning-ai-cognitive/
https://en.wikipedia.org/wiki/Timeline_of_machine_learning
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의없이 2차 가공 및 영리적인 이용을 금하고 있습니다.

삼성SDS AI연구센터 분석플랫폼Lab
문기효 프로는 슈퍼컴퓨터를 이용한 수치해석 분야를 연구하여 박사학위를 취득하였습니다. 이를 응용하여 삼성SDS 분석플랫폼Lab에서 Brightics(삼성SDS AI 빅데이터 플랫폼)의 신기술을 연구개발하고 있습니다.