loading...
Case Study: Samsung SDS Uses Retrieval Augmented Generation for Kubernetes Troubleshooting
NOV 18, 2024

As generative AI technology advances, many companies are actively trying to integrate generative AI into their services. Samsung SDS is also exploring new services that incorporate AI technology, and it is making various attempts to integrate them with existing services. This article will present AI-based service and technological components that can be applied to customer technical support tasks, as showcased at the Samsung SDS Gen AI Hackathon.
SKE-GPT, Cluster Diagnostic Tool for Kubernetes Troubleshooting
Analysis of the technical support records related to container products on the Samsung Cloud Platform (SCP) over the past year showed that approximately 68% of cases were resolved by users themselves through guides. Why were there so many inquiries that could be self-resolved? The answer could be found in the unique characteristics of the Kubernetes environment in which container products operate.
Kubernetes is an open-source container orchestration platform managed by the Linux Foundation. Cloud Service Providers (CSPs), such as AWS and Google, offer Kubernetes products that are restructured for their specific cloud environments, and SCP provides this service under the name "Kubernetes Engine" (hereinafter SKE or SCP Kubernetes Engine).
In the case of Kubernetes provided by CSP, user convenience can be enhanced with features and services integrated with the respective cloud platforms, but there is a disadvantage in that if a Kubernetes application fails to function due to issues with the integrated product, identifying the root cause can be quite challenging. The Samsung Cloud Platform Kubernetes Engine-GPT (SKE-GPT) was developed with a focus on addressing these user pain points.
SKE-GPT is an AI-based cluster diagnostic tool that quickly analyzes issues occurring in SCP’s Kubernetes Engine and offers accurate solutions. It consists of two main components: a diagnostic area that checks the status of the cluster and an analysis area that provides solutions for identified issues. In the diagnostic area, the status of workloads within the cluster is checked based on predefined rule sets, and the status of external SCP products associated with the cluster is also diagnosed if necessary. If an issue is detected in the diagnostic area, the solution using AI will be generated in the analysis area.
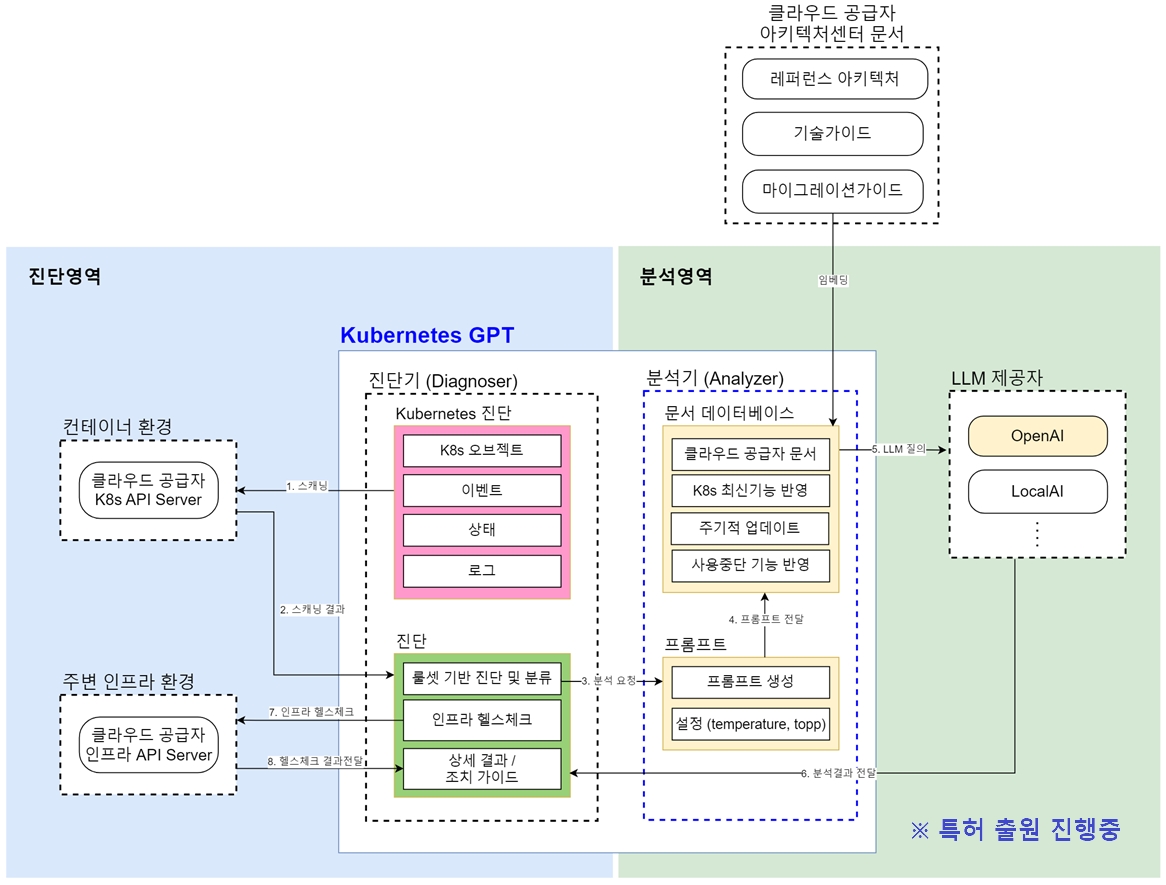 SKE-GPT conceptual architecture (Patent pending)
SKE-GPT conceptual architecture (Patent pending)
Kubernetes GPT
분석영역
분석기 (Analyzer))특허 출원 진행중
The key features of SKE-GPT are as follows:
- Simple Operation: Diagnoses the cluster status and provides solutions with simple commands via Command Line Interface (CLI).
- Powerful Workload Scanning: Identifies abnormal conditions by analyzing the event logs and YAML files of workloads and suggests solutions.
- SCP Product Diagnosis: Offers guidance on SCP Console settings by analyzing the status of SCP products (Load Balancer, File Storage, DNS, etc.) associated with the SKE service.
- Fast and Accurate Solution: Offers quick and precise solutions tailored to customer situations based on knowledge accumulated from years of operating and providing technical support for SKE.
The drawback of LLM models is that they cannot provide data that they haven't been trained on or real-time information. Then, how can SKE-GPT provide know-how-based solutions for technical support activities? To answer this question, it is necessary to understand the technology called "RAG."
Retrieval Augmented Generation (RAG) in SKE-GPT
RAG refers to a technology that enhances the accuracy of responses by providing additional external data in addition to the data learned by a Large Language Model (LLM). For better understanding, let’s compare the responses of an LLM with RAG applied and one without it. The following are the responses from two chatbots to the same question: "Tell me about SCP." Both chatbots used the GPT-3.5 Turbo model.
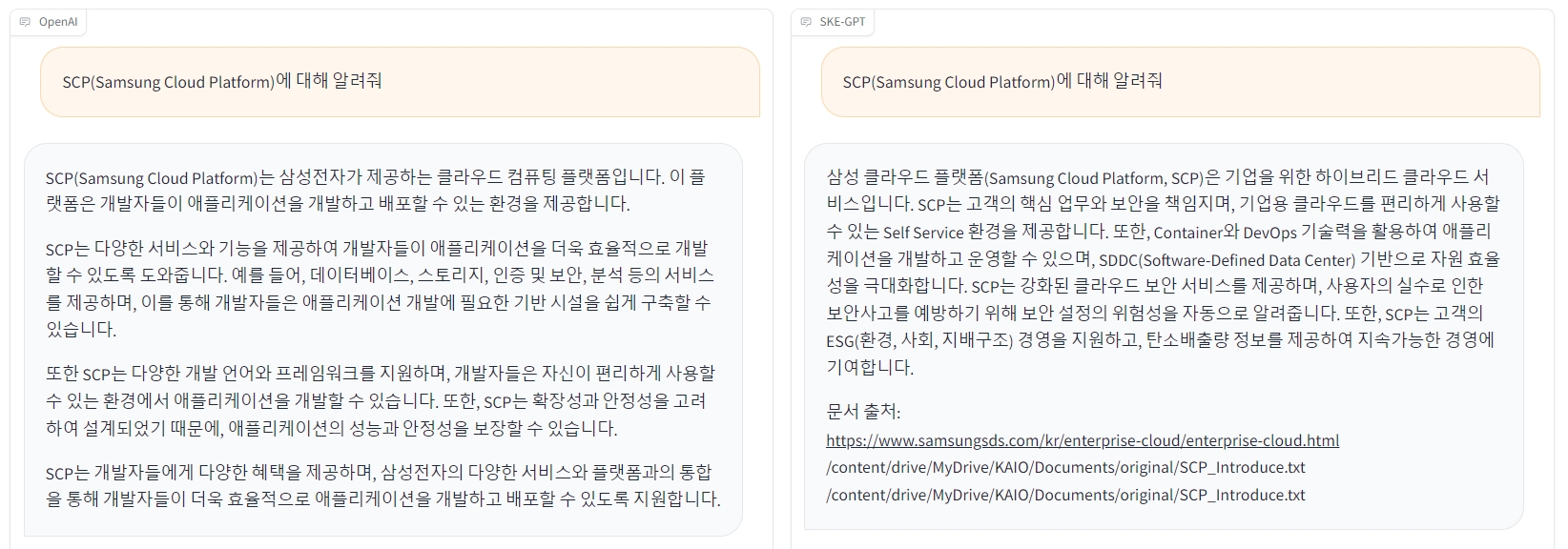 ▲ (Left) An answer from OpenAI GPT-3.5 Turbo / (Right) An answer from SKE-GPT with RAG
▲ (Left) An answer from OpenAI GPT-3.5 Turbo / (Right) An answer from SKE-GPT with RAG
Do you notice a difference between the responses? With the GPT-3.5 Turbo model, which was trained on data only up to 2021, it’s clear that the model is unable to deliver a response that aligns with the user’s intent based on its learning. Let’s explore the technical components essential for implementing RAG in more detail.
Typically, a RAG-based LLM application consists of two main components:
- Indexing
- Retrieval and Generation
1. Indexing
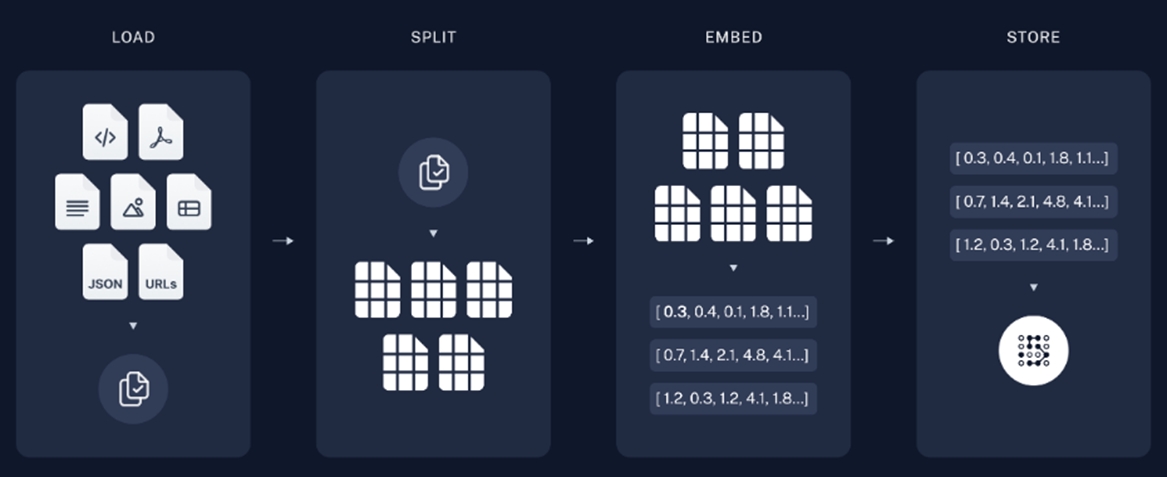 ▲ Source: https://python.langchain.com/docs/use_cases/question_answering
▲ Source: https://python.langchain.com/docs/use_cases/question_answering
Indexing is the component that organizes the data to be provided to the LLM. This divides various types of documents into appropriate sizes, derives the embedding vector value of each document, and stores it in the vector DB. The vector DB can generate values that are similar to the input sentences or words using its similarity search capabilities. RAG-based LLM applications use a similarity search feature to find documents similar to the user questions input into the chatbot and deliver them to the LLM. Let's explore the detailed modules for implementing the indexing component.
※ To help your understanding, the module names of the LangChain Framework are used, which is a tool for developing LLM applications.
Document Loaders
Document Loaders are responsible for reading external documents into the application to be delivered to the LLM. The types of documents include TXT, PDF, web pages, JSON, programming code (i.e., Python and Java), images, and CSV files. By using the Document Loaders module provided by LangChain, it can be verified that data is read in the form of a document structure consisting of page_content and metadata. SKE-GPT used the SCP introduction page from the official Samsung SDS website and the technical guide documents related to SKE in the SCP Architecture Center to gather RAG data on SCP.
Here is an example of loading a page with WebBaseLoader(); https://www.samsungsds.com/kr/enterprise-cloud/enterprise-cloud.html.
 ▲ Source: https://www.samsungsds.com/kr/enterprise-cloud/enterprise-cloud.html
▲ Source: https://www.samsungsds.com/kr/enterprise-cloud/enterprise-cloud.html
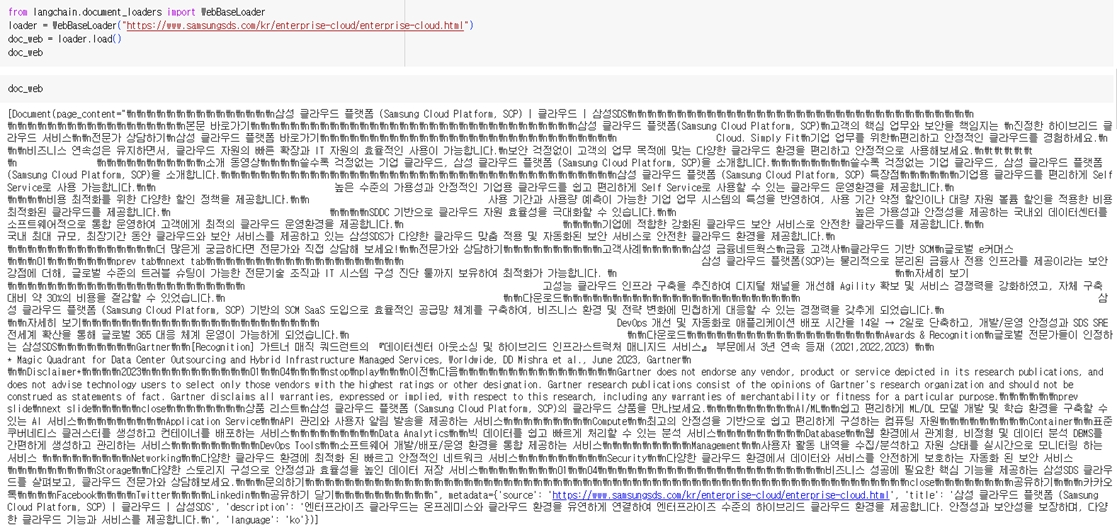 A screenshot loaded a page with WebBaseLoader() in Colab
A screenshot loaded a page with WebBaseLoader() in Colab
Text Splitters
LLM has a limit on the number of tokens that can be used in a single query. A token refers to the smallest unit that an LLM breaks sentences and words into for natural language processing. Typically, one token equals four letters, but this can vary depending on the LLM model. Token count limitations are critical for chatbots that generate responses to user queries. This is because the combined total of the tokens from the user query and the answer generated by the LLM must not exceed the maximum token limit that the LLM can use. When using RAG, the total token count includes not only the length of queries and answers but also the embedded documents obtained from the similarity search. Thus, it is crucial to segment the document effectively.
In the Text Splitter stage, the input documents are divided into multiple segments based on various criteria, such as token count and special characters, specific to the document format. The results obtained from this separation are referred to as "chunks," and these chunks are converted into embedding vector values by the embedding model in the next stage. SKE-GPT designated chunk_size and chunk_overlap through the RecursiveCharacterTextSplitter() By designating chunk_overlap, the common areas will be designated when splitting the document, helping the model better understand the sentences.
 ▲ An example of splitting a document using chunk_overlap (excerpt from https://cloud.samsungsds.com/serviceportal/assets/pdf/ko/SDS_Technical_Guide_Deployment_configuration_of_컨테이너_Registry_Image_v1.0_kor.pdf)
▲ An example of splitting a document using chunk_overlap (excerpt from https://cloud.samsungsds.com/serviceportal/assets/pdf/ko/SDS_Technical_Guide_Deployment_configuration_of_컨테이너_Registry_Image_v1.0_kor.pdf)
Text Embedding
Embedding refers to the process of representing natural language text in the form of a real-valued vector or the resulting output from this process. When it’s necessary to make a clear distinction, the result of the embedding process is called the "embedding vector." The model used to extract embeddings from documents is called an embedding model, and by using OpenAI’s embedding API, the embedding values can easily be obtained just by calling the API.
Vector Stores
The embedding vectors extracted in the previous step can be stored and managed in a vector database known as the vector store. Using the vector DB allows for easy retrieval of embeddings that are close to user queries through similarity searches.
 ▲ Types of vector stores
▲ Types of vector stores
| - | Dedicated Vector databases | Databases that support vector search |
|---|---|---|
| Open source (Apache 2.0 or MIT license) | chroma, marqo, vespa, drant, LanceDB, Milvus | OpenSearch, ClickHouse, PostgreSQL |
| Source available or commercial | Weaviate, Pinecone | elasticsearch, redis, ROCKSET, SingleStore |
2. Retrieval and Generation
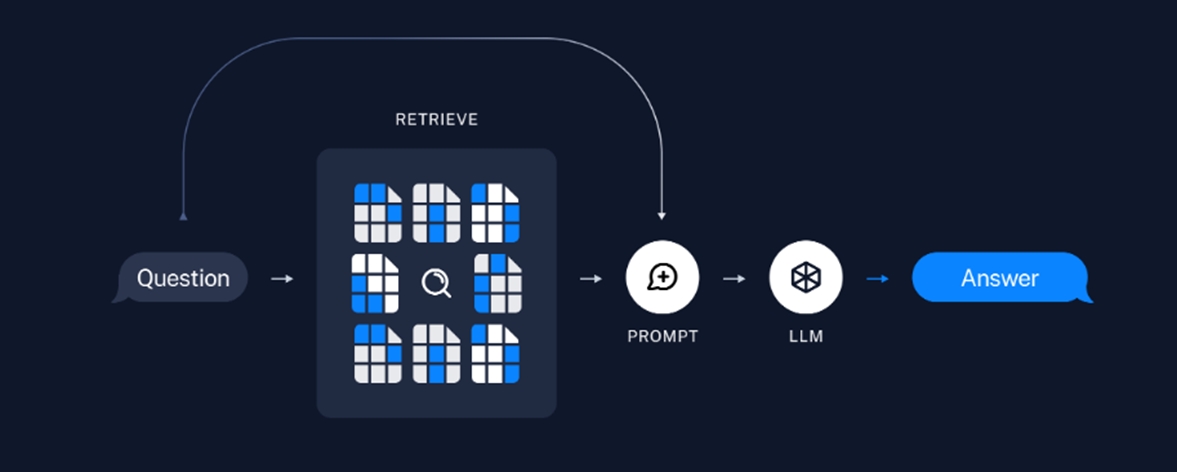 ▲ Source: https://python.langchain.com/docs/use_cases/question_answering
▲ Source: https://python.langchain.com/docs/use_cases/question_answering
The retrieval and generation component consists of the retrieve stage, which searches for documents similar to the user’s question in the vector store, and the generation stage, which creates prompts to query the LLM.
Retrievers
Retrieve means “to search,” and in RAG, it refers to the process of searching for documents in the vector store that are similar to the query. Retriever generates a prompt using the search results from the vector store along with the user question and sends it to the LLM. The retrieved documents at this point are included as context within the prompt statement. Using the retriever allows for searches customized to the specific features of the application. To enrich the results of the retriever that performs similarity-based searches, the “Maximum Marginal Relevance (MMR) Search” option can be used. The MMR option can be set to minimize the similarity between the retrieved documents, enabling the LLM to reference a more diverse range of data. Conversely, for applications where the accuracy of information is crucial, you can use the “Similarity Score Threshold” to ensure that only documents with a similarity score above a certain value are retrieved in the search results. The "Score Threshold" refers to the similarity score, which can take a decimal value between 0 and 1. A score closer to 1 indicates a higher similarity for the document.
Generate
In the Generate phase, the answer received by delivering the previously created prompt to LLM is sent to the user. While referred to as LLM, a chat model may also be used depending on the application. The flow of applications that apply RAG as explained so far can be summarized as follows:
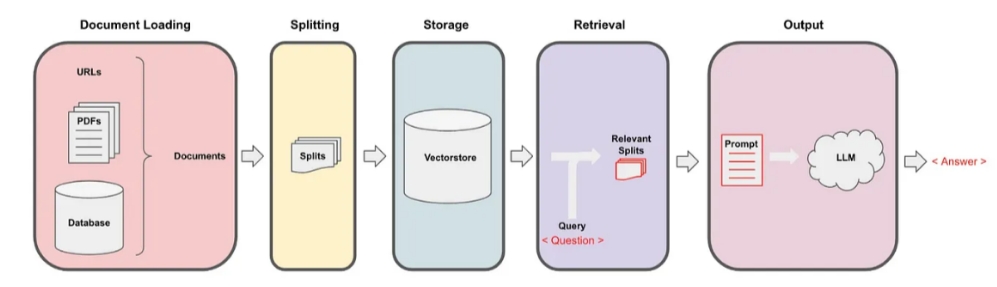 ▲ Source: https://medium.com/@onkarmishra/using-langchain-for-question-answering-on-own-data-3af0a82789ed
▲ Source: https://medium.com/@onkarmishra/using-langchain-for-question-answering-on-own-data-3af0a82789ed
Document Loading
URLs, PDFs, Database > Documents
Splititing
SplitsStorage
VectorstoreRetreval
Query Question
Relevant Splits
Output
Prompt > LLMAnswer
Benefits of RAG Tailored for Enterprise
With rapidly evolving AI technologies, RAG is expected to become a core feature of AI-based services. In the future, RAG will contribute to processing rich and diverse information by incorporating multi-modal features that process various forms of data, such as images, voices, and videos as well as text. However, there are also factors to consider. Since the data handled by RAG contains sensitive internal information, it is essential to ensure not only data encryption but also the stability of RAG components, such as vector stores, embedding models, and LLMs, to prevent any external exposure. If RAG-based AI technology is used with consideration of these factors, companies can enhance productivity and strengthen knowledge sharing and collaboration. For instance, unified knowledge dissemination can be facilitated through knowledge search using RAG. Furthermore, it can enhance the efficiency of document creation using internal templates and automate the processes of information collection and data analysis, leading to improved business operations. By effectively using RAG, companies can gain a competitive advantage through improved decision-making and service.
# References
[1] https://python.langchain.com/docs/use_cases/question_answering
[2] https://cloud.samsungsds.com/serviceportal/assets/pdf/ko/SDS_Technical_Guide_Deployment_configuration_of_컨테이너_Registry_Image_v1.0_kor.pdf
[3] Why You Shouldn’t Invest In Vector Databases? | by Yingjun Wu | Data Engineer Things (det.life)
[4] https://medium.com/@onkarmishra/using-LangChain-for-question-answering-on-own-data-3af0a82789ed
▶ This content is protected by the Copyright Act and is owned by the author or creator.
▶ Secondary processing and commercial use of the content without the author/creator's permission is prohibited.