
Data Wrangler
Easily and Quickly Search Raw Data and Convert into Visual Data Form
Overview


-
Preparation of Visual Data
A self-service model of Data Wrangler makes pre-processing of data easy.
Through data exploration and loading, Data Wrangler provides data processing function that handles data correction and conversion. -
Search based on Data Profiling
Data profiling helps with identifying information such as data distribution status, data validation test and statistics. A comprehensive view of a given data set helps decide data cleansing target and processing type. By checking data distribution by column and invalid data, Data Wrangler suggests data correction, while returning maximum/minimum/mode/mean value.
-
Recipe Management
Data Wrangler performs communication for jobs. For instance, it checks converted script by saving and managing data conversion history. It also manages preloaded data and column conversion history.
-
Data Source Identification
Merging data from different sources is possible with Data Wrangler and the lineage diagram provides a graphic representation of the relationship between the recipe and the source of the converted data.
Service Architecture
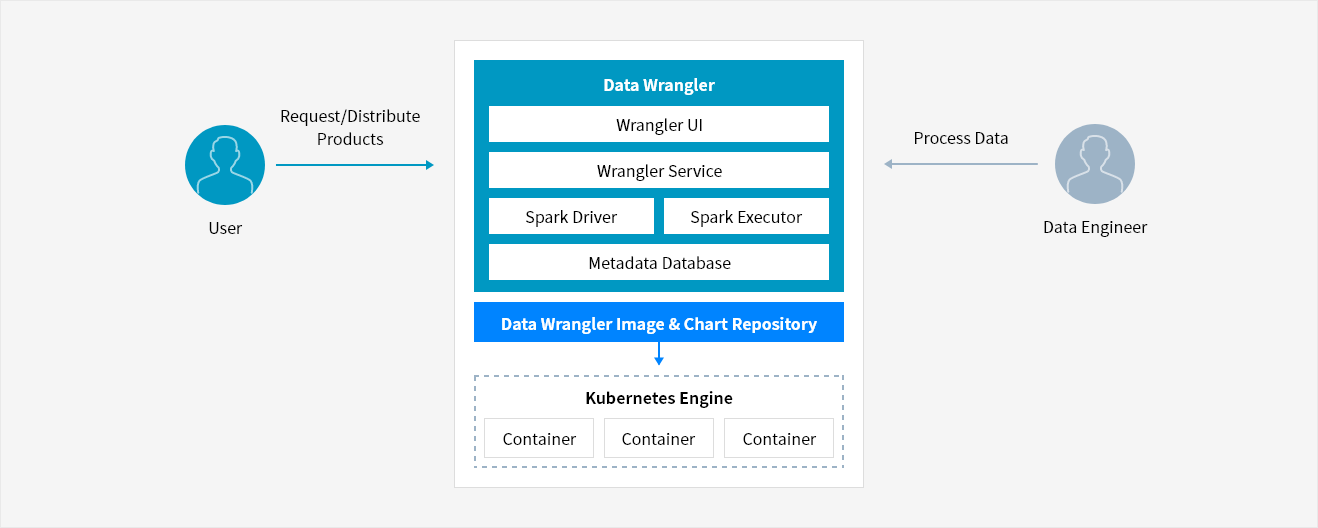
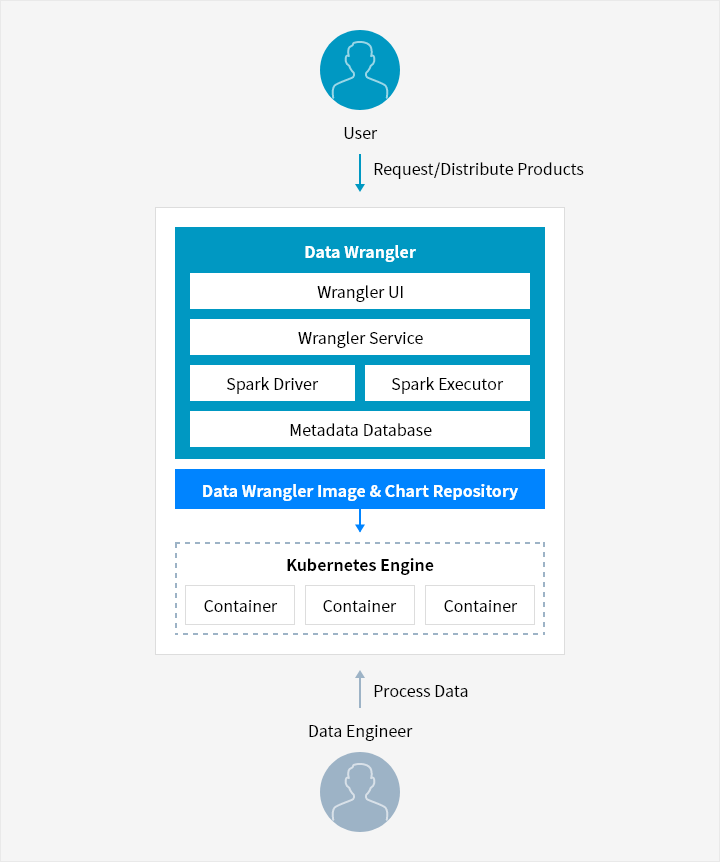
- User → Request/Distribute Products → ( Data Wrangler Image & Chart Repository: Data Wrangler → Kubernetes Engine ) ← Process Data ← Data Engineer
-
- Data Wrangler Image & Chart Repository
-
- Data Wrangler
- Wrangler UI
- Wrangler Service
- Spark Driver, Spark Executor
- Metadata Database
-
- Kubernetes Engine: Container, Container, Container
Key Features
-
Easy installation
- Apply Data Wrangler and Kubernetes engine all at once
- Kubernetes engine resources can be configured above the size of resources requested on Data Wrangler, preventing any errors caused by user mistake -
Integration with various data
- Uses schema information of connected data source (Hive schema, RDB schema)
- Load data using SQL
- Upload target data using local file feature -
Provide various data analysis function
- Group function : Count, sum, avg, min, max, first, last, countDistinct, sumDistinct, collect_list, collect_set, etc.
- Window function : Lag, lead, rank, dense_rank, row_number, etc.
- Use various default scalar function as well as function needed for data pre-processing and math function -
Management and monitoring of job
- Manage job, which applies recipe to the entire data and monitor execution status
- View job by status and name
- Monitor detailed status such as job list, status and execution time
Pricing
-
- Billing
- CPU usage time for Kubernetes Engine pods used by Data Wrangler
- Kubernetes Engine, Worker Node(VM), Storage usage charges separately
Whether you’re looking for a specific business solution or just need some questions answered, we’re here to help