
AI 콘텐츠와 표절 문제
최근 프로토타이핑 디자인 협업툴인 피그마(Figma.com)가 ‘피그마 AI’라는 생성형 AI 기능을 발표하자마자 그 기능을 비활성화했다. [1] 피그마 AI는 자연어 프롬프트만으로 높은 수준의 UI화면을 즉시 생성해 주는 획기적인 기능이다. 예를 들어, “치킨 볶음밥 요리법이 담긴 웹디자인을 만들어줘"라고 입력하면, 적절한 이미지와 구성요소를 갖추어 디자인을 하고, 사용한 언어를 다른 언어로 번역까지 실행한다. 그러나 발표 즉시 피그마 AI의 디자인이 애플의 날씨 앱 디자인을 모방했다는 주장이 발생했고, 저작권 문제로 인해 서둘러 기능을 비활성화했지만 비난을 피하지는 못했다.[2]
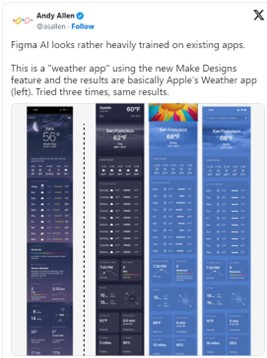 [그림 1] 피그마AI가 애플의 디자인을 모방했다는 주장 (출처: x.com)
[그림 1] 피그마AI가 애플의 디자인을 모방했다는 주장 (출처: x.com)
ChatGPT로 뜨거워진 생성형 AI의 등장으로 인해 피그마뿐만 아니라, 사진으로 동영상을 생성하는 라이브포트레이트(Liveportrait.org), 음악을 생성하는 사운드풀(Soundful.com)과 같은 다양한 AI 서비스가 출시하여 이제는 텍스트, 음원, 이미지, 동영상 등 모든 분야에서 콘텐츠를 쉽게 생성하는 것이 가능해졌다. 하지만 콘텐츠를 제작하는 것이 편리해지는 만큼 동시에 AI로 인한 표절 문제도 심각해지고 있다. 온라인 표절 검사 서비스인 턴잇인(Turnitin.com)의 연구에 따르면 2023년 4월 이후 턴잇인 플랫폼에 제출된 2억 개의 논문 중 2200만 개의 논문에서 내용의 최소 20%가 AI에 의해 생성된 콘텐츠인 것이 발견됐다. 즉, 학생의 약 11%가 표절했다는 것을 의미한다.[3]
이외에도 많은 분야에서 AI 표절에 대한 기사를 어렵지 않게 확인할 수 있다. 작년 뉴욕타임스(nytimes.com)는 900억 달러의 기업가치를 보유한 OpenAI에게 최대 4500억 달러의 소송을 청구했다. 뉴욕타임스는 OpenAI가 이들의 기사를 모델 학습에 무단으로 사용하였고, 원본 기사와 매우 흡사하거나 거의 일치하는 기사를 산출물로 생성했다고 문제를 제기했다.[4] 뉴욕타임스 외에도 신문사, 유명 작가 등 2022년 말부터 1년간 AI표절과 관련하여 OpenAI에게 청구된 소송은 12건에 달한다. 또한, AI 스타트업 루마(lumalabs.ai)는 자사의 동영상 생성 AI로 제작한 짧은 영상을 공개했는데, 이 영상 속 캐릭터가 월트디즈니와 픽사의 ‘몬스터 주식회사' 캐릭터와 흡사하여 논란이 되었다.[5]
또 다른 심각한 부분은 단순한 저작권, 표절 문제에 더해 보안의 우려가 커지고 있다. Guardian Australia의 한 기자가 AI로 생성한 본인의 목소리를 사용하여 호주 정부가 설립한 복지 통합 서비스인 Centrelink에 접근할 수 있음을 증명하였다.[6] 집계가 되고 있지는 않으나 금융 시스템에서 AI 복제 음성이 음성 인증 시스템을 통과하는 사례가 증가하고 있다. 이처럼 AI 표절 문제는 점점 심각한 수준으로 변화하고 있다.
AI 표절의 정의와 범위
AI 표절(AI plagiarism)이란 인공지능이 생성한 텍스트, 이미지, 비디오, 음원과 같은 콘텐츠가 기존에 존재하던 다른 자료를 허가 없이 무단으로 복제하거나 원작자의 콘텐츠로 보이게끔 유사하게 변형한 것을 의미한다. 생성형 AI는 누구나 쉽게 접근하여 콘텐츠를 생성하고 사용할 수 있기 때문에 저작권 침해 또는 표절 문제가 태생적으로 쉽게 발생한다. AI표절은 법적 문제뿐만 아니라 의도와는 상관없이 창작자의 권리를 침해하여 상업적 손해를 야기하거나 창작 동기를 저하시킬 수 있다. 또한 윤리적 문제를 일으켜 학문의 경우 신뢰도와 정확성을 떨어뜨릴 수 있다. 이를 해결하기 위해선 적절한 탐지 도구가 필요하고 기업과 사용자 모두 높은 의식 수준이 필요하다. 기업은 AI 표절을 사전에 방지하기 위해 먼저 인공지능 개발에 사용한 데이터가 합법적으로 수집한 데이터인지 선제적으로 검토할 필요가 있다. 우리가 흔히 접근할 수 있는 뉴스 기사, 사진 또는 그림, 음원 모두 창작물이고 대부분 저작권이 존재한다. 기존 창작물을 생성형 AI 모델의 데이터 학습에 사용했다면 당연히 원본과 흡사한 스타일의 콘텐츠가 생성되어 저작권 문제가 생길 수 있다.
검색과 LLM을 결합한 서비스로 인기가 있는 퍼플렉시티(Perplexity.ai)는 언론사로부터 이들의 AI가 불법적인 웹 스크래핑과 저작권 침해를 했다고 비난받았다.[7] 퍼플렉시티 AI가 로봇 배제 표준(Robots Exclusion Protocol)을 위반하고 사이트에서 데이터를 수집하여 사용했다고 보도했다. 퍼플렉시티는 저작권 법의 공정 이용 범위 내에서 윤리적 기준을 준수하였다고 반박했지만 AI 표절 문제로 이어지는 것은 피할 수 없다. 허가 없이 수집된 콘텐츠는 표절된 산출물을 생성할 수 있기 때문에 AI 모델 학습 단계에서부터 주의 깊게 살펴보아야 한다.
미국의 소셜 뉴스 플랫폼 레딧(Reddit.com)은 이와 같은 상황으로부터 자사의 콘텐츠 저작권을 지키기 위해 로봇 배제 표준을 적용했다.[8] AI 크롤러가 레딧의 콘텐츠를 사용하려고 할 때, 접근을 차단하거나 비용을 부과하는 방향으로 자사의 콘텐츠와 제작자들의 저작권을 보호한다.
또한 생성형 AI 서비스 사용자 또한 AI 생성 콘텐츠 여부를 주의 깊게 확인하고 이용해야 한다. 이것은 생성형 AI를 활용할 때, 이미 존재하는 저작물과 유사한 산출물이 만들어질 가능성을 인지하고 있어야 한다는 의미이다. AI 생성 콘텐츠를 공유하고 배포할 때 저작권 침해나 부정경쟁 문제가 발생할 수 있기 때문에 이용 목적에 맞게 철저한 검수 과정을 거치는 것이 중요하다.
소비자의 생성 콘텐츠 식별과 바람직한 사용을 위해 메타는 AI 생성 콘텐츠의 경우 “AI Info”라는 태그를 붙여 생성 여부를 명확히 표시한다. 유튜브의 경우엔 AI 표절이 야기하는 문제를 방지하기 위해 최근 사용자가 자신의 얼굴이나 목소리를 모방한 AI 콘텐츠를 발견할 경우 제거 요청을 할 수 있도록 하였다.[9] 이와 같은 사례처럼 생성형 AI의 콘텐츠가 공유되는 플랫폼이라면 ‘책임 있는 AI’를 위해 사용자가 AI 콘텐츠 생성 콘텐츠를 식별할 수 기능을 지원하는 것이 필요하다.
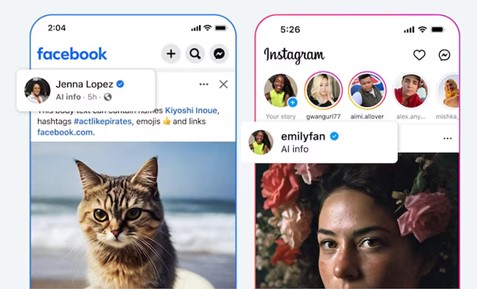 [그림 2] 페이스북과 인스타그램에 붙여진 “AI Info” 태그 (출처: Meta)
[그림 2] 페이스북과 인스타그램에 붙여진 “AI Info” 태그 (출처: Meta)
AI 표절 탐지 기술
AI 생성 콘텐츠 탐지기의 주요 프로세스는 콘텐츠 생성 기술과 마찬가지로 머신러닝과 자연어처리 기술이 중심적인 역할을 한다. 머신러닝은 대규모 데이터 세트에서 문장 구조, 맥락적 일관성 등 여러 패턴을 식별하여, 유사도를 측정한다. 자연어 처리 기술은 생성형 AI의 기술적 특성에서 파생되는 언어적, 구조적 특징을 찾아내어 생성 여부를 판단한다. AI로 생성한 콘텐츠는 인간만큼 창의적이거나 스타일적으로 풍부하지 않을 수 있다. 따라서 제공된 텍스트의 의미와 맥락의 단조로움 등은 생성 콘텐츠를 찾아내는 주요 단서가 된다. 이와 같이 머신러닝과 자연어 처리를 기술 기반으로 다음과 같이 세분화된 기술을 활용해 AI 생성 콘텐츠를 검출한다.
분류기 (Classifier)
분류 기능은 학습한 데이터 세트를 바탕으로 AI 생성 콘텐츠 여부를 판단한다. 이미 레이블이 지정된 학습 데이터에 기반하는 경우와 웹 상에 존재하는 데이터 등 비지도(unsupervised) 데이터를 추가 활용하여 표절 여부를 추론하는 경우가 있다. 분류기는 콘텐츠의 톤, 스타일, 문법적인 특징 등을 식별한 뒤, 일반적인 패턴을 비교하여 표절여부를 판단한다. 학습한 데이터에 따라 잘못된 예측 결과를 내기도 하므로, 분류기에 지속적으로 학습한 데이터를 업데이트하는 노력이 필요하다.
임베딩 (Embedding)
임베딩은 단어나 어구를 벡터 데이터베이스에 배치하는 방식이다. 여러 차원의 공간 내에서 유사한 의미를 가진 단어들이 서로 가깝게 배치되며, 그 거리를 수치적으로 표현한다. 이렇게 형성된 의미와 벡터화된 수치는 단어의 빈도, 언어 패턴, 구조 분석, 의미 분석 등에 활용될 수 있다. 예를 들어, AI 글쓰기 도구는 통계적으로 자주 쓰이는 단어나 문구에 의존하는 경향이 있다. 따라서 유사 단어의 반복과 가변성 부족은 생성 콘텐츠를 검출하는 단서가 된다. 또한 구조, 의미, 맥락의 다양성에서 AI 콘텐츠는 부족한 경우가 많기 때문에, 임베딩 정보를 확인하면 AI 생성 콘텐츠 여부를 좀 더 효과적으로 알아낼 수 있다.
퍼플렉시티 (Perplexity, 임의성)
퍼플렉시티는 AI 모델이 새로운 텍스트를 접했을 때, 얼마나 새로운지를 나타내는 임의성 척도이다. 텍스트와 같은 콘텐츠에서 AI가 예측하지 못한 단어 선택이 연속된다면, 이는 AI 생성 콘텐츠가 아닐 가능성이 높다. 하지만 퍼플렉시티가 높다는 것이 창의적인 언어 선택을 의미하는 것은 아니다. 경우에 따라, 맥락 없는 이해하기 어려운 불완전한 문장에서 퍼플렉시티를 높게 평가하기도 하며, 반대로 인간이 작성했지만 단조로운 글에 대해서도 AI가 생성한 콘텐츠라고 분류할 수 있기 때문에 맥락과 연결해서 판단하는 것이 필요하다.
버스티니스 (Burstiness, 임의성의 균일성)
버스티니스는 퍼플렉시티와 비슷하지만 단어 단위보다는 전체 문장에 초점을 맞춘다. 문장 구조나, 길이 및 문장의 복잡성 등 전반적인 글의 구성과 변화를 측정한다. 인간은 AI 생성 콘텐츠보다 더 역동적인 글을 구성하는 경향이 있다. 반면, AI 생성 콘텐츠는 길이가 일정하거나, 특정 단어 또는 문구를 자주 반복하는 등의 단조로움을 보인다. 그러나 의도적으로 프롬프트를 조절하며 버스티니스를 높일 수 있기 때문에 다른 지표와 종합적으로 확인 후 판단하는 것이 좋다.
 [그림 3] GPTZero 검출 기술 소개 페이지 (출처: GPTZero)
[그림 3] GPTZero 검출 기술 소개 페이지 (출처: GPTZero)
AI 표절 탐지 솔루션
AI 콘텐츠 탐지기는 인터넷에 존재하는 여러 데이터와의 유사도, 생성 콘텐츠의 언어적, 구조적 특성을 찾아내 AI의 콘텐츠 생성 여부를 확인해 주는 것을 목표로 하는 도구이다. 위에서 설명한 AI 표절과 저작권 침해 문제 해결을 목표로 TraceGPT, Winston AI, Hive, GPTZero, Inscribe와 같은 다수의 도구가 출시되었다. 플랫폼 제공자, AI 서비스 기업뿐만 아니라 학계, SEO(Search Engine Optimization), 채용 분야에서 AI 표절 여부를 판단하는 AI 콘텐츠 탐지기를 워크플로우 내에 통합해 시너지를 내고 있다. 각 도구별로 제공하는 기능과 가격 정책 등은 각각의 특색이 있기에 사용 목적에 따라 적절한 도구를 선택하는 것이 필요하다. 몇 가지 도구를 설명해 본다.
TraceGPT
리포트 탐지 여부 확인에 많이 쓰이는 TraceGPT는 텍스트를 업로드하면, 텍스트의 유사성 등을 분석하여 표절 여부를 확인할 수 있는 정보를 제공한다. 텍스트 수의 제한은 없으며, 줄 단위로 생성 콘텐츠 여부를 판단할 수 있는 수치 정보를 상세하게 보여준다. AI 생성 콘텐츠는 소스 콘텐츠와 완전히 일치하는 경우도 있지만, 문장구조나 배열 순서 등을 변경하거나 유사어로 대체하는 등 검출하기 어렵게 만들어지기도 한다. 혹은 어투 등을 변경하여 탐지기를 피해 가기 위한 시도를 하기도 한다. TraceGPT는 이러한 케이스에 대응하는 알고리즘을 지속적으로 업데이트한다.
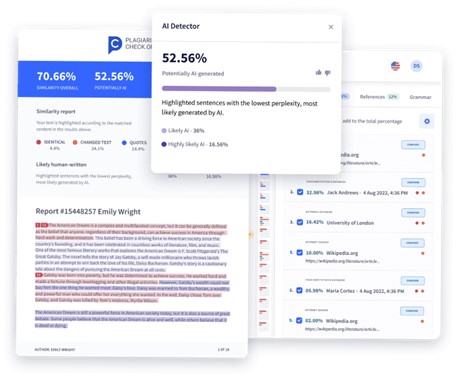 [그림 4] TraceGPT의 AI Detector 작동 화면 (출처: TraceGPT)
[그림 4] TraceGPT의 AI Detector 작동 화면 (출처: TraceGPT)
Hive
Hive는 텍스트뿐만 아니라 이미지, 비디오, 오디오에 대해서 AI 표절 여부를 검사한다. 대상 텍스트, 이미지/비디오 파일, 오디오 파일을 업로드하면, AI 생성 콘텐츠 또는 딥페이크 콘텐츠일 확률을 수치적으로 보여준다. Dall E, Stable diffusion 등 콘텐츠 생성에 사용된 도구도 예측한다.
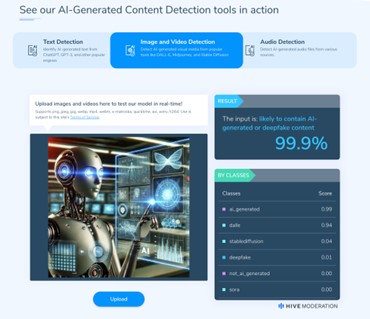 [그림 5] AI 생성 이미지를 직접 업로드한 결과 (출처: Hive Moderation)
[그림 5] AI 생성 이미지를 직접 업로드한 결과 (출처: Hive Moderation)
한편, 여러 도구별 AI 생성 콘텐츠의 예측 정확도는 균일하지는 않다. 어떤 도구는 ChatGPT, Claude, llama 등 LLM에 대해 비슷한 예측 정확도를 보이는 반면, 다른 도구는 특정 LLM에 대해서만 낮은 예측 정확도를 보이기도 한다. 여러 AI 모델이 혼합되어 생성한 콘텐츠의 경우, 전체적으로 검출 정확도는 낮게 나타난다. 모든 도구가 아직은 높은 수준의 신뢰도를 보이지 않으며 AI 생성 콘텐츠 역시 이 탐지 알고리듬을 우회하는 방법 또한 생겨날 수 있다. 따라서 AI 생성 콘텐츠 탐지기는 워크플로우 내에서 보완적으로 활용하는 것이 중요하며, 반드시 사람의 검수 및 판단 절차가 필요하다는 생각이다.
마무리
이제는 생성형 AI도구를 사용하면 누구나 글, 이미지, 음원을 손쉽게 제작할 수 있다. 생성형 AI는 분명 생산적이고 획기적인 기술이지만 누군가에게는 저작권을 침해하거나 윤리적 또는 법적 문제를 야기할 수 있다. 이제부터 더욱 빈번하게 발생하고 심각해질 것으로 예상되는 AI 생성 콘텐츠 표절은 저작권자뿐만 아니라 AI 기업, 서비스 사용자, 학계 및 언론 등 다양한 시장에 영향을 미치며 공정성, 윤리성, 정확성, 신뢰성을 저해한다. 이런 이유로 AI 생성 콘텐츠 표절 문제를 방지하기 위한 여러 도구에 대한 이해가 필요하다. 단순히 표절 여부 판별을 넘어 어떤 AI 모델에서 생성된 결과물인지를 탐지하는 도구도 새롭게 등장하고 있다. 이런 탐지기를 사용하면 생성형 AI가 작성해 준 논문인지, 이 영상에 사용된 목소리와 얼굴의 진위를 구분하는데 도움이 된다.
생성형 AI의 영향을 받는 디지털 세상에서는 모두가 데이터 사용의 합법성과 저작권 침해 방지를 인식하고 유의해야 생성형 AI의 콘텐츠 표절 문제를 지혜롭게 막아낼 수 있다. AI 기술의 발전에 맞추어 창작자의 권리를 보호하고, 지속 가능한 창작 환경 조성을 위해 반드시 필요한 부분이다.
References
[1] Verge.com, Figma pulls AI tool after criticism that it ripped off Apple’s design, Jul 2, 2024
[2] Siliconangle.com, Figma disables new AI tool that repeatedly cloned Apple’s Weather app, Jul 2, 2024
[3] AI타임스, "AI 논문 표절 심각"…수백만명이 논문 작성에 생성 AI 활용, Apr 17, 2024
[4] The New York Times, The Times Sues OpenAI and Microsoft Over A.I. Use of Copyrighted Work, Dec 27, 2023
[5] Digital Today, AI 스타트업 루마, AI로 생성한 동영상 표절 '논란', Jun 19, 2024
[6] ACS InformationAge, Has AI voice generation gone too far? Widespread AI adoption sparks concern for multiple industries., Apr 20, 2023
[7] TechCrunch, News outlets are accusing Perplexity of plagiarism and unethical web scraping, Jul 2, 2024
[8] TechCrunch, TechCrunch Minute: Reddit is taking a stand against AI crawlers, Jun 27, 2024
[9] TechCrunch, YouTube now lets you request removal of AI-generated content that simulates your face or voice, Jul 1, 2024
![]()

SAP France의 Senior Program Manager
한국에서 컴퓨터 공학을 전공 후, 7년간 한국후지쯔에서 개발자로 근무하고, 1998년 프랑스 파리로 이주하여 Business Objects에서 개발 매니저와 프로그램 매니저를 거쳐, 현재 SAP의 클라우드 ERP 엔지니어링 그룹의 시니어 프로덕트/프로그램 매니저로 근무 중입니다. 책 <프로덕트 매니지먼트>의 저자입니다.