
많은 기업이 AI 연구 및 서비스 개발을 위한 주요 컴퓨팅 리소스로 CPU를 활용해 왔습니다. 각종 연구 장비가 빠르게 발전하고 사양이 높아진 만큼, CPU도 점점 더 막강한 사양으로 무장하며 사용자들의 요구를 충족했습니다. 하지만 본격적으로 AI 시대가 도래하면서 CPU만으로는 고성능 컴퓨팅 리소스를 감당할 수 없게 되었습니다. 단순한 사무 작업에서부터 고용량의 이미지 및 고사양 영상 작업, 그리고 최근 들어 AI와 딥러닝의 발전으로 인해 컴퓨팅 리소스에 대한 요구가 폭발적으로 증가하고 있습니다. 이에 따라 기존의 CPU 중심 컴퓨팅에서 벗어나, 병렬 처리에 특화된 GPU의 중요성이 더욱 대두되고 있습니다. CPU는 복잡한 연산 처리를 잘 수행하지만, 대규모 데이터를 기반으로 한 반복적인 연산 작업에는 한계가 있습니다. 반면, GPU는 이러한 반복적인 병렬 작업에 최적화되어 있어, 딥러닝과 같은 고사양 작업에서는 필수적인 리소스로 자리 잡게 되었습니다.
 [그림 1] CPU와 GPU 비교
[그림 1] CPU와 GPU 비교
Central, Processing, Unit
Graphics, Processing, Unit
task > Order in!
최근 AI 모델의 복잡성 증가와 함께, AI와 머신러닝 분야에서는 대규모 데이터 처리와 실시간 연산이 중요한 이슈로 떠오르고 있습니다. 예를 들어, 자연어 처리 분야의 거대한 언어 모델이나 컴퓨터 비전 분야의 고해상도 이미지 처리에서는 GPU의 병렬 처리 능력이 필수적입니다. 또한, 분산 환경에서의 AI 학습도 부각되고 있어, 여러 GPU 리소스를 클러스터링하여 효율적으로 활용할 수 있는 기술의 필요성이 강조되고 있습니다.
딥러닝으로 문제를 해결할 때, 컴퓨팅 리소스는 레이어가 많아질수록 더 많은 변수를 고려하고 반복된 계산을 통해 더 정확한 답을 도출합니다. 레이어가 많아지면 많아질수록 결과는 점점 더 정확해집니다. 하지만 레이어가 많아지는 만큼 필요한 리소스는 기하급수적으로 늘어나게 됩니다. GPU의 병렬 처리가 없으면, 사실상 딥러닝은 기존 CPU만으로 연구가 불가능합니다.
 [그림 2] 레이어가 늘어남에 따라 기하급수적으로 증가하는 파라미터
[그림 2] 레이어가 늘어남에 따라 기하급수적으로 증가하는 파라미터
Input layer > hidden layer1 > hidden layer2 > hidden layer3 > Output layer
AI 연구에 필요한 GPU는 여전히 가격이 높습니다. 기업이나 학교에서 AI 연구를 위해 대량의 GPU를 구매하기에는 부담이 큽니다. 일단 구매한 GPU 리소스를 24x7 동안 단 1초도 쉬지 않고 돌리는 것도 쉽지 않습니다. 사용자가 없거나 작업을 하지 않은 때에는 GPU가 유휴 장비로 남아있게 됩니다.
이러한 경험을 바탕으로 삼성SDS 연구소는 GPU 장비들을 최대한 효율적으로 활용할 수 있도록 R&D Cloud for AI를 개발했습니다. 이는 GPU를 하나의 클러스터링으로 통합하여 관리하고 활용하는 기술입니다. GPU를 통합하면 기본적으로 전체 가용량이 늘어납니다. 사용자는 무조건 GPU를 구매하지 않아도 됩니다. 클러스터링 리소스에 분배 기술을 적용함으로써 원하는 사용자가 필요한 시점에 필요한 만큼 효과적으로 활용할 수 있습니다. 또한 AI 개발 환경을 위한 자동 세팅을 지원함으로써 개발 환경 구축에 드는 시간을 줄일 수 있습니다.
R&D Cloud for AI의 핵심 기술
R&D Cloud for AI는 GPU 리소스의 효율적인 활용을 위해 개발된 기술입니다. 여러 GPU를 클러스터링하여 하나의 통합된 컴퓨팅 리소스로 관리하고, 사용자의 요구에 따라 유연하게 리소스를 할당함으로써 리소스의 유휴 시간을 줄이고 활용도를 극대화하는 것이 핵심입니다. 즉, 여러 GPU를 묶어서 사용 가능한 리소스의 모수를 늘리고, 분리 운영할 때 발생하는 자산의 유휴 시간을 줄이는 기술입니다. R&D Cloud for AI를 서비스로 제공하기 위해서는 크게 클러스터링과 리소스의 분배, 그리고 사용자의 편의성과 확장성 강화 기술이 필요합니다. 이 기술은 GPU 클러스터링, Job 스케줄링, 그리고 분산 컴퓨팅이라는 세 가지 주요 요소로 구성됩니다. 각각의 요소는 AI 연구 개발에서 중요한 역할을 담당하며, 이를 통해 사용자는 고사양의 AI 모델을 효과적으로 훈련할 수 있습니다.
① GPU 클러스터링(GPU Clustering)
최신 AI 연구에서는 여러 GPU를 클러스터링하여 하나의 통합된 리소스로 활용하는 것이 중요합니다. 쿠버네티스(Kubernetes) 기반의 GPU 클러스터링 기술은 이러한 요구를 충족시키며, 안정적인 리소스 활용을 가능하게 합니다. 클러스터링을 통해 여러 리소스가 통합된 환경에서 다양한 AI 작업이 병렬로 수행될 수 있습니다. R&D Cloud for AI의 가장 근간이 되는 기술로서, 단지 여러 리소스를 묶어놓는 데 그치지 않고, 여러 리소스가 통합된 상태에서 안정적으로 리소스 활용을 가능하게 합니다.
 [그림 3] GPU 클러스터링 적용 전,후
[그림 3] GPU 클러스터링 적용 전,후
② 작업 스케줄링(Job Scheduling)
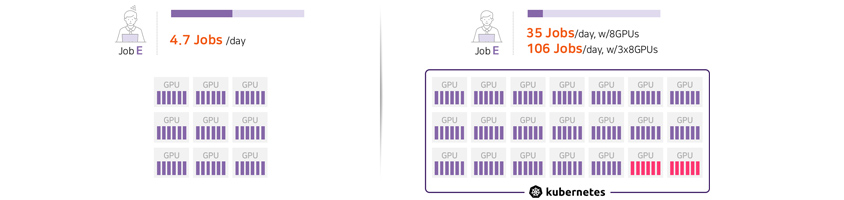
클러스터링된 GPU 리소스를 여러 사용자가 효율적으로 사용할 수 있도록, Job 스케줄링 기술이 도입됩니다. Job 스케줄링은 클러스터링된 GPU 서버에서 스스로 현재의 가용 리소스량을 판단하고, 인입되는 작업의 특성을 파악하여 어떤 순서로 작업을 배분하고 처리할지 결정합니다. 이는 각 작업의 특성에 따라 적절한 GPU 리소스를 할당하고, 최적의 순서로 작업을 처리하여 리소스 활용도를 극대화합니다. 최신 트렌드에서는 AI 모델의 자동화된 하이퍼파라미터 튜닝과 같은 작업이 증가하고 있어, 이러한 스케줄링 기술이 더욱 중요해지고 있습니다. R&D Cloud for AI는 쿠버네티스에서 제공하는 기본 스케줄러를 연구 환경에 맞게 변형하고, 필요한 방식의 Scheduler를 추가로 개발하여 적용했습니다.
 [그림 4] 작업 스케줄링 적용 효과
[그림 4] 작업 스케줄링 적용 효과
③ 분산 컴퓨팅(Distributed Computing)
현대의 복잡한 AI 모델은 단일 GPU로는 처리하기 어려운 경우가 많습니다. 특히, 수백억 개의 파라미터를 가진 대규모 모델에서는 여러 GPU를 동시에 활용하여 연산을 수행하는 분산 컴퓨팅 기술이 필수적입니다. 최신 트렌드에서는 분산 학습을 위한 데이터 병렬화와 모델 병렬화 기술이 주목받고 있으며, 이를 통해 AI 연구자는 복잡한 연산 작업을 효율적으로 수행할 수 있습니다.
Deep Neural Network(DNN) 기술이 발전하면서 점차 처리해야 할 연산이 늘어나고 있습니다. 최신의 언어 처리 모델 등은 고가의 GPU가 있어도 적절한 시간에 연산할 수 없을 정도로 복잡합니다. DNN은 복잡한 연산을 통하여 파라미터를 찾는 작업을 수행하는 것인데, 1998년에 발표된 LeNet-5는 6만 개의 파라미터를 찾지만, 2020년에 발표한 GPT-3는 1,750억 개의 파라미터를 찾습니다. 분산 컴퓨팅 기술은 GPU 한 장으로 처리할 수 없는 복잡한 연산을 여러 개의 GPU를 동시에 활용하여 처리하는 기술입니다. 실제로 GPT-3를 연구에 사용하려면 여러 개의 머신에 있는 1,000장 이상의 GPU를 동시에 쓸 수 있는 기술이 필요합니다. R&D Cloud for AI는 다양한 AI Framework에서 사용 가능한 분산 학습 기술을 도입하여 복잡한 연산을 해야 하는 연구자가 성과를 빨리 낼 수 있게 도와줄 수 있습니다.
 [그림 5] 멀티노드 GPU를 동시에 활용한 분산 학습
[그림 5] 멀티노드 GPU를 동시에 활용한 분산 학습
R&D Cloud for AI의 주요 기능
R&D Cloud for AI는 사용자가 GPU 리소스를 보다 효과적으로 활용할 수 있도록 다양한 기능을 제공합니다.
머신러닝 연구 환경의 개인화
최신 기술 동향에 따라, 연구자들이 원하는 AI 프레임워크와 라이브러리를 포함한 가상화된 컨테이너 환경이 제공됩니다. 연구자들은 이러한 환경을 빠르게 설정하여 개발에 집중할 수 있으며, 컨테이너 환경의 유연성 덕분에 여러 사용자가 동시에 다른 환경에서 작업할 수 있습니다.
머신러닝 연구와 같이 대량의 GPU를 활용하여 프로젝트를 수행해야 한다면, 당연히 필요한 사양의 GPU 장비를 구매해야 합니다. 하지만, GPU 장비를 막상 구매해도 사용자별로 환경과 패턴이 다르기 때문에 구매된 장비를 사용할 수 있는 사용자는 제한될 수밖에 없습니다. 만약 누군가 해당 GPU를 활용하여 새로운 개발을 하려 해도 필요한 환경을 구성하고 세팅하는데 어려움이 생깁니다. R&D Cloud for AI는 사용자가 원하는 환경을 가상화된 컨테이너로 제공하여 환경 세팅에 드는 시간을 줄여줍니다. 또한 클러스터링 환경의 특성을 활용하여 다른 사용자가 세팅해 놓은 환경을 재사용하거나 필요한 구성으로 변경하여 활용하는 것도 가능합니다.
 [그림 6] R&D Cloud for AI에서 제공하는 개인화 컨테이너 예시
[그림 6] R&D Cloud for AI에서 제공하는 개인화 컨테이너 예시
-
개인화 컨테이너
- tensorFlow
- Pandas
- Anaconda
-
개인화 컨테이너
- PyTorch
- Numpy
- Beautifulsoup
-
개인화 컨테이너
- tensorFlow
- Pandas
- Beautifulsoup
AI 기반 작업 스케줄링 최적화(AI Optimized Job Scheduling)
AI 연구의 특성상 다양한 Job이 동시에 처리되어야 하므로, 효율적인 스케줄링이 필수적입니다. 최신 트렌드에서는 Dynamic Resource Allocation과 Predictive Scheduling이 강조되며, 이를 통해 리소스의 활용도를 극대화하고 Job의 완료 시간을 단축할 수 있습니다.
클러스터링된 GPU가 모든 사용자와 작업을 항상 감당할 수 있다면 좋겠지만, 현실은 그렇지 않습니다. 대다수의 기업이나 학교는 항상 리소스가 모자라며, GPU를 클러스터링하여 제공한다고 해도 클러스터링된 리소스의 총량이 작업의 총량보다 부족한 경우는 당연히 발생합니다. 스케줄링 기술은 대기가 필요한 작업을 어떤 순서로 어떤 노드에서 처리할 것인지, 설정된 정책에 따라 분배하는 기술입니다.
R&D Cloud for AI는 AI 연구에 특화된 3개의 스케줄러를 보유하고 있습니다. 각각의 스케줄러는 공정성이나 작업의 특징에 따라 가장 효율적으로 처리할 수 있게 분배합니다. R&D Cloud for AI는 다양한 스케줄러를 경험한 바탕으로 개발한 AI Optimized Scheduler가 적용되어 있습니다.
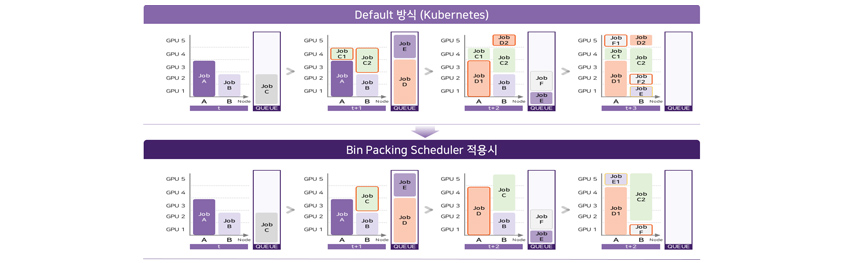 [그림 7] 쿠버네티스의 스케줄러와 R&D Cloud for AI의 Bin Packing 스케줄러 비교
[그림 7] 쿠버네티스의 스케줄러와 R&D Cloud for AI의 Bin Packing 스케줄러 비교
실시간 모니터링 및 관리 도구
연구자와 관리자는 GPU 리소스의 활용도를 실시간으로 모니터링하여 리소스 과잉 또는 부족 상황을 쉽게 파악할 수 있습니다. 최근에는 AI 기반의 예측 분석 도구가 도입되어, 리소스의 사용 패턴을 분석하고 미래의 수요를 예측하는 기능이 추가되고 있습니다.
R&D Cloud for AI는 서버별, 노드별로 사용량과 사용자를 확인할 수 있게 실시간 모니터링을 제공합니다. 서비스 제공자와 운영자는 필요 수요를 집계할 때, 코드를 뜯어보는 불필요한 작업 없이, 해당 모니터링 툴을 통해 자산들이 어느 정도 수준으로 활용하고 있는지 쉽게 확인할 수 있습니다. 모니터링 기능은 사용자들에게도 유용합니다. 작업 시, 모니터링을 통해 R&D Cloud for AI의 적절한 활용 시점을 판단할 수 있고, 실시간으로 어떤 프로젝트에서 어느 노드를 점유하고 있는지 확인할 수 있습니다. 또한 할당받은 GPU의 Core 사용률을 보여주어 학습 작업이 효율적인지 I/O 등으로 인한 성능 저하가 있는지 확인하고 개선할 수 있습니다.
또한, R&D Cloud for AI는 필요에 따라 GPU를 추가로 확보하고 클러스터링할 수 있습니다. 서비스 공급자로서 현재 클러스터링된 GPU 서버가 과잉 공급되고 있는지, 적절한지, 혹은 추가로 구비해야 하는지 결정합니다.
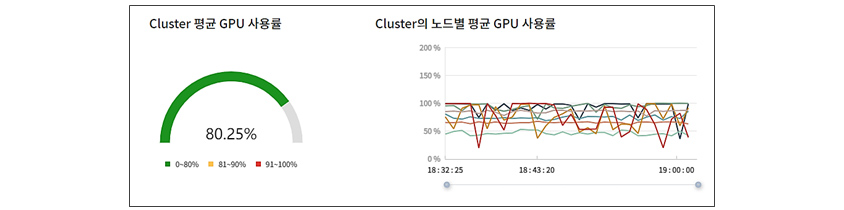 [그림 8] R&D Cloud for AI의 실시간 모니터링 화면 중 일부
[그림 8] R&D Cloud for AI의 실시간 모니터링 화면 중 일부
R&D Cloud for AI의 Use Case
삼성SDS 연구소 AI 연구 · 개발 환경 지원
삼성SDS 연구소에서 개발한 R&D Cloud for AI는 GPU 리소스의 관리와 활용을 효율화함으로써 연구자들이 AI 개발에 집중할 수 있는 환경을 제공합니다. R&D Cloud for AI는 기존의 기술들을 그대로 사용하지 않고, AI 연구 개발에 최적화된 환경을 구축했다는 점에서 차별화됩니다. 특히, AI 연구자들이 가장 필요로 하는 환경과 도구를 사전에 준비하여 즉시 활용 가능한 상태로 제공함으로써, 연구 효율성을 크게 향상할 수 있습니다. 또한, 확장성에 중점을 두어, 필요에 따라 쉽게 리소스를 확장하거나 줄일 수 있도록 설계되었습니다. AI 연구자들이 가장 많이 필요로 하는 AI 프레임워크가 적용되어 있고, 머신러닝 환경을 쉽게 셋업할 수 있도록 10종의 Environment Asset을 제공하는데, 이는 R&D Cloud for AI만의 강점입니다.
R&D Cloud for AI 구축 이전까지 삼성SDS의 연구소는 GPU 구매와 관리에 어려움을 겪었습니다. 프로젝트마다 필요한 GPU 사양과 수량에 대해 예측하여 구매하지만, 프로젝트가 종료되거나 범위가 변경될 때마다 GPU의 관리 주체가 모호해지기 때문입니다. 또한 각각 개인 좌석에서 GPU 서버를 놓고 개발하다 보니 발열과 소음 문제까지 발생했습니다.
R&D Cloud for AI 구축 이후, 자산을 물리적으로 데이터센터에 통합하여 보관, 관리할 수 있게 되었고, 프로젝트 런칭 시 자산의 구매 절차를 거칠 필요 없이 R&D Cloud for AI를 활용함으로써 곧바로 개발이 가능해졌습니다. 자산의 구매와 관리는 R&D Cloud for AI가 일괄적으로 담당하기 때문에, 연구자들은 AI 연구 자체에 집중할 수 있게 되었고, 부가적으로 환경 준비에 들이는 시간을 줄일 수 있게 되었습니다.
맺음말
삼성SDS R&D Cloud for AI는 GPU 기반의 AI 연구 환경을 구축하는 데 있어 현실적인 대안을 제시합니다. 최근 AI 및 머신러닝의 발전에 따라, 연구자들은 점차 고도화되고 복잡한 연산을 요구하는 작업을 수행해야 합니다. 이러한 작업을 지원하기 위해, R&D Cloud for AI는 클러스터링, 스케줄링, 분산 컴퓨팅 기술을 통해 리소스의 활용도를 극대화하며, 사용자가 AI 연구에만 집중할 수 있는 환경을 제공합니다. 여기에 AI 연구를 위해 제공하는 각종 기능은 서버를 구매해야 할 때, 한 번에 엄청난 양의 리소스를 구매하지 않고도 점진적으로 서버를 늘려가며 확보된 리소스를 최대한 활용할 수 있습니다. 삼성SDS R&D Cloud for AI는 단순 명료한 포인트를 개선하여 기술적인 성과를 이룩했다는 데 큰 의의가 있습니다. ‘통합 사용’이라는 단순한 개념에서 출발하여 더욱 현실적이고 효과적인 해결 방안을 찾아내고자 계속해서 기술을 확장하고 있습니다.
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에게 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의 없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
![]()

삼성SDS 연구소 클라우드연구팀, 삼성SDS 기자
삼성SDS 클라우드연구팀의 기획 담당입니다. 삼성SDS 기자를 겸하고 있습니다. R&D Cloud for AI를 비롯한 클라우드 기술을 어렵지 않게 소개합니다.
Technology Toolkit 2021에 소개한 기술에 대해 문의사항이 있으시거나, 아이디어, 개선사항 등 의견이 있으시면, techtoolkit@samsung.com으로 연락해 주세요.