Let’s explore the importance of job scheduling in a cloud environment.
- 2022-09-30
- 작성자 Changju Lee



Job scheduler helps users efficiently allocate limited resources when multiple tasks are requested in the cloud, providing them seamless task performance experiences. Samsung SDS offers various efficient scheduler technologies, including Gang Scheduler, Bin-Packing Scheduler, FIFO Scheduler, and Multi-Queue Scheduler. We also research and develop a prediction-based Backfill Scheduler that predicts and schedules ML/DL work time. In this article, we will look at the scheduler technologies currently secured by Samsung SDS and the scheduler we researched and developed.
What is Job Scheduler?
A job scheduler is a method of efficiently allocating and prioritizing tasks when multiple jobs are requested within the cloud. For example, suppose you are working on job A, which requires four graphic processing units (GPU). In that case, a job scheduler will assign job A to a server with four available GPUs to maximize efficiency. If the job is assigned to a server with only two available GPUs, the job will not be performed, and the efficiency will rather decrease because it occupies two GPUs. It goes the same the other way around. If you assign a job that requires four GPUs to a server with eight GPUs, the rest of the four GPUs will become an idle resource, which leads to inefficiency. As you can see, the job scheduler supports users' seamless work in the cloud and enables the efficient allocation of limited resources.
[Wait!] What is job scheduling?
Job scheduling is a process of allocating jobs to available resources for the overall efficiency of the system and optimized operation. In computer science, job scheduling is generally used to allocate system resources, such as CPU time, memory, and disk space, to other processes or application programs.
What is deep learning job scheduling?
Deep learning job scheduling is a technology that improves GPU utilization and provides systematic services with limited resources by appropriately allocating users’ job requests.
As AI technology becomes prevalent, GPU resource utilization is also increasing. But for the efficient use of limited GPU resources, an appropriate scheduling technique is crucial.
Accordingly, Samsung SDS has secured various efficient scheduler technologies, such as Gang Scheduler, Bin-Packing Scheduler, FIFO Scheduler, and Multi-Queue Scheduler, and it is providing them to users, especially researchers and data scientists. We are also researching and developing a prediction-based Backfill Scheduler that predicts and schedules Machine Learning/Deep Learning (ML/DL) work time. Next, we will briefly look at the scheduler technologies we have developed so far.
Types of job schedulers Samsung SDS has secured
1) Gang Scheduler
The key function of the scheduler is to allocate a job where it can be performed. One of the important technologies in this case is the Gang Scheduler. It increases GPU efficiency by scheduling once GPU, CPU, and memory required for ML/DL job performance are all secured. The below diagrams offer a better understanding of the concept. With the existing scheduler, when job C is in the queue, it divides the job and operates without considering how many resources are needed and fails as a result. But with Gang Scheduler, even if there is an empty GPU, it determines the possibility of the performance and confirms the availability of resources before it starts and leads to success.
2) Bin-Packing Scheduler
Bin-Packing Scheduler can contribute positively to GPU utilization since distributed training jobs require multiple GPUs for performance. This scheduling method increases the success rate of the operation and minimizes the delay caused by the network speed by putting as many GPUs in one place as possible.
Looking at the diagram above, you can see that job D is divided and operated into two nodes because the existing scheduler did not arrange the GPUs in one place. This slows things down and uses the GPUs for long periods, significantly reducing efficiency, as data has to be sent back and forth from both sides. On the other hand, considering the Bin-Packing Scheduler below, since jobs are assigned to a single location, Job D benefits from being done in one place, leading to a reduction in performance time. This also improves GPU utilization since more jobs can be operated in the same amount of time.

-
Default method (Kubernetes) t CPU 4 job C CPU 3 job B CPU 2 job A CPU 1 A B Note <QUEUE> -
Default method (Kubernetes) t+1 CPU 4 job C1 job C2 CPU 3 job B CPU 2 job A CPU 1 job C3 A B Note <QUEUE> -
Job CFail!!
t+2
-
Gang Scheduler applied t CPU 4 job C CPU 3 job B CPU 2 job A CPU 1 A B Note <QUEUE> -
Gang Scheduler applied t+1 CPU 4 job C CPU 3 job B CPU 2 job A CPU 1 A B Note <QUEUE> -
Gang Scheduler applied t+2 CPU 4 job A CPU 3 job B CPU 2 CPU 1 A B Note <QUEUE>

-
Default method (Kubernetes) t CPU 4 job D CPU 3 job B CPU 2 CPU 1 job A job C A B Note <QUEUE> -
Default method (Kubernetes) t+1 CPU 4 CPU 3 job B job D CPU 2 job C CPU 1 job A A B Note <QUEUE> -
Default method (Kubernetes) t+2 CPU 4 jab D1 job D2 CPU 3 job B CPU 2 job C CPU 1 job A job A B Note <QUEUE>
-
Bin-packing scheduler applied t CPU 4 job D CPU 3 job B CPU 2 CPU 1 job A job C A B Note <QUEUE> -
Bin-packing scheduler applied t+1 CPU 4 job C CPU 3 job B job D CPU 2 CPU 1 job A A B Note <QUEUE> -
Bin-packing scheduler applied t+2 CPU 4 job D job C CPU 3 job B CPU 2 CPU 1 job A A B Note <QUEUE>
3) FIFO(First In First Out) Scheduler
FIFO Scheduler is a scheduler that processes tasks in the order of user's requests. Since this scheduler allocates resources based on the order of requests, it ensures a high level of satisfaction in terms of fairness, despite the relatively lower GPU efficiency. This is why FIFO Scheduler is used the most among other methods. On the diagram, you can see that the FIFO Scheduler allocates resources in the order in which tasks are requested, but many GPUs are idle. Particularly for Job 2 and Job 4, the significant number of requested GPUs causes a bottleneck in the queue, leading to an increase in the quantity of idle GPUs. Currently, Samsung SDS is using a Multi-Queue Scheduler to cope with these issues. We are also researching Backfill Scheduler based on performance time prediction to devise a scheduling that predicts performance time and allocates tasks that match idle resources.
4) Multi-Queue Scheduler
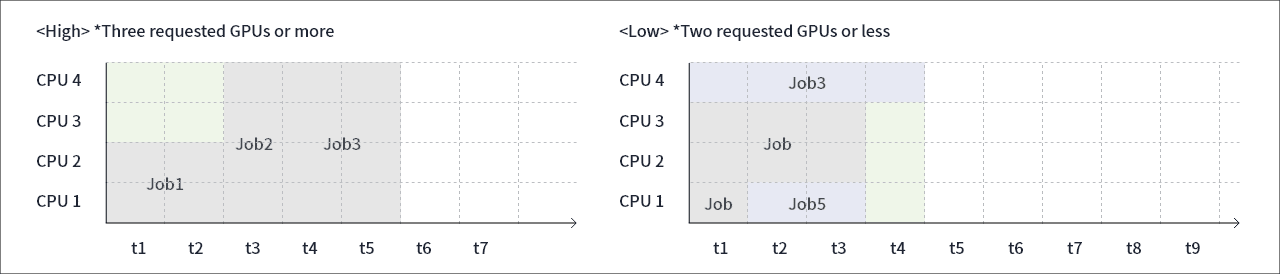
Multi-Queue Scheduler classifies tasks by high and low GPU requests. This method is configured to reduce the bottleneck caused by requesting resource-heavy operations, which reduces the number of idle GPUs and increases GPU efficiency. As shown in the diagram, the number of idle GPUs can be reduced by creating and operating the “High” queue when more than three GPUs are requested and the “Low” Queue when less than two GPUs are requested.
Another advantage of the Multi-Queue Scheduler is that it understands the nature of queued tasks. When tasks with lots of resource requests are stacked, more GPUs are allocated to the “High” queue to increase GPU efficiency.
When this method was applied in an actual case, the average queue time of a task was reduced from 32.3 hours to 5.77 hours, compared to the FIFO Scheduler, and the GPU usage efficiency was also improved by 20%. GPU usage efficiency is a metric that indicates the amount of idle GPU time generated when considering 100 GPUs running for 100 hours. If all 100 GPUs were active for the entire 100 hours, the efficiency would be 100%. If, for example, 40 GPUs remained idle for a total of 50 hours, the efficiency would be 80%.

- Running
- Waiting
- Unused
| CPU 4 | job 2 | job 4 | |||||||||||||
| CPU 3 | job |
job | job 1 | ||||||||||||
| CPU 2 | |||||||||||||||
| CPU 1 | job 3 | job5 | |||||||||||||
| t1 | t2 | t3 | t4 | t5 | t6 | t7 | t8 | t9 | t10 | t11 | t12 | t13 | t14 | t15 | |
-
hight : Three requested GPUs or more CPU 4 job 2 job 3 CPU 3 CPU 2 job 1 CPU 1 t1 t2 t3 t4 t5 t6 t7 -
Low : Two requested GPUs or less CPU 4 job 3 CPU 3 job job CPU 2 CPU 1 job 5 t1 t2 t3 t4 t5 t6 t7 t8 t9

| CPU 4 | job 2 | job 6 | job 10 | ||||||||||||
| CPU 3 | job |
job | job 8 | ||||||||||||
| CPU 2 | job 9 | job 11 | job 1 | job 2 | |||||||||||
| CPU 1 | job 7 | job 12 | |||||||||||||
| t1 | t2 | t3 | t4 | t5 | t6 | t7 | t8 | t9 | t10 | t11 | t12 | t13 | t14 | t15 | |

| CPU 4 | job 8 | job 2 | job 12 | job 4 | job 6 | ||||||||||
| CPU 3 | job |
job | job 1 | job 10 | job 5 | ||||||||||
| CPU 2 | job 3 | ||||||||||||||
| CPU 1 | job 9 | ||||||||||||||
| t1 | t2 | t3 | t4 | t5 | t6 | t7 | t8 | t9 | t10 | t11 | t12 | t13 | t14 | t15 | |
Technologies, such as scheduler, storage, and DevOps, secured by Samsung SDS will maximize the convenience of complex ML/DL while reducing the price burden.
Introduction to the scheduler researched and developed by Samsung SDS Research Center
Predicting the execution time of ML/DL
Samsung SDS has secured a computational amount-based prediction model that calculates and sums the computational amount of each task to predict the execution time of ML/DL tasks. We are also researching and developing a data-based prediction model that measures the execution time of each case and accumulates data to make data-based predictions. The calculation is quite complicated, and the execution time may vary even with the same amount of calculation depending on the type, number, and network environment of the GPU. Therefore, we are conducting research to improve the prediction accuracy of execution time by combining the computational amount-based model and the data-based model.
Backfill Scheduler based on the execution time prediction
Execution time prediction-based Backfill Scheduler is a scheduling method that estimates the execution time of ML/DL jobs to utilize idle resources. This presents the benefit of making use of idle GPUs, which addresses the limitation found in the FIFO scheduler. In this way, both GPU usage efficiency and user fairness are guaranteed. However, we must predict the execution time of ML/DL jobs. If scheduled by considering the idle resources at the moment without considering time, the jobs with fewer requested resources are processed preferentially while the queue time of jobs with larger resources requested increases. Samsung SDS is researching and developing a prediction-based Backfill Scheduler for job execution, aiming to improve user convenience and GPU efficiency.
Resource allocation comparison of the existing Backfill Scheduler and the execution time prediction-based Backfill Scheduler
The first chart depicts the resource allocation approach of the original Backfill Scheduler, while the second chart illustrates the resource allocation approach of the Backfill Scheduler that predicts job execution time. With the original scheduler, a job requiring a single GPU was performed whenever there were available resources so that jobs with a small number of requests, such as jobs 6-12, were performed first while the execution times of jobs 1 and 2 were delayed, even though they were requested earlier. On the other hand, the Backfill Scheduler that predicts job execution time considers idle resources and time generated by the existing FIFO scheduling method and allocates jobs suitable for the situation. As a result, it completes its tasks without affecting the execution of jobs 1 and 2. With the Backfill Scheduler based on the execution time prediction, you can guarantee the user's task sequence and utilize the idle resources that occur in between, which fulfills both user satisfaction and increase GPU efficiency.
Samsung SDS provides optimal services for ML/DL
Samsung SDS is providing cloud services optimized for ML/DL in line with the AI era. Technologies, such as Scheduler, Storage, and DevOps, secured by Samsung SDS will maximize the convenience of complex ML/DL while reducing the price burden. Furthermore, the scheduler technologies can reduce queue time and guarantee fairness by boosting efficiency with limited GPUs in the cloud environment. Our technology is ready to satisfy your needs.
Let’s learn more about the AI service from Samsung Cloud Platform (SCP), a reliable cloud service for enterprises.
Go to Samsung Cloud Platform (SCP) >
Check out AI/ML products on Samsung Cloud Platform.
-
AI/ML
Easy and simple ML/DL model building and learning
- Changju Lee / Samsung SDS
- Based on his experience in financial time series data modeling and blockchain platform design, Changju Lee is researching to develop an efficient and easy-to-use scheduler using data-based deep learning modeling.