
Data Catalog
Collection and Integrated Management of Metadata from Data Assets
Overview


-
Automated Metadata Collection
Data Catalog supports a data crawler, which collects metadata from data sources of various DBMS and Hive. Automated Data Crawler handles large data sets quickly and efficiently, and the mapped catalog helps draw useful insight for decision-making.
-
Quality of Data
Data Catalog provides a visual representation of the data source and data flow. Data Lineage provides a clear idea of where the data originated, how it has changed, and its final destination within the data pipeline, which ensures data consistency and quality while also helping to track errors.
-
Easy-to-use Integrated Search
Data Catalog offers integrated search, helping to locate data using various options with a single search. In addition, organizations can make more effective use of data assets by checking the access permissions of metadata and business metadata information registered by the user.
-
Data Classification
By setting up business terms and managing a glossary, potential stakeholders to data can easily access and understand data. The business glossary contains definitions, relationships with other data, data sources, and format, which allows users to understand the data classification system and discern data.
Service Architecture
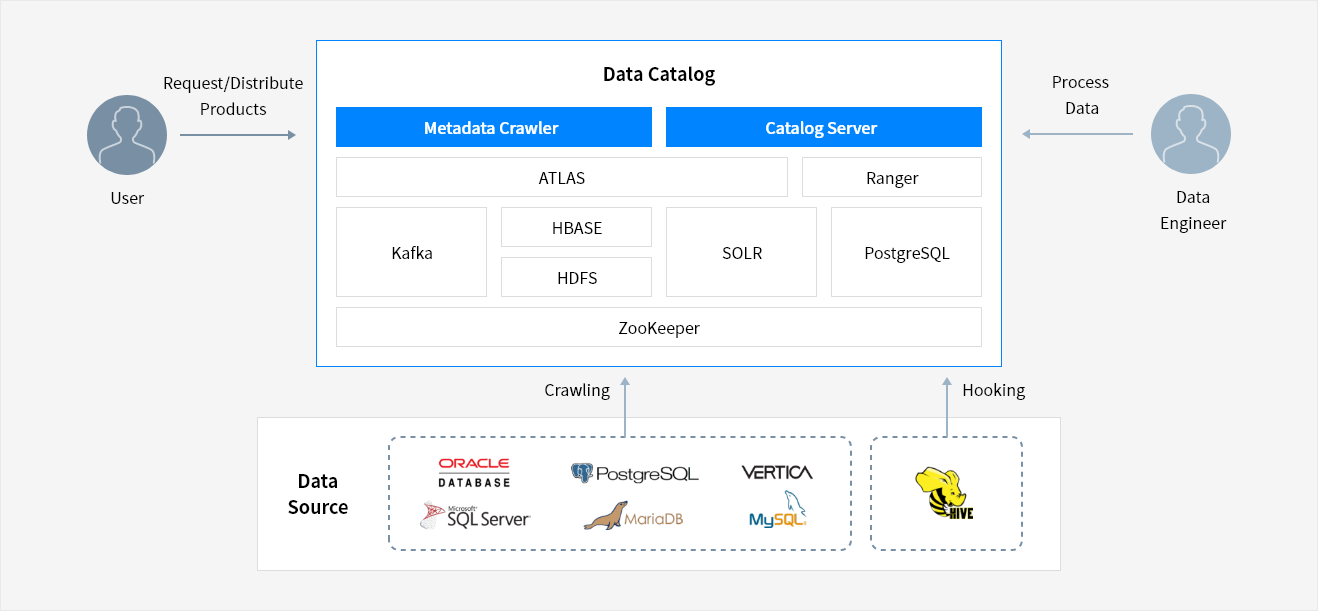
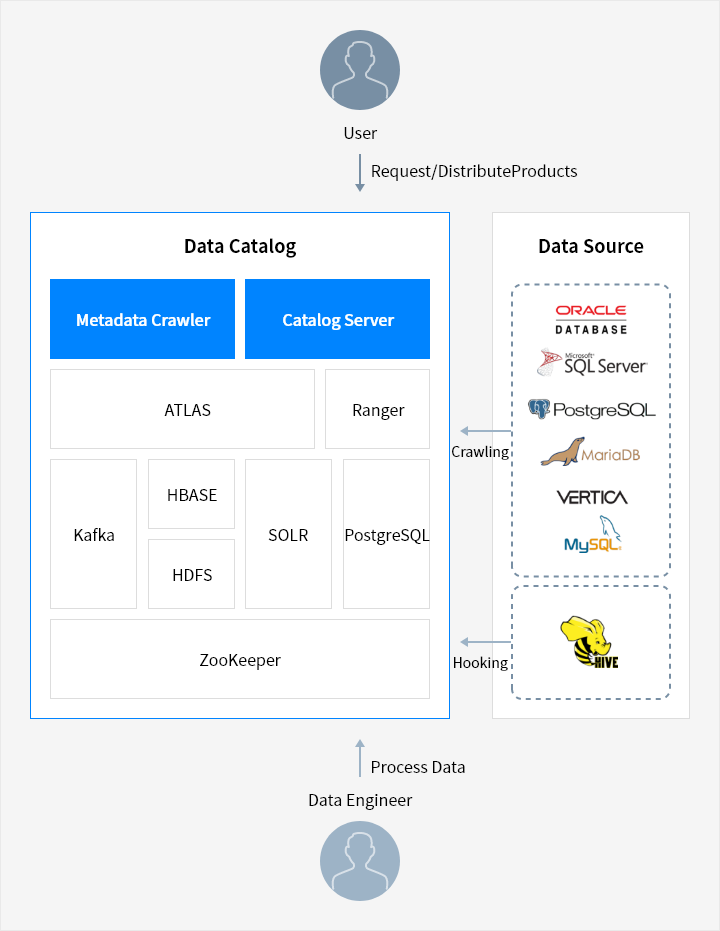
- User → Request/Distribute Products → Data Catalog ← Process Data ← Data Engineer
- Data Source Crawling → Data Catalog
- Data Source Hooking → Data Catalog
- Metadata Crawler: ATLAS, Ranger, Kafka, HBASE, HDFS, SOLR, PostgreSQL, ZooKeeper
- Catalog Server: ATLAS, Ranger, Kafka, HBASE, HDFS, SOLR, PostgreSQL, ZooKeeper
- Oracle DataBase, PostareSQL, Vertica, Microsoft SQL Server, MariaDB, MySQL
- HIVE
Key Features
-
Automated collection of metadata
- Meta crawler : Collect metadata from data source such as DB, schema, table, and columns
- Lineage crawler : Collect history information of data source
- Sample crawler : Collect sample metadata -
Check data lineage
- Provide a visual representation of data flow
- Manage table and schema change history -
Integrated search
- Search data using filters such as metadata, table name and tag
- Detailed lookup of table such as summary, columns, and lineage
- Search by filters such as role, owner, classification, and terms -
Data classification
- Discern key traits of assets
- Grouping for data protection
- Provide access control feature for metadata using tag policy
Pricing
-
- Billing
- Charged based on VM resources used by Data Catalog
- Charged separately for VM resources and storage
Whether you’re looking for a specific business solution or just need some questions answered, we’re here to help